

DeepSeek V3.2-Exp es un modelo de lenguaje de última generación enfocado en eficiencia y escala, dirigido a desarrolladores e investigadores.
Se trata de un LLM (Large Language Model) de arquitectura avanzada, que combina un diseño Mixture-of-Experts (Mezcla de Expertos, MoE) masivo con mecanismos de atención dispersa para manejar contextos extremadamente largos.
A continuación, exploramos en detalle su arquitectura técnica, enfatizando su escala, estructura interna y capacidades orientadas a un uso profesional.
Escala masiva y diseño Mixture-of-Experts (MoE)
A nivel de escala, DeepSeek V3.2-Exp se basa en una arquitectura MoE con 671 mil millones de parámetros totales, de los cuales aproximadamente 37 mil millones de parámetros se activan por token durante la inferencia.
Esta enorme capacidad se logra reemplazando las capas feed-forward tradicionales del transformador con capas Mixture-of-Experts: en concreto, casi todas las capas del transformador (excepto las primeras 3) usan MoE en lugar de un MLP denso.
El modelo cuenta con 61 capas en total, con una dimensión oculta de 7168 en el transformador, distribuidas en 128 cabezas de atención por capa.
Para mejorar la eficiencia de la atención en contextos largos, emplea un mecanismo de Multi-Head Latent Attention (MLA) que comprime las representaciones de clave/valor a 512 dimensiones (y de consulta a 1536) antes de aplicar la atención, reduciendo la carga computacional sin sacrificar desempeño.
En cada capa MoE, el diseño es impresionante: 256 expertos “ruteados” (especializados) más 1 experto compartido conviven en paralelo.
Cada experto es esencialmente una red feed-forward propia con una dimensión interna de 2048, mucho más pequeña que la capacidad combinada de la capa (de hecho, la dimensión efectiva del MLP si todos los expertos se usaran sería enorme).
Sin embargo, a la hora de procesar un token dado, solo se activan 8 expertos de esos 256 mediante un mecanismo de gating que elige los más relevantes (Top-8).
Es decir, cada token entrante calcula puntuaciones de pertinencia para todos los expertos y luego se enruta únicamente a los 8 mejores, que procesan el token en paralelo.
Los resultados de esos expertos activos se combinan (por ejemplo, mediante suma ponderada por las puntuaciones) para producir la salida de la capa.
Este enrutamiento dinámico limita el cómputo por token, manteniendo la capacidad efectiva en ~37B parámetros en vez de los 671B totales.
Además, para escalar a entornos distribuidos, el sistema de gating aplica una restricción de nodo: cada token enviado a sus 8 expertos no tocará más de 4 nodos distintos, lo que reduce la comunicación entre máquinas.
En resumen, la arquitectura MoE de DeepSeek V3.2-Exp le permite tener un orden de magnitud más parámetros totales que un modelo denso tradicional, sin que la inferencia por token resulte prohibitiva, gracias a que solo una fracción de expertos se evalúa por cada entrada.
Atención dispersa para contexto extendido
Una de las innovaciones clave de V3.2-Exp es su capacidad de manejar contextos extremadamente largos (hasta 128 mil tokens de longitud de ventana de contexto) de forma eficiente.
Para lograrlo, introduce un mecanismo de atención dispersa denominado DeepSeek Sparse Attention (DSA), que opera en dos etapas»
- Indexador rápido (“Lightning Indexer”) – En esta primera fase, el modelo recorre rápidamente todo el texto de entrada para identificar segmentos relevantes dentro del contexto completo. Este indexador actúa como un filtro ligero que evalúa qué partes del contexto (por ejemplo, oraciones o párrafos) podrían ser más importantes para la tarea actual. Es un proceso de atención gruesa o preselección que, mediante técnicas especializadas, explora la ventana entera de contexto con un costo computacional reducido.
- Selección fina de tokens críticos – Una vez marcados los fragmentos relevantes, la segunda etapa aplica una atención más granular dentro de esos segmentos. El modelo extrae los tokens más importantes de los fragmentos preseleccionados, limitando el conjunto final de tokens que se pasarán a la atención completa (densa) del transformador. En esencia, de un contexto potencialmente gigante, solo una porción reducida de tokens “clave” avanzan a la atención detallada en cada capa.
Este enfoque jerárquico de atención restringe drásticamente la cantidad de información que cada capa del transformador realmente procesa, sin perder de vista el contenido relevante.
Gracias a DSA, el modelo puede ignorar en cada paso tokens que probablemente no aporten información útil inmediata, enfocando el cómputo solo en las partes más significativas del contexto.
Las evaluaciones iniciales muestran que esta técnica mantiene la calidad de las respuestas a la par del modelo denso previo (DeepSeek V3.1), al tiempo que reduce aproximadamente un 50% el costo computacional en consultas de contexto largo.
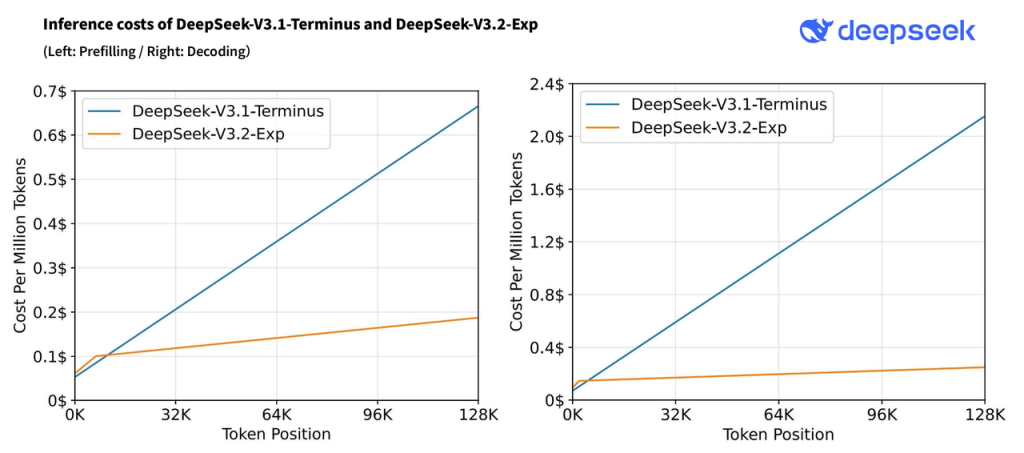
En otras palabras, se duplica la eficiencia para tareas de largo alcance sin degradar el desempeño: los benchmarks públicos han demostrado que V3.2-Exp logra métricas virtualmente idénticas a V3.1-Terminus tras introducir la atención dispersa.
# Ejemplo simplificado de atención dispersa en DeepSeek V3.2-Exp
# Paso 1: Indexador rápido identifica segmentos relevantes del contexto completo
segmentos_relevantes = indexar_contexto(contexto_completo)
# Paso 2: Selección fina de tokens clave dentro de los segmentos relevantes
tokens_clave = seleccionar_tokens(segmentos_relevantes, max_tokens=ventana_atencion_limitada)
# Paso 3: Atención densa aplicada solo sobre los tokens seleccionados (ventana reducida)
salida_modelo = atencion_densa(tokens_clave)
En el pseudocódigo anterior, ventana_atencion_limitada podría ser, por ejemplo, el tamaño máximo de tokens que la atención estándar procesa en una capa (mucho menor que el contexto completo).
Así, DSA permite que DeepSeek V3.2-Exp maneje entradas de miles de tokens sin incurrir en el costo cuadrático típico de la atención densa tradicional, ya que la mayoría de tokens son filtrados antes de la fase de atención intensiva.
Esta innovación es especialmente útil para aplicaciones como análisis de documentos extensos, código fuente voluminoso o conversaciones muy largas, donde el modelo puede aprovechar toda la información pero enfocándose solo en las partes pertinentes en cada momento.
Optimización de inferencia y paralelismo
Además de su arquitectura base, DeepSeek V3.2-Exp incorpora mecanismos internos orientados a optimizar la inferencia y maximizar el rendimiento en entornos de producción:
Predicción multi-token para acelerar la generación
Durante el entrenamiento de V3.2-Exp se introdujo un objetivo de Predicción Multi-Token (MTP), una técnica que va más allá de la generación secuencial estándar.
En lugar de entrenar al modelo únicamente para predecir el siguiente token, se le entrena para predecir múltiples tokens futuros por adelantado (en concreto, un “paso” adicional de predicción más allá del siguiente token).
Esto significa que cada token prevé no solo el siguiente en la secuencia, sino también uno subsiguiente, aprendiendo dependencias más largas.
Esta estrategia resulta beneficiosa para la calidad y, crucialmente, puede explotarse en la inferencia para acelerar la generación de texto.
Mediante decoding especulativo, el modelo es capaz de proponer varios tokens en un solo paso de inferencia y luego verificar su validez, reduciendo la latencia sin sacrificar corrección.
En términos prácticos, esta predicción multi-token permite aprovechar mejor el paralelismo interno durante la generación de texto, entregando respuestas más rápidamente, algo especialmente valioso dado el gran tamaño del modelo.
Paralelismo masivo y kernels especializados
El enorme tamaño de DeepSeek V3.2-Exp exige un despliegue distribuido y optimizado tanto para entrenamiento como para inferencia.
En la fase de entrenamiento, el equipo de DeepSeek diseñó la infraestructura para ejecutar el modelo en múltiples GPUs y nodos en paralelo, combinando paralelismo de datos, tensor parallelism y pipeline parallelism.
Por ejemplo, se distribuyeron las diferentes capas del transformador a lo largo de varios dispositivos (pipeline), y dentro de cada capa las operaciones de los expertos MoE se repartieron equitativamente en 64 GPUs (8 nodos), logrando equilibrar la carga.
Un token enrutado a 8 expertos termina siendo procesado en hasta 4 nodos, según la restricción mencionada, evitando cuellos de botella de comunicación.
Gracias a un cuidadoso co-diseño de algoritmos, framework y hardware, se alcanzó un solapamiento casi total entre cómputo y comunicación en las operaciones distribuidas (all-to-all de MoE), maximizando la utilización de los recursos.
Este nivel de optimización permitió entrenar el modelo de 671B parámetros de forma estable y eficiente, completando el pre-entrenamiento en ~2.7 millones de horas-GPU H800 (un costo notablemente bajo dado el tamaño).
Para la inferencia, igualmente se requiere hardware de primera línea y configuración paralela. La huella de memoria de V3.2-Exp es significativa, especialmente cuando se aprovecha su máximo contexto largo.
En entornos de prueba se recomienda usar GPUs con amplia VRAM (por ejemplo, NVIDIA H200 o las nuevas B200/GB200 de arquitectura Blackwell) para ejecutar el modelo en un solo nodo.
En GPUs como la H100, típicamente es necesario usar múltiples GPUs (o incluso nodos) en conjunto para cargar el modelo completo y soportar contextos extensos.
Afortunadamente, la comunidad ha facilitado el despliegue: el motor de inferencia vLLM brindó soporte desde el día uno para DeepSeek V3.2-Exp, permitiendo ejecutar el modelo de forma distribuida con relativa facilidad en clusters modernos.
Asimismo, el modelo está integrado en plataformas como Red Hat OpenShift AI, demostrando que su uso en entornos de producción escalables es factible con las herramientas adecuadas.
Otro factor crucial para el rendimiento son las implementaciones de bajo nivel. DeepSeek V3.2-Exp viene acompañado de kernels de GPU especializados para maximizar la velocidad de sus operaciones internas.
Por ejemplo, el proyecto libera un conjunto de kernels CUDA llamado DeepGEMM, optimizados para multiplicaciones de matrices dispersas y cálculos de atención con índices: estos kernels calculan los logits de atención utilizando estructuras de índices en lugar de multiplicaciones densas, lo que resulta ideal cuando solo se debe computar una “rebanada” del patrón de atención (como ocurre con DSA).
DeepGEMM incluye también versiones paged (paginadas) que permiten manejar secuencias tan largas que las claves/valores deben almacenarse parcialmente en memoria principal o incluso disco, transfiriendo porciones a la GPU bajo demanda.
Complementando a DeepGEMM, está FlashMLA, un conjunto de kernels de atención dispersa ultra-rápidos que implementan operaciones de gather/scatter y softmax fusionadas adaptadas a los patrones de sparsidad específicos de DeepSeek.
Estas implementaciones aprovechan al máximo la arquitectura GPU moderna para que incluso con atención fragmentada el cálculo sea lo más eficiente posible.
Para fines de investigación, DeepSeek también proporciona kernels en un lenguaje llamado TileLang (más legibles y fáciles de modificar) para experimentar con nuevas variantes de la atención dispersa sin tener que lidiar con toda la complejidad de CUDA.
Uso previsto y capacidades del modelo
Integración práctica: uso de la API
Para probar DeepSeek V3.2-Exp sin desplegar el modelo localmente:
- Obtén tu clave desde el panel de DeepSeek y guárdala en una variable de entorno.
- Llama al endpoint de chat con el ID del modelo que tengas habilitado (p. ej., un chat/instruct basado en V3.2-Exp).
- Envía un historial de mensajes (
system,user) y controla coste/estilo conmax_tokens,temperaturey (si procede) un modo de razonamiento. - Buenas prácticas: limita
max_tokens, activa streaming para UX, y cachea prompts largos si tu proveedor lo permite.
Ejemplo mínimo (cURL):
curl https://api.deepseek.com/v1/chat/completions \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role":"system","content":"Eres un asistente técnico y conciso."},
{"role":"user","content":"Resume en 3 puntos las ventajas de V3.2-Exp."}
],
"max_tokens": 300,
"temperature": 0.2
}'

DeepSeek V3.2-Exp está concebido como un modelo experimental de vanguardia, pensado para explorar mejoras arquitectónicas en LLMs de código abierto y servir de base para futuras versiones de DeepSeek.
Su enfoque principal es técnico: eficiencia en contexto largo y escalabilidad, más que aportar nuevas funcionalidades de contenido.
No es un modelo explícitamente multimodal (se limita a entrada/salida en lenguaje natural, incluyendo código), pero gracias a su enorme tamaño y entrenamiento diverso, demuestra un desempeño fuerte en múltiples dominios de texto.
Evalúa correctamente tareas de razonamiento complejo, QA, y programación, habiendo obtenido resultados competitivos en benchmarks desde exámenes académicos hasta desafíos de código.
Además, incorpora capacidades de agente (por ejemplo, integración con herramientas externas como navegadores web) cuando se le encadena en sistemas mayores, como evidencia su buen rendimiento en pruebas de tool use y entornos conversacionales.
Como modelo abierto (open-weight), V3.2-Exp puede ser utilizado por desarrolladores para experimentar con sus innovaciones.
Su lanzamiento público incluye tanto los pesos del modelo (alojados en Hugging Face) como un detallado informe técnico y código de ejemplo para ejecución local.
En la práctica, está dirigido a casos donde se necesite procesar grandes volúmenes de texto o código en una sola pasada – por ejemplo, análisis de libros completos, revisión de bases de código extensas, o conversaciones acumulativas de miles de turnos – beneficiándose de su ventana de contexto de 128K tokens y la atención dispersa que la hace viable.
Los ingenieros y científicos pueden aprovechar DeepSeek V3.2-Exp para investigar nuevas ideas (como mejoras en máscaras de sparsidad, o híbridos entre atención densa y dispersa) sobre una base ya potente.
Aunque V3.2-Exp es un lanzamiento experimental y con algunas limitaciones (se han observado ligeras regresiones en tareas matemáticas complejas respecto al modelo denso), representa un salto adelante en arquitectura de modelos de lenguaje: demuestra que es posible roughly duplicar la eficiencia de inferencia en contexto largo sin pérdida significativa de precisión.
En conjunto, DeepSeek V3.2-Exp ofrece a la comunidad técnica un emocionante campo de pruebas para modelos de lenguaje gigantes, eficientes y abiertos, marcando el camino hacia la próxima generación de AI con mezcla de expertos y atención optimizada.