

Actualizado en mayo de 2026
DeepSeek V2 es un modelo de lenguaje de IA de última generación, abierto para la comunidad (open-source), diseñado con una arquitectura Mixture-of-Experts (MoE) innovadora.
Fue presentado en 2024 como respuesta al desafío de escalar los modelos de lenguaje masivos sin sacrificar eficiencia.
Con un total de 236 mil millones de parámetros (de los cuales ~21 mil millones se activan por token), DeepSeek V2 logra un equilibrio entre tamaño y rendimiento gracias a su arquitectura dispersa.
Este modelo incorpora técnicas avanzadas para entrenamiento económico e inferencia eficiente, permitiéndole alcanzar capacidades sobresalientes de razonamiento, integración de herramientas y generación de código, todo manteniendo un despliegue viable en entornos de producción.
En su desarrollo, los creadores de DeepSeek V2 entrenaron el modelo con un corpus masivo de 8,1 billones de tokens de datos diversos y de alta calidad.
Posteriormente, aplicaron fine-tuning supervisado (SFT) y un ajuste con aprendizaje por refuerzo (mediante un enfoque llamado GRPO) para alinear el modelo con instrucciones humanas.
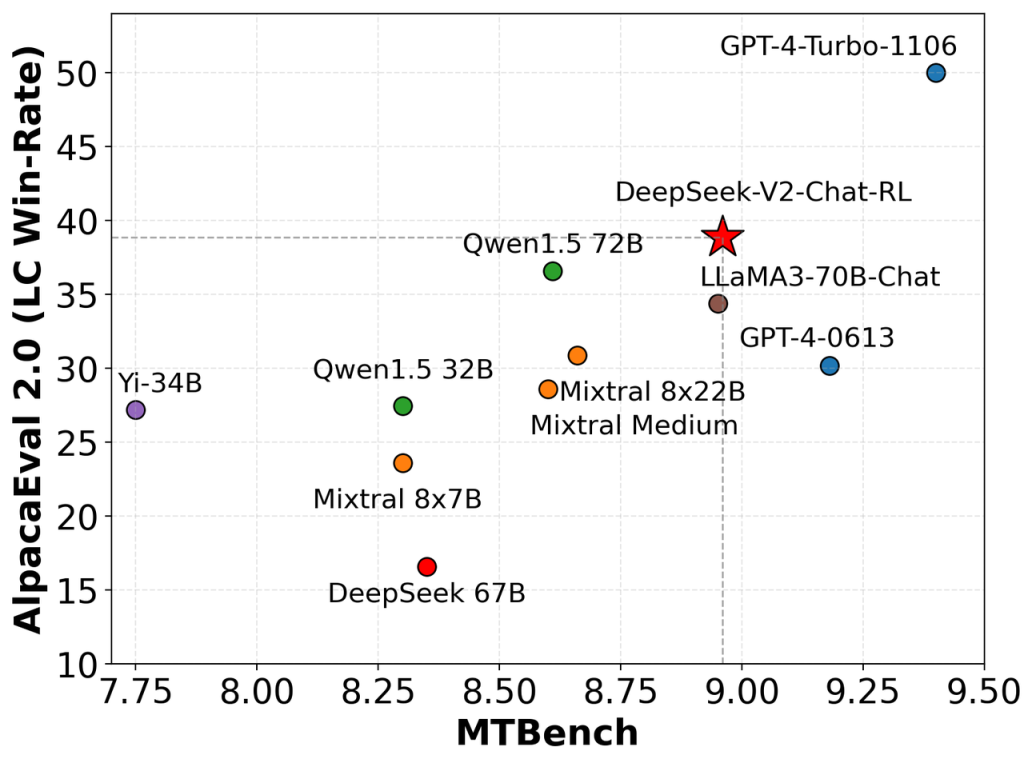
El resultado es un modelo potente y versátil, validado por su desempeño destacado en numerosos benchmarks de tareas abiertas y generación de texto.
A continuación, exploraremos en detalle la arquitectura técnica de DeepSeek V2, sus características clave y cómo los desarrolladores pueden usarlo en proyectos reales, ya sea mediante su API o ejecutándolo localmente.
Arquitectura técnica de DeepSeek V2
La arquitectura de DeepSeek V2 introduce innovaciones significativas para maximizar la escala del modelo sin incurrir en los costes típicos de cómputo asociados a los grandes modelos densos.
A continuación, se detallan sus componentes técnicos más importantes, incluyendo la estructura Mixture-of-Experts, el mecanismo de atención avanzado y diversas optimizaciones de rendimiento.
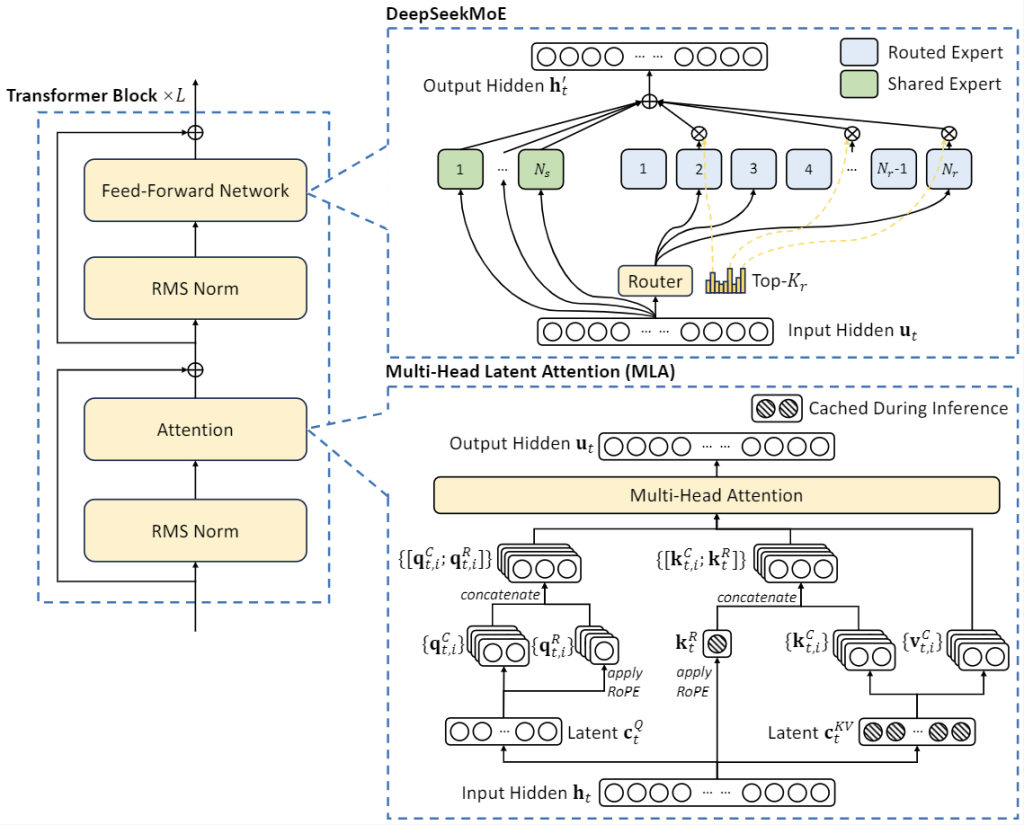
Mixture-of-Experts escalable y eficiente
El núcleo de DeepSeek V2 es su arquitectura Mixture-of-Experts (MoE), que le permite tener un número masivo de parámetros totales pero activando solo una fracción de ellos en cada inferencia.
En lugar de un solo modelo denso, DeepSeek V2 emplea múltiples expertos (submodelos especializados) y un enrutador que determina qué expertos se utilizan para cada segmento de la entrada.
De este modo, cada token de entrada solo activa alrededor del 9 % de la red (aproximadamente 21B de 236B parámetros).
Este diseño posibilita entrenar modelos más poderosos a menor coste computacional, ya que gran parte del cálculo es disperso en lugar de denso.
La arquitectura MoE de DeepSeek, denominada DeepSeekMoE, incluye mejoras de alto rendimiento que optimizan el uso de los expertos y reducen el desbalance en su utilización.
En términos prácticos, esto significa que DeepSeek V2 puede aprovechar la experiencia combinada de múltiples submodelos (por ejemplo, expertos especializados en lenguaje, código, matemáticas, etc.) sin que cada consulta deba procesar todos los parámetros a la vez.
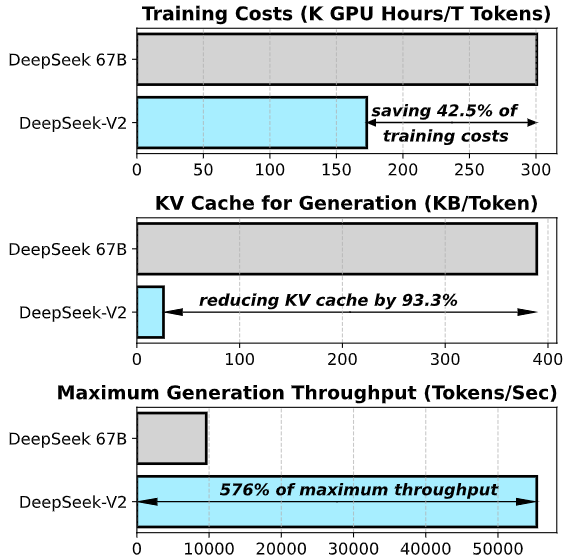
El resultado es un modelo de gran escala efectivo, capaz de exhibir capacidades emergentes de inteligencia artificial, manteniendo un coste de entrenamiento e inferencia mucho más bajo que un modelo denso equivalente (los autores reportan la necesidad de significativamente menos horas-GPU para entrenar la misma cantidad de datos, gracias al MoE).
Multi-Head Latent Attention y ventana de contexto extendida
Otro pilar técnico de DeepSeek V2 es su novedoso mecanismo de atención latente multicabezal (Multi-Head Latent Attention, MLA).
Este mecanismo aborda uno de los cuellos de botella tradicionales en modelos de lenguaje: el manejo de memorias de atención (key-value cache) muy grandes cuando el modelo procesa secuencias largas.
En la atención convencional (Multi-Head Attention), el modelo debe almacenar las claves y valores de atención de cada token previo, lo cual escala de forma cuadrática y resulta insostenible a largo plazo.
DeepSeek V2 introduce MLA, que aplica compresión conjunta de baja dimensión sobre las matrices de clave-valor, reduciendo drásticamente los requerimientos de memoria para el caché de atención. Según los autores, MLA logra reducir el tamaño del caché KV en un 93 % respecto a la atención tradicional.
Gracias a esta optimización, el modelo puede soportar una ventana de contexto extraordinariamente amplia, hasta 128.000 tokens por prompt.
En otras palabras, DeepSeek V2 puede recibir y mantener en contexto alrededor de 100.000 palabras de texto (el equivalente a una novela extensa) sin perder rendimiento ni requerir memoria prohibitiva.
Este avance abre la puerta a casos de uso como análisis de documentos largos, conversaciones prolongadas con memoria completa o búsqueda de una aguja en un pajar dentro de textos masivos (de hecho, las pruebas Needle In A Haystack demuestran que el modelo mantiene un buen desempeño incluso al máximo de 128K tokens de contexto).
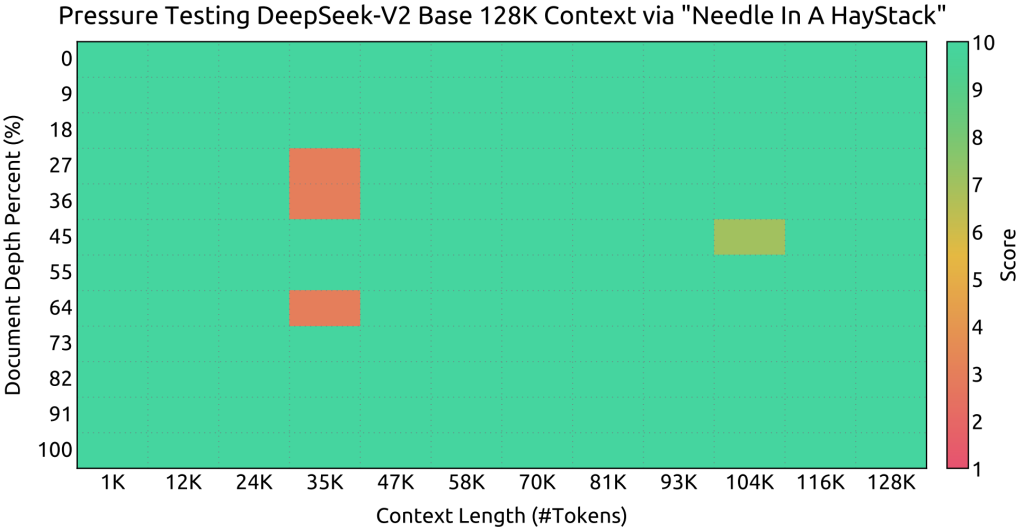
En resumen, la combinación de MLA y la gran capacidad de parámetros permite a DeepSeek V2 «recordar» y razonar sobre contextos mucho más largos que la mayoría de modelos previos, todo ello con inferencia optimizada.
Optimización de comunicaciones y eficiencia de cómputo
Escalar un modelo MoE a cientos de miles de millones de parámetros conlleva desafíos en entornos de múltiples GPUs.
DeepSeek V2 incorpora varias optimizaciones de comunicación y cómputo para garantizar que su gran tamaño no se traduzca en ineficiencias:
- Enrutamiento limitado por dispositivo y balanceo de carga: El diseño de DeepSeek V2 incluye un esquema de enrutamiento de expertos consciente de la topología de hardware (p. ej., cuántos expertos residen en cada GPU) para minimizar la transferencia de datos entre dispositivos. Además, se introdujeron pérdidas de balanceo durante el entrenamiento para asegurar que todos los expertos sean utilizados equitativamente, evitando que unos pocos se saturen mientras otros quedan subutilizados. Esto mejora la utilización del modelo y la estabilidad del entrenamiento en MoE.
- Kernels CUDA personalizados y FlashAttention optimizado: El equipo de DeepSeek implementó kernels CUDA a medida para operaciones críticas de la arquitectura MoE, como la comunicación entre GPUs, los algoritmos de enrutamiento y las operaciones lineales fusionadas a través de diferentes expertos. Igualmente, el mecanismo de atención MLA se construyó sobre una versión mejorada de FlashAttention-2, una técnica de optimización de atención que reduce cálculos redundantes y operaciones de memoria. Estas optimizaciones a bajo nivel permiten exprimir al máximo el hardware disponible, aumentando la tasa de FLOPs útiles (medida como Model FLOPs Utilization, MFU) y eliminando cuellos de botella de comunicación.
- Precisión numérica mixta y caching eficiente: Para acelerar la inferencia sin perder mucha precisión, DeepSeek V2 aprovecha representaciones numéricas optimizadas. En inferencia utiliza peso en formato BF16/FP8 (16 bits de precisión de brain floating o incluso 8 bits en algunas etapas) junto con cuantización del caché KV (en promedio a 6 bits de precisión efectiva). Esto reduce dramáticamente los requisitos de memoria y permite lotes de inferencia más grandes, incrementando el rendimiento. Por ejemplo, en sus pruebas, DeepSeek V2 logró generar más de 50.000 tokens por segundo en una sola máquina con 8 GPUs H800, y procesar entradas (prompt) a más de 100.000 tokens/segundo, cifras que ilustran su elevada eficiencia. Estos niveles de rendimiento representan un salto notable frente a las arquitecturas densas tradicionales, habilitando aplicaciones de alto tráfico con menor latencia.
En conjunto, la arquitectura de DeepSeek V2 se resume en varias innovaciones técnicas clave: una arquitectura MoE eficiente (uso disperso de parámetros), un mecanismo de atención latente que soporta una ventana de contexto masiva optimizando la memoria, y mejoras de computación distribuida (balanceo, kernels especializados, cuantización) que resultan en un modelo más rápido y económico de ejecutar de lo que su escala bruta sugeriría.
Estas características permiten a DeepSeek V2 ofrecer a los desarrolladores un modelo de lenguaje de alto desempeño sin depender exclusivamente de infraestructuras de cómputo extremas.
Capacidades clave de DeepSeek V2
Gracias a su arquitectura y entrenamiento a gran escala, DeepSeek V2 exhibe una serie de capacidades avanzadas que lo hacen muy atractivo para desarrolladores, ingenieros de software y arquitectos de IA que buscan integrar un modelo de lenguaje potente en sus proyectos:
- Modelo de lenguaje de código abierto: DeepSeek V2 se distribuye bajo un esquema de licencia abierta que permite su uso comercial sin restricciones excesivas. Esto significa que las empresas y desarrolladores pueden desplegarlo o afinarlo en sus propios entornos sin incurrir en costes de licencia, a diferencia de muchos modelos cerrados. El código fuente y los pesos del modelo base y variantes chat están disponibles públicamente (por ejemplo, en Hugging Face), promoviendo la transparencia y la colaboración de la comunidad. Ser un modelo open-source también facilita la inspección de su arquitectura y el desarrollo de mejoras o adaptaciones específicas.
- Razonamiento y comprensión profundos: DeepSeek V2 alcanza rendimiento de punta en tareas de razonamiento y conocimientos generales. En evaluaciones estándar como MMLU (conocimiento académico en inglés) y CMMLU (versión en chino), el modelo obtuvo puntuaciones elevadas (~78,5 y ~84,0, respectivamente), demostrando su capacidad para comprender y razonar sobre una amplia gama de temas tanto en inglés como en chino. Su extenso preentrenamiento y el afinamiento con datos conversacionales de matemáticas, lógica y otros dominios le han conferido la habilidad de seguir cadenas de pensamiento multipaso y resolver problemas complejos. Para los desarrolladores, esto se traduce en que DeepSeek V2 puede alimentar asistentes virtuales o agentes que necesiten pensar respuestas (no solo buscar texto coincidente), permitiendo soluciones en ámbitos como soporte técnico, análisis de datos o resolución de problemas científicos.
- Ventana de contexto masiva (128K tokens): Como se detalló, la arquitectura MLA de DeepSeek V2 le permite manejar contextos de hasta 128 mil tokens. En la práctica, esta ventana de contexto extendida habilita casos de uso únicos: se pueden introducir documentos enteros, conjuntos de datos o largos historiales de chat como contexto para que el modelo los tenga en cuenta. Por ejemplo, un desarrollador podría proporcionar logs extensos, contratos legales completos o varios capítulos de un manual en una sola consulta, y DeepSeek V2 es capaz de referirse a información específica que puede estar «enterrada» miles de oraciones atrás. Esta capacidad de memoria de largo alcance distingue a DeepSeek V2 de la mayoría de modelos existentes y es especialmente útil en aplicaciones de resumen de documentos largos, análisis de conversaciones históricas o búsqueda semántica en grandes archivos de texto.
- Generación de código y soporte para desarrolladores: DeepSeek V2 ha demostrado un desempeño sobresaliente en tareas de generación de código fuente, convirtiéndolo en un valioso asistente de programación. Tras su afinamiento, la versión conversacional del modelo (DeepSeek V2 Chat) logró aproximadamente 81 % de acierto en el benchmark HumanEval (evaluación de generación de funciones de programación), una puntuación muy competitiva a nivel de los mejores modelos especializados. Esto implica que el modelo puede escribir código funcional en múltiples lenguajes a partir de descripciones en lenguaje natural, depurar fragmentos de código o completar implementaciones a medias. De hecho, los desarrolladores de DeepSeek lanzaron posteriormente una variante enfocada exclusivamente en tareas de código (DeepSeek-Coder), construida sobre V2, que amplía el soporte a más de 300 lenguajes de programación y refuerza sus capacidades de razonamiento matemático. Con DeepSeek V2, un ingeniero de software puede aprovechar la generación automática de código para acelerar el desarrollo (como un compañero tipo pair programming), obtener sugerencias de algoritmos, traducir código entre lenguajes o generar documentación en base al código fuente.
- Integración de herramientas externas (Tool Integration): Una de las características más interesantes de DeepSeek V2 para arquitectos de soluciones de IA es su capacidad de integrarse con herramientas y APIs externas mediante prompts especializados. En su plataforma API, DeepSeek V2 soporta el concepto de Function Calling, similar al introducido por OpenAI, que permite al modelo «invocar» funciones definidas por el desarrollador. Esto significa que durante una conversación, el modelo puede decidir que necesita usar una herramienta (por ejemplo, una calculadora, un servicio de búsqueda, una consulta a base de datos) y produce una respuesta estructurada que indica una llamada a función con parámetros. El sistema externo puede interceptar esa llamada, ejecutar la función real y devolver el resultado al modelo, el cual continúa la conversación usando la nueva información. Por ejemplo, si el usuario pregunta «¿Cuál es la temperatura actual en Madrid?», DeepSeek V2 puede generar una salida indicando que desea llamar a una función
get_weather(location="Madrid"). La aplicación del desarrollador ejecutaría la función real (que podría llamar a una API meteorológica) y alimentaría la respuesta (p. ej., «20°C») de vuelta al modelo, que entonces respondería al usuario con la información del clima. Todo este flujo ocurre de forma controlada: el modelo no ejecuta directamente código externo, sino que sugiere acciones que el desarrollador puede moderar. Esta integración de herramientas abre posibilidades de crear agentes de IA aumentados, combinando la inteligencia lingüística de DeepSeek V2 con las capacidades especializadas de servicios externos (calculadoras, buscadores, sistemas de domótica, etc.), brindando soluciones mucho más interactivas y útiles. Además, dado que la API de DeepSeek es compatible con la de OpenAI, también es posible aprovechar ecosistemas existentes como LangChain para orquestar estas interacciones de manera sencilla.
En resumen, DeepSeek V2 no solo aporta mejoras en métricas tradicionales de lenguaje, sino que ofrece un conjunto de funcionalidades prácticas: amplio contexto, alto razonamiento, generación de código sólida y extensibilidad mediante herramientas.
Estas capacidades lo hacen especialmente atractivo para proyectos de asistentes virtuales avanzados, plataformas de desarrollo asistido por IA, análisis de datos a gran escala, entre otros.
En la siguiente sección veremos cómo los desarrolladores pueden acceder y utilizar concretamente DeepSeek V2, ya sea consumiendo su API en la nube o ejecutando el modelo localmente.
Uso de DeepSeek V2 en proyectos reales
DeepSeek V2 puede emplearse en entornos de producción de dos formas principales: mediante su API hospedada (servicio web) provista por sus creadores, o mediante la implementación local del modelo descargando los pesos open-source.
A continuación, describimos ambos métodos y proporcionamos ejemplos prácticos para desarrolladores.
Uso mediante API (servicio compatible con OpenAI)
Los desarrolladores que deseen integrar DeepSeek V2 rápidamente en sus aplicaciones pueden hacer uso de la API en la nube de DeepSeek.
Esta plataforma ofrece una API compatible con el estándar de OpenAI (OpenAI-like), lo que significa que la forma de invocar el modelo es prácticamente idéntica a la de servicios como GPT-3/GPT-4. De hecho, es posible utilizar los SDKs oficiales de OpenAI simplemente apuntándolos al endpoint de DeepSeek tras obtener una clave de API.
Características de la API DeepSeek:
- Endpoint y autenticación: El endpoint base es
https://api.deepseek.com(con alternativahttps://api.deepseek.com/v1por compatibilidad). La autenticación se realiza mediante API keys que se pueden obtener registrándose en la plataforma (DeepSeek ofrece un nivel gratuito de millones de tokens de prueba al registrarse). La petición se realiza vía HTTP con cabeceraAuthorization: Bearer <API_KEY>. - Formato de peticiones: La API acepta solicitudes POST en formato JSON similares a la API de ChatGPT. Por ejemplo, para generar una respuesta de chat, se usa la ruta
/chat/completionscon un JSON que incluye el modelo a usar (p. ej."model": "deepseek-chat"para la versión afinada conversacional de V2) y una lista de mensajes con roles"system","user","assistant", etc. Opcionalmente se pueden enviar parámetros comomax_tokens,temperature,stream, funciones disponibles (tools), etc., siguiendo el mismo esquema que la API de OpenAI. - Ejemplo de llamada API: A continuación, un ejemplo simplificado utilizando curl para solicitar una finalización de chat con DeepSeek V2:
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer DEEPSEEK_API_KEY_AQUI" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "Eres un asistente de IA útil."},
{"role": "user", "content": "Hola DeepSeek, \u00bfpuedes presentarte?"}
]
}'
En este ejemplo, enviamos un mensaje de usuario y un mensaje de sistema para contexto. La respuesta de la API será un JSON con la elección del modelo (bajo "choices"), incluyendo el contenido generado por el asistente.
Dado que el servicio soporta tanto modo no conversacional (completado de texto simple) como modo chat, se pueden especificar modelos distintos según el caso ("deepseek" vs "deepseek-chat", por ejemplo).
Nota: deepseek-chat y deepseek-reasoner son identificadores heredados. Durante la transición apuntan a DeepSeek V4 Flash en modo rápido y razonado, respectivamente. La documentación oficial indica su deprecación el 24 de julio de 2026, por lo que conviene migrar a los identificadores vigentes V4 Flash y V4 Pro.
La API también permite respuestas en streaming (similar a ChatGPT streaming), lo cual es útil para mostrar resultados en tiempo real a los usuarios finales configurando "stream": true en la solicitud.
- Integración con SDKs y herramientas: Por su compatibilidad, se puede usar la librería oficial
openaien Python simplemente cambiando elbase_urly laapi_key. Por ejemplo:
import openai
openai.api_key = "TU_API_KEY"
openai.api_base = "https://api.deepseek.com/v1"
respuesta = openai.ChatCompletion.create(
model="deepseek-chat",
messages=[{"role": "user", "content": "Dame un consejo de programación en Python"}]
)
print(respuesta.choices[0].message.content)
Del mismo modo, marcos como LangChain pueden aprovecharse fácilmente. Dado que DeepSeek V2 imita la interfaz de OpenAI, se puede instanciar un ChatOpenAI en LangChain apuntando al endpoint de DeepSeek para crear agentes conversacionales, cadenas de LLMs, etc., sin cambios mayores en el código.
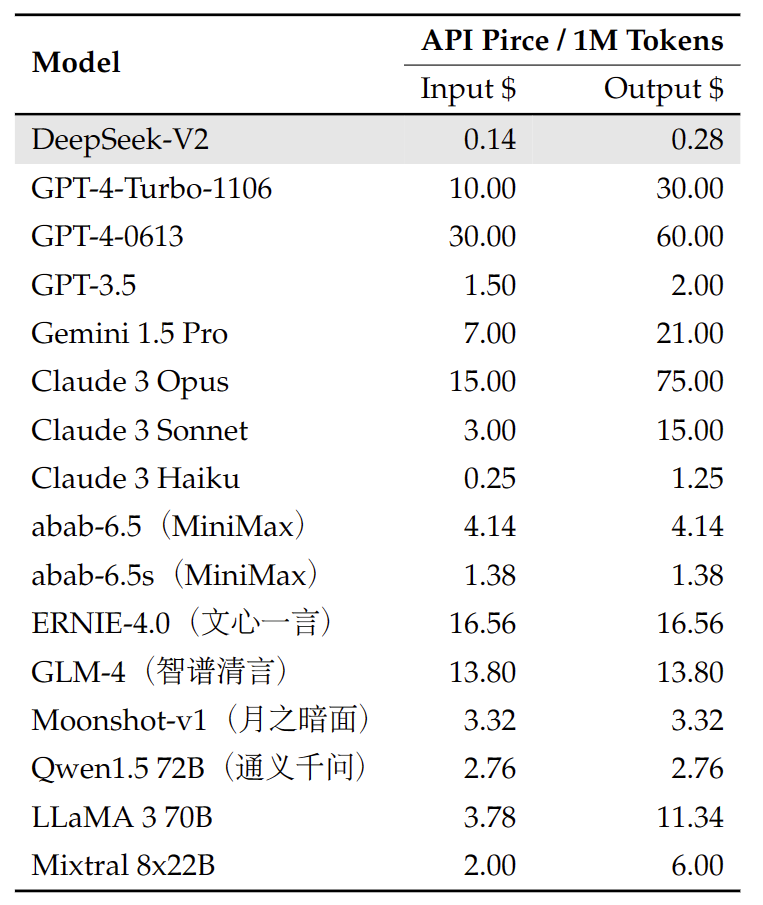
- Costes y rendimiento: La política de precios de DeepSeek (al momento de escribir) es competitiva, con facturación por millón de tokens que tiende a ser más económica que alternativas comerciales equivalentes. Además, el equipo reporta una velocidad de respuesta muy alta gracias a las optimizaciones de inferencia del modelo (aproximadamente 60 tokens/segundo en la versión V2, según notas de lanzamientos posteriores). La infraestructura detrás de la API también introduce funciones avanzadas como context caching (caché de contexto), que permite reutilizar partes de la conversación para reducir costes en sesiones largas, y modos especializados de razonamiento (thinking mode) que podrían dar paso a respuestas con chain-of-thought más elaboradas en el futuro. En general, para un desarrollador que busque incorporar un modelo estilo ChatGPT de código abierto en su aplicación, la API de DeepSeek V2 ofrece una ruta inmediata, escalable (en la nube) y con mínimos cambios de integración si ya está familiarizado con las APIs de OpenAI.
Uso local y despliegue autohospedado
Para proyectos que requieran un control total del modelo o entornos con restricciones (por ejemplo, datos sensibles que no pueden salir de la empresa), DeepSeek V2 también está disponible para descarga y ejecución local.
Al ser open-source, los pesos del modelo se pueden obtener de repositorios como Hugging Face, aunque es importante considerar los requisitos de hardware dado el tamaño del modelo.
Variantes disponibles: Los autores han publicado dos tamaños de DeepSeek V2:
- DeepSeek-V2 (completo): 236B parámetros totales, 21B activos, con ventana de contexto de 128K tokens. Este es el modelo completo descrito anteriormente. Debido a su magnitud, ejecutar esta versión requiere hardware de muy alta gama, típicamente un clúster de GPUs. Se recomienda disponer de 8 GPUs de 80 GB cada una (por ejemplo, NVIDIA A100 80 GB) para cargar el modelo en formato de 16 bits. Con técnicas de particionado de modelos (model parallelism) se pueden usar múltiples GPUs para distribuir la carga. No es viable cargar 236B parámetros en una sola GPU actual. Sin embargo, es posible realizar inferencia en esta versión completa usando frameworks optimizados como vLLM o DeepSpeed, que pueden hacer streaming de pesos desde CPU o disco bajo demanda. En entornos de investigación, también se ha experimentado con la cuantización a 4/8 bits para reducir el consumo de VRAM a costa de algo de precisión.
- DeepSeek-V2-Lite: 16B parámetros totales, 2,4B activos, con ventana de contexto de 32K tokens. Esta variante más pequeña fue open-source para facilitar la experimentación y uso local con recursos más modestos. DeepSeek V2 Lite ofrece la misma arquitectura (MLA + MoE) a menor escala. Se puede desplegar en una sola GPU de 40 GB (por ejemplo, un A100 40 GB o RTX 6000 Ada) manteniendo inferencia en tiempo real. Incluso podría ejecutarse en GPUs de ~24 GB con alguna optimización (por ejemplo, cargando en int8 o usando CPU offloading). Aunque su rendimiento es inferior al modelo completo, V2-Lite supera a modelos densos de tamaño comparable (entre 7B y 16B) en muchos benchmarks, gracias a que conserva las ventajas de la atención eficiente y los expertos especializados. Para muchos casos de uso internos o de menor escala, esta versión lite puede ser la opción ideal por su equilibrio entre capacidad y coste computacional.
Carga del modelo y ejemplo de inferencia: La forma más directa de usar DeepSeek V2 localmente es a través de la biblioteca Hugging Face Transformers.
Los pesos están publicados bajo las cuentas oficiales deepseek-ai. A continuación, se muestra un ejemplo en Python de cómo cargar la variante Lite afinada para instrucciones (chat SFT) y generar una respuesta de texto.
Este ejemplo asume que se dispone de al menos una GPU con suficiente VRAM:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
modelo = "deepseek-ai/DeepSeek-V2-Lite-Chat" # Modelo de DeepSeek V2 Lite afinado para chat/instrucciones
tokenizer = AutoTokenizer.from_pretrained(modelo, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
modelo, torch_dtype=torch.bfloat16
)
model.to("cuda") # mover el modelo a GPU
# Prompt de ejemplo: pedir generación de código
prompt = (
"Usuario: Escribe un programa sencillo en Python que imprima los n\u00fameros del 1 al 5.\n"
"Asistente:"
)
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=50)
respuesta = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(respuesta)
En este script, se utiliza DeepSeek-V2-Lite-Chat, que es el modelo de 16B ya afinado con instrucciones (lo que facilita que responda siguiendo indicaciones como un asistente).
Usamos trust_remote_code=True porque DeepSeek V2 emplea algunas implementaciones personalizadas de la arquitectura MoE/MLA que Hugging Face necesita cargar dinámicamente.
Convertimos el modelo a tipo bfloat16 para reducir a la mitad la memoria usada respecto a FP32, y lo movemos a la GPU. Tras tokenizar un prompt donde el usuario pide un programa en Python, generamos hasta 50 tokens nuevos.
El resultado (respuesta) debería ser un código Python formateado, por ejemplo, una función o un bucle for que imprime del 1 al 5, seguido posiblemente de alguna explicación si el modelo lo incluye en su respuesta.
Nota: La primera vez que se carga el modelo, puede tardar varios minutos en descargar los pesos (por su tamaño). Asegúrese de tener configurado correctamente el almacenamiento de temporales de Hugging Face. Asimismo, para la variante completa de 236B, habría que adaptar el código usando parámetros
device_mapymax_memorypara repartir el modelo en múltiples GPUs (tal como indican los ejemplos oficiales). Alternativamente, se recomienda usar el motor de inferencia vLLM optimizado, que soporta de forma más eficiente modelos con ventanas de contexto largas y capas MoE.
Una vez cargado localmente, puede interactuarse con el modelo de manera similar a cualquier LLM: proporcionando prompts de texto.
Es posible afinar (fine-tune) el modelo en datos propios si se cuenta con los recursos —por ejemplo, usando técnicas de Low-Rank Adaptation (LoRA) sobre la variante Lite para especializarlo en un dominio concreto, lo cual según la documentación de NVIDIA NeMo es factible con 8 GPUs de 80 GB para la versión Lite.
La librería NeMo de NVIDIA provee recetas de entrenamiento y ajuste para DeepSeek V2, incluyendo scripts para SFT y RLHF, lo que permite a equipos de IA incorporar instrucciones específicas de su negocio al modelo.
Integración en aplicaciones locales: Un modelo autohospedado de DeepSeek V2 puede integrarse en aplicaciones de diversas maneras.
Por ejemplo, se puede montar un servidor HTTP local (usando frameworks como FastAPI o Flask) que cargue el modelo y exponga un endpoint similar al de la API para uso interno.
También se puede emplear LangChain en modo local, configurando el objeto LLM para que apunte al modelo cargado (vía HuggingFaceHub o directamente con HuggingFacePipeline).
De esta forma, se podrían crear chatbots locales, agentes con herramientas (definiendo funciones Python que el agente puede llamar, combinadas con la capacidad de Function Calling mencionada), o integraciones en interfaces existentes (por ejemplo, un plugin en VS Code que utilice DeepSeek V2 para autocompletado y explicación de código, corriendo todo en la máquina del desarrollador).
En cuanto a consideraciones de rendimiento, es importante ajustar los parámetros de generación y batching según el hardware. DeepSeek V2 Lite con 16B activos puede generar texto en tiempos razonables en una GPU moderna (unos pocos tokens por segundo en una sola A100 40 GB, aumentando si se usan varias).
La versión completa es más adecuada para inferencia en servidor robusto o en entornos distribuidos (p. ej., 8x GPUs); pero para muchos propósitos de desarrollo y prueba, la versión Lite ofrece un entorno representativo de las capacidades principales del modelo.
Ejemplos de aplicaciones prácticas
A continuación, enumeramos algunos casos de uso prácticos donde DeepSeek V2 puede aportar valor, especialmente considerando a su público objetivo de desarrolladores y arquitectos técnicos:
Asistente de programación y DevOps: Aprovechando la fuerte capacidad de generación de código de DeepSeek V2, se puede integrar como asistente en entornos de desarrollo. Por ejemplo, un desarrollador puede preguntarle cómo implementar una función determinada, traducir código de un lenguaje a otro, o incluso generar scripts de configuración. En tareas de DevOps, podría analizar archivos de log extensos (gracias a su ventana de 128K tokens) y resumir errores o patrones. Un caso concreto: integrar DeepSeek V2 en un IDE para autocompletar código o sugerir correcciones, similar a herramientas como Copilot, pero desplegado localmente con control total de los datos.
Análisis de documentos largos y búsqueda semántica: Organizaciones que manejan documentos voluminosos (manuales técnicos, reportes financieros, documentación legal) pueden usar DeepSeek V2 para extraer información puntual de textos muy extensos. Por ejemplo, se le podría proporcionar todo el texto de un informe anual y luego hacer preguntas como «¿Cuál fue el ingreso neto en 2023?» y el modelo encontrará la respuesta en el contexto. De igual forma, puede resumir capítulos enteros manteniendo los detalles clave. Su ventaja de contexto masivo elimina la necesidad de fragmentar documentos en trozos pequeños, permitiendo análisis más globales y QA semántico a gran escala en bases de conocimiento.
Chatbots conversacionales con memoria a largo plazo: En aplicaciones de atención al cliente o asistentes personales, DeepSeek V2 puede mantener el hilo de conversaciones muy largas, recordando detalles mencionados decenas de interacciones atrás. Esto permite crear chatbots más coherentes y contextualmente conscientes. Por ejemplo, un asistente médico virtual podría recordar los síntomas que el usuario mencionó al inicio de una sesión extensa, o un tutor virtual podría referirse a partes anteriores de una lección sin necesidad de que el usuario repita información. Todo ello mejora significativamente la experiencia del usuario con respecto a modelos con memoria más limitada.
Agentes de IA con herramientas y automatización: Gracias a la integración de herramientas (tool use), se pueden construir agentes que no solo conversan sino que toman acciones. Un ejemplo práctico es un asistente de viajes que, tras conversar con el usuario sobre preferencias, use function calling para consultar precios de vuelos u hoteles en tiempo real y luego presente las opciones. Otro ejemplo es un agente de monitoreo de sistemas que, ante una consulta sobre el estado de un servidor, llame a una API interna para obtener métricas y responda con un diagnóstico. DeepSeek V2 sirve como cerebro lingüístico, entendiendo la solicitud y decidiendo qué herramienta invocar, mientras que la lógica de cada herramienta la implementa el desarrollador. Esto habilita flujos de trabajo automatizados complejos manejados mediante lenguaje natural.
Investigación y desarrollo en IA: Siendo un modelo de código abierto y puntero en su técnica, DeepSeek V2 también es valioso para investigadores y arquitectos de IA que quieran experimentar con arquitecturas MoE de gran escala. Se puede usar la variante Lite para probar nuevas estrategias de enrutamiento de expertos, técnicas de compresión de atención o evaluaciones de eficiencia. Asimismo, dado que soporta un amplio contexto, es una plataforma para explorar prompting avanzado, in-context learning en largos documentos o métodos de fine-tuning en escenarios de secuencia larga. La comunidad puede aprovechar DeepSeek V2 como base para iterar sobre mejoras y quizás inspirar futuras arquitecturas híbridas eficientes.
Conclusión
DeepSeek V2 representa un avance significativo en modelos de lenguaje de gran escala orientados a la eficiencia y a casos de uso prácticos en la industria.
Su arquitectura Mixture-of-Experts combinada con técnicas como Multi-Head Latent Attention demuestra que es posible escalar modelos a cientos de miles de millones de parámetros de forma económica, obteniendo lo mejor de dos mundos: alto rendimiento en tareas complejas (razonamiento, codificación, multitarea) y viabilidad de despliegue gracias a la optimización computacional.
Para desarrolladores y profesionales del software, DeepSeek V2 ofrece tanto la flexibilidad de un modelo open-source (personalización, despliegue local, transparencia) como la comodidad de un servicio listo para usar vía API en la nube, con compatibilidad estándar y costes competitivos.
En proyectos reales, este modelo puede ser el motor de asistentes de IA inteligentes que requieran manejar grandes contextos (desde documentación completa hasta largas conversaciones), puede acelerar el desarrollo de software generando y revisando código, y puede integrarse como componente central de agentes autónomos que combinen lenguaje natural con acciones automatizadas.
Todo ello con un tono profesional y controlable, adecuado para entornos empresariales y aplicaciones de siguiente nivel.
En definitiva, DeepSeek V2 se posiciona como una herramienta potente y versátil para la comunidad de desarrollo, marcando un paso adelante hacia sistemas de IA más escalables, integrados y capaces.
Con su documentación detallada, comunidad creciente y continuo avance (pues sienta las bases para versiones futuras aún más eficientes), DeepSeek V2 es una opción muy atractiva para quienes buscan incorporar un modelo de lenguaje moderno en sus soluciones tecnológicas.
Vale la pena explorar sus capacidades, ya sea a través de la API con unos pocos clics o descargando el modelo para descubrir de primera mano cómo esta arquitectura MoE puede impulsar la próxima generación de aplicaciones inteligentes.
Migración a DeepSeek V4
Si llegaste a esta página buscando información sobre la API actual, considera migrar a DeepSeek V4. La nueva generación amplía el contexto a 1M tokens, ofrece tres modos de razonamiento y reduce el coste por token. Para los pasos concretos consulta la guía de migración V3.2 → V4.