
Un equipo de investigación internacional, bajo el nombre DeepSeek-AI, ha anunciado el lanzamiento de DeepSeek-R1-0528, un modelo de lenguaje de última generación enfocado en razonamiento avanzado.
Esta nueva versión, presentada a finales de mayo de 2025, supone una mejora significativa respecto a iteraciones previas, logrando un rendimiento equiparable al de modelos cerrados líderes como OpenAI-o3 y Google Gemini 2.5 Pro.
DeepSeek-R1-0528 está dirigido especialmente a la comunidad investigadora en inteligencia artificial, combinando innovaciones en arquitectura y entrenamiento para resolver problemas complejos de matemáticas, lógica y programación con precisión sin precedentes.
Además, el modelo se lanza con una filosofía de código abierto, disponible bajo licencia MIT, lo que permitirá a investigadores y desarrolladores examinar, utilizar y adaptar sus capacidades libremente.
Antecedentes y mejoras clave
DeepSeek-R1-0528 forma parte de la primera generación de modelos de razonamiento de DeepSeek-AI, sucediendo a dos hitos anteriores: DeepSeek-R1-Zero y DeepSeek-R1.
El modelo R1-Zero fue un experimento pionero entrenado exclusivamente mediante aprendizaje por refuerzo (RL) sin una fase previa de afinación supervisada, logrando que emergieran de forma natural comportamientos de razonamiento complejos.
Sin embargo, R1-Zero adolecía de problemas de legibilidad, repeticiones y mezcla de idiomas en sus respuestas.
Para abordar estas limitaciones, el equipo introdujo DeepSeek-R1, incorporando una etapa de datos de arranque (“cold-start data”) y afinación supervisada antes del RL, mejorando la coherencia lingüística sin sacrificar sus habilidades de razonamiento.
La nueva versión DeepSeek-R1-0528 representa una actualización incremental en numeración, pero sustancial en desempeño.
A continuación se resumen sus mejoras más destacadas respecto a la versión previa:
- Mayor profundidad de razonamiento: Gracias a optimizaciones algorítmicas en la etapa de post-entrenamiento y un uso de mayor computación, el modelo ahora explora cadenas de pensamiento mucho más largas y profundas al enfrentar problemas difíciles. Por ejemplo, en el examen matemático AIME 2025, su tasa de aciertos saltó del 70% a 87,5% respecto a la versión anterior, incremento atribuido a que ahora genera en promedio 23.000 tokens de razonamiento por pregunta en lugar de 12.000. Esta doble intensidad de pensamiento le permite desglosar problemas complejos con mayor eficacia.
- Reducción de alucinaciones y mejor coherencia: DeepSeek-R1-0528 produce respuestas más fieles a los datos y contextos proporcionados, disminuyendo notablemente la proporción de invenciones o errores factuales en sus generaciones. Sus desarrolladores señalan que el modelo ha refinado su capacidad de autoverificación y reflexión, heredada de R1-Zero, para chequear la validez de sus propias respuestas antes de entregarlas. Esto resulta en explicaciones más confiables y consistentemente lógicas.
- Soporte nativo de indicaciones de sistema y funciones: A diferencia de versiones previas, ya no es necesario un prompt especial del tipo
<think>\npara activar el “modo reflexión” del modelo. DeepSeek-R1-0528 ahora entiende mensajes de sistema (instrucciones iniciales) y puede seguir indicaciones de función de forma directa, facilitando su integración en aplicaciones conversacionales avanzadas. En esta versión se destaca una mejor compatibilidad con llamadas a funciones externas, útil para entornos donde el modelo deba interactuar con herramientas o ejecutar acciones. - Ventana de contexto ampliada: Una de las mejoras técnicas más impresionantes es la expansión de su contexto hasta 128.000 tokens, un salto muy por encima de la mayoría de modelos disponibles. Esto significa que DeepSeek-R1-0528 puede procesar y “recordar” enormes cantidades de texto en una sola interacción. En la práctica, esta ampliación permite manejar documentos extensos, mantener diálogos con decenas de páginas de historial, o incluso entender proyectos de código con múltiples archivos interrelacionados sin perder de vista detalles importantes. Pruebas internas demuestran que el modelo mantiene alta exactitud en tareas de recall de texto incluso usando 32K tokens de contexto, preservando la coherencia y relevancia de sus respuestas cerca del límite superior de contexto.
- Experiencia mejorada en generación de código (“vibe coding”): DeepSeek-R1-0528 sobresale en tareas de programación. Los desarrolladores mencionan que ofrece una mejor experiencia de codificación, produciendo código más limpio y estructurado, con menor propensión a errores sintácticos. De hecho, en pruebas de generación de código, logró producir soluciones extensas y complejas (se reportan casos de >700 líneas de código generadas) con funcionalidades avanzadas, acompañadas de comentarios y siguiendo buenas prácticas de diseño modular. Esta capacidad de “código con ambiente” sugiere que el modelo entiende contextos amplios de desarrollo de software, pudiendo no solo escribir funciones aisladas sino también integrar múltiples componentes con sentido holístico.
En conjunto, estas mejoras posicionan a DeepSeek-R1-0528 como un modelo significativamente más robusto y útil para escenarios de razonamiento complejo y desarrollo de software, manteniendo al mismo tiempo salidas más seguras y controlables que sus antecesores.
Arquitectura técnica y entrenamiento
Detrás de los avances de DeepSeek-R1-0528 hay importantes innovaciones en su arquitectura y procedimiento de entrenamiento.
El modelo está construido sobre la base “DeepSeek-V3”, que emplea una arquitectura de tipo Mixture-of-Experts (MoE) a gran escala.
En cifras, el modelo completo abarca unos 671 mil millones de parámetros totales, de los cuales aproximadamente 37 mil millones de parámetros están activos en cada inferencia.
Esta configuración MoE permite incrementar drásticamente la capacidad de representaciones y conocimientos del modelo sin que cada consulta tenga que procesar todos los parámetros a la vez.
Así, DeepSeek-R1-0528 logra combinar lo mejor de dos mundos: una inmensa base de conocimiento y un costo inferencial efectivo equivalente a un modelo denso de ~37B parámetros, habilitando además la citada ventana de contexto de 128K tokens gracias a un diseño optimizado de memorias y posicionamiento.
En cuanto al proceso de entrenamiento, el equipo de DeepSeek-AI aplicó un enfoque multifásico orientado a maximizar las habilidades de razonamiento:
- Aprendizaje por refuerzo a gran escala sin SFT inicial: La fase que dio origen a DeepSeek-R1-Zero consistió en tomar un modelo base pre-entrenado y sumergirlo en un esquema de reinforcement learning enfocado en tareas de razonamiento, sin una etapa previa de fine-tuning supervisado (SFT). Sorprendentemente, esto permitió que el modelo desarrollara por sí mismo técnicas como cadena de pensamiento (CoT) prolongada, auto-chequeo de respuestas y reflexión iterativa. Los creadores destacan que es la primera vez que se demuestra abiertamente que una LM puede mejorar su capacidad de razonamiento exclusivamente mediante RL, sin necesidad de datos etiquetados de ejemplo humano. Este hallazgo supone un hito, pues sugiere que los modelos pueden aprender a pensar paso a paso incentivando métricas adecuadas en un entorno de refuerzo.
- Afinación supervisada y RL en múltiples etapas: Para pasar de R1-Zero al modelo completo DeepSeek-R1, se implementó un pipeline de cuatro etapas principales: primero una fase de SFT con datos “de arranque en frío” (cold-start) para inculcar capacidades lingüísticas y de razonamiento básicas al modelo; luego una primera fase de RL para descubrir patrones de razonamiento mejorados más allá de los datos supervisados; seguidamente una segunda afinación supervisada para afinar la legibilidad, conocimientos generales y otras habilidades no directamente cubiertas por el RL previo; y finalmente una segunda fase de RL (en forma de RL con retroalimentación humana, presumiblemente) para alinear el modelo a preferencias humanas y pulir el estilo de sus respuestas. Este proceso dual de RL+SFT permitió combinar los beneficios del descubrimiento autónomo de estrategias (propiciado por RL) con las garantías de coherencia y calidad en lenguaje natural (aportadas por la afinación con ejemplos humanos). Los investigadores confían en que esta metodología de entrenamiento en múltiples rondas servirá para construir modelos mejores en la industria, al equilibrar razonamiento profundo con alineamiento.
- Distilación de conocimientos a modelos más pequeños: Otro aspecto técnico relevante es cómo DeepSeek-AI aprovechó a DeepSeek-R1 como “profesor” para entrenar versiones más pequeñas. Utilizando los datos de cadenas de razonamiento generados por el modelo grande, el equipo afinó varios modelos densos de menor tamaño (1.5B, 7B, 8B, 14B, 32B y 70B de parámetros) basados en arquitecturas abiertas populares (series Qwen 2.5 de Alibaba y Llama 3 de Meta). Los resultados muestran que estas versiones distilladas retienen gran parte de las capacidades de razonamiento del modelo original, superando incluso a lo que modelos pequeños lograrían entrenando RL por sí solos. Un caso notable fue la versión DeepSeek-R1-0528-Qwen3-8B, un modelo de solo 8 mil millones de parámetros al que se transfirió el “estilo de pensamiento” del modelo grande: logró un desempeño récord entre los modelos abiertos de su rango, igualando en una prueba de matemáticas (AIME 2024) la puntuación de un modelo de 235B parámetros con razonamiento explícito. “Creemos que la cadena de razonamiento de DeepSeek-R1-0528 será de enorme importancia tanto para la investigación académica sobre modelos de razonamiento como para el desarrollo industrial de modelos a pequeña escala”, afirman los autores refiriéndose a este proceso de distilación. Este enfoque demuestra que incluso sistemas con recursos más modestos pueden beneficiarse de las habilidades descubiertas por un modelo gigante, abriendo la puerta a IA más accesible sin perder potencia.
En síntesis, la arquitectura de DeepSeek-R1-0528 combina escala masiva (vía MoE) con entrenamiento especializado en razonamiento, y se acompaña de un ecosistema de modelos derivados.
Para la comunidad de IA, este diseño ofrece tanto un objeto de estudio único (por su entrenamiento basado en RL puro) como una familia de modelos utilizables en diversos contextos prácticos.
Rendimiento destacado en benchmarks
Uno de los aspectos que más validan las contribuciones de DeepSeek-R1-0528 es su excelente rendimiento en una amplia batería de benchmarks de razonamiento, matemáticas y programación.
Los resultados reportados indican que este modelo alcanza o supera el estado del arte en múltiples tareas entre los modelos de código abierto, acortando la brecha que tradicionalmente separaba a estos de los sistemas propietarios más avanzados.
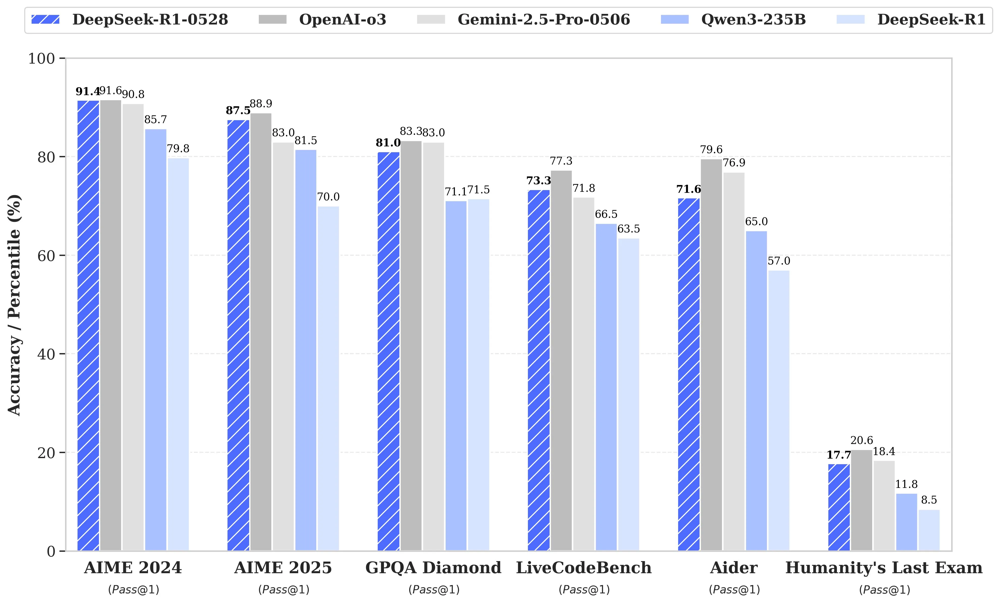
Comparativa del desempeño de DeepSeek-R1-0528 (barras azul rayado) frente a modelos líderes: OpenAI-o3 (gris), Gemini-2.5-Pro (negro), Qwen3-235B (azul) y la versión anterior DeepSeek-R1 (celeste) en varios benchmarks de razonamiento, código y matemáticas.DeepSeek-R1-0528 logra resultados cercanos o superiores a los modelos comerciales en la mayoría de pruebas.
En el ámbito de las matemáticas y lógica, DeepSeek-R1-0528 demostró habilidades sobresalientes.
En la exigente competencia American Invitational Mathematics Examination (AIME) logró una puntuación de 91,4% (Pass@1) en la versión 2024 y 87,5% en la de 2025, acercándose mucho a los mejores sistemas cerrados (incluso superando ligeramente al modelo de OpenAI de referencia en AIME-2025) y muy por encima del 70% que obtenía su predecesor.
Asimismo, en el concurso internacional de matemáticas HMMT 2025 pasó de un modesto 41,7% a 79,4% de aciertos con la nueva versión, lo que evidencia un salto cualitativo importante en resolución de problemas matemáticos de alto nivel.
En otra métrica apodada Humanity’s Last Exam –un conjunto de preguntas de cultura general extremadamente desafiantes– duplicó su tasa de respuestas correctas (17,7% vs 8,5% antes), acercándose al rendimiento de modelos mucho más grandes como Qwen3-235B en este test de “último bastión” del conocimiento.
En cuanto a programación y generación de código, DeepSeek-R1-0528 también establece nuevos máximos entre los modelos abiertos.
En el benchmark LiveCodeBench, que evalúa la capacidad de escribir código ejecutable correctamente (pass@1), el modelo elevó su puntuación de 63,5% a 73,3%, ubicándose muy cerca del desempeño de OpenAI-o3 (≈77%).
De hecho, según datos del equipo, DeepSeek-R1-0528 figura en la cuarta posición global de la clasificación de LiveCodeBench, superando a varios modelos consagrados en asistencias de código.
Relacionado a ello, en la métrica de Codeforces (que asigna un “rating” similar al de un competidor humano de programación competitiva), pasó de ~1530 puntos a 1930 puntos, lo que equivaldría aproximadamente a un desarrollador de nivel experto.
Cabe destacar que estos resultados implican que DeepSeek-R1-0528 no solo escribe código sintácticamente correcto, sino que resuelve problemas de programación de manera óptima en un solo intento con frecuencia mucho mayor que antes.
Adicionalmente, en pruebas de depuración y revisión de código, el modelo mostró capacidad para detectar bugs lógicos complejos y proponer correcciones estructuradas, manejando incluso retos con múltiples lenguajes y marcos de trabajo interconectados.
Este desempeño posiciona a DeepSeek-R1-0528 como la IA open-source más potente en programación hasta la fecha, rivalizando en comprensión de código con algunas soluciones propietarias.
En evaluaciones de lenguaje y conocimiento general, el modelo mantiene un rendimiento de punta.
En el conjunto enciclopédico MMLU (Massive Multitask Language Understanding), que abarca preguntas de diversas disciplinas, DeepSeek-R1-0528 obtuvo alrededor de 85% de exactitud (Exact Match) en su versión avanzada, ligeramente mejor que la iteración previa.
También muestra altas puntuaciones en frameworks de QA de sentido común como GPQA-Diamond (81% pass@1, mejorando 10 puntos porcentuales) y en tareas de comprensión de lectura.
Incluso en evaluaciones especializadas en chino, como el examen C-Eval y el desafío CLUE, el modelo mantiene o mejora su desempeño, consolidándose como una solución bilingüe competente para tareas en inglés y chino.
En resumen, los benchmarks confirman que DeepSeek-R1-0528 ha cerrado la brecha con los modelos de IA más avanzados disponibles.
Tal y como reporta el equipo de DeepSeek-AI, su rendimiento global ya es “comparable al modelo OpenAI-o1 en tareas de matemáticas, código y razonamiento”, lo cual es notable considerando que OpenAI-o1 (y su versión “mini”) hacen referencia a configuraciones cercanas a GPT-4.
Este logro sugiere que la comunidad open-source, con los enfoques adecuados, puede alcanzar niveles de excelencia antes reservados a laboratorios cerrados.
Disponibilidad de código abierto y modelos derivados
Fiel al objetivo de impulsar la investigación abierta, DeepSeek-AI ha publicado DeepSeek-R1-0528 como proyecto de código abierto.
El modelo completo (así como su precursor R1-Zero) y los checkpoints de los modelos distillados están disponibles para descarga en Hugging Face y GitHub, bajo una licencia permisiva MIT.
Esto significa que investigadores y desarrolladores pueden examinar el código, los pesos del modelo y reproducir los experimentos libremente, fomentando la transparencia y colaboración en la comunidad.
Dada la complejidad del modelo principal (recordemos sus requerimientos de ~160 GB de VRAM+RAM para ejecución óptima en 128K de contexto), el equipo ha proporcionado también herramientas para facilitar su uso en entornos más limitados, incluyendo técnicas de cuantización.
Por ejemplo, ofrecen una variante cuantizada a ~2,7 bits efectivos que reduce drásticamente la carga computacional sin degradar mucho el rendimiento, lo que permite ejecutar DeepSeek-R1-0528 en servidores con hardware de gama alta pero no necesariamente supercomputadores.
Junto con el modelo principal, se liberó una familia de modelos secundarios entrenados mediante distillation.
En total son seis modelos densos de distintos tamaños – 1.5B, 7B, 8B, 14B, 32B y 70B parámetros – que heredan las capacidades de razonamiento de DeepSeek-R1-0528.
Estos modelos utilizan como base arquitecturas ampliamente conocidas (versiones recientes de Qwen y Llama, adaptadas por los autores), lo que facilita su adopción dado que son compatibles con los frameworks y tokenizadores ya existentes.
Por ejemplo, el modelo DeepSeek-R1-Distill-Qwen-32B se construyó sobre la serie Qwen 2.5 de 32B y ha logrado nuevos récords de rendimiento para modelos densos de su tamaño, superando al mencionado OpenAI-o1-mini en múltiples benchmarks.
De manera análoga, el DeepSeek-R1-Distill-Llama-70B (basado en Llama v3 de 70B) ofrece a la comunidad un modelo abierto de alta gama con puntuaciones líderes en tareas de razonamiento y matemáticas.
La disponibilidad de estos modelos intermedios resulta estratégica: permiten a equipos con menos recursos aprovechar los avances de DeepSeek-R1, adaptándolos a casos de uso específicos o corriéndolos localmente con un coste computacional mucho menor que el del modelo completo.
Adicionalmente, DeepSeek-AI ha puesto a disposición una plataforma web y API para probar el modelo de forma interactiva.
En el portal oficial (chat.deepseek.com) cualquier usuario puede conversar con DeepSeek-R1-0528 y, si lo desea, activar un modo de “DeepThink” que explicita las cadenas de razonamiento que el modelo está siguiendo.
También ofrecen una API compatible con el estándar de OpenAI, lo que significa que desarrolladores pueden integrar DeepSeek-R1 en sus aplicaciones sustituyendo llamadas a servicios comerciales por esta alternativa abierta.
Estas iniciativas de despliegue demuestran el compromiso del equipo no solo con publicar el modelo, sino con hacerlo accesible y útil para la comunidad desde el primer día.
Aplicaciones potenciales e impacto
El salto en capacidades de DeepSeek-R1-0528 abre un abanico de posibles aplicaciones en el campo de la inteligencia artificial, muchas de las cuales antes estaban limitadas a unos pocos modelos propietarios de alto costo:
- Asistente de investigación y educación: Gracias a su notable habilidad de razonamiento y a la posibilidad de trazar largas cadenas lógicas, el modelo puede fungir como un tutor o asistente en disciplinas STEM. Por ejemplo, podría ayudar a resolver problemas matemáticos avanzados paso a paso, demostrar teoremas, o analizar textos científicos extensos identificando hipótesis y conclusiones clave. Su reducida tendencia a alucinar información lo hace más confiable para explicar conceptos o discutir preguntas abiertas apoyándose en hechos.
- Desarrollo de software a gran escala: La combinación de una ventana de contexto masiva (128K) con competencias de codificación sobresalientes convierte a DeepSeek-R1-0528 en una herramienta valiosa para ingenieros de software. El modelo puede cargar en su contexto proyectos completos con múltiples archivos de código, documentación y registros de errores, y a partir de allí ofrecer sugerencias integrales: desde generar nuevas funciones que se ajusten al estilo del proyecto, hasta encontrar bugs en diferentes módulos y proponer parches concretos. Esto supera a los asistentes de programación actuales que suelen lidiar solo con fragmentos de código cortos. En entornos de desarrollo, DeepSeek-R1-0528 podría integrarse como un “par programador” virtual que entiende la arquitectura completa de la aplicación en la que trabaja el humano.
- Análisis de documentos largos y multi-idioma: En campos como el legal, la investigación histórica o la minería de información, contar con 128K tokens de contexto significa poder analizar centenares de páginas de texto de una sola vez. DeepSeek-R1-0528 puede resumir, comparar y extraer datos de contratos, informes técnicos o colecciones de artículos manteniendo en memoria detalles distribuidos a lo largo del texto. Su entrenamiento bilingüe (inglés/chino) sugiere que también es adaptable a documentos en distintos idiomas, facilitando aplicaciones de traducción con contexto amplio o análisis translingüísticos (por ejemplo, estudiar cómo cierta información aparece en prensa en distintos idiomas, todo en una sola consulta al modelo).
- Agentes autónomos y robótica cognitiva: La capacidad de razonamiento paso a paso y la integración con llamadas a funciones externas posicionan a DeepSeek-R1-0528 como un excelente núcleo para agentes de IA más autónomos. En sistemas de planificación y robótica, el modelo podría evaluar situaciones complejas, simular consecuencias de acciones en varios pasos y luego invocar funciones (sensores, APIs, controladores) para ejecutar un plan, todo ello manteniendo un hilo de pensamiento estructurado. Su habilidad para “pensar en voz alta” (vía cadenas de pensamiento visibles) es útil para auditar decisiones y garantizar que cumplan restricciones de seguridad o ética antes de actuar.
- Investigación en IA y modelos futuros: Como resultado abierto de vanguardia, DeepSeek-R1-0528 en sí mismo será un instrumento para la comunidad investigadora. Otros equipos podrán inspeccionar qué tipo de datos y recompensas de RL produjeron las mejoras de razonamiento, estudiar las cadenas de pensamiento que genera e incluso utilizarlas como conjunto de datos para entrenar nuevos modelos enfocándose en transparencia y explicabilidad. Además, la demostración de DeepSeek-AI sobre entrenamiento con RL puro inspirará nuevas investigaciones en ese sentido – por ejemplo, explorando cómo refinar las señales de recompensa para obtener aún mejor lógica o cómo escalar estos métodos a dominios como la creatividad o la visión. En palabras de sus creadores, esperan que este trabajo “siente las bases para futuros avances” en modelos de razonamiento incentivados por RL.
Declaraciones del equipo desarrollador
Los líderes del proyecto DeepSeek-R1-0528 han expresado gran entusiasmo por lo que este modelo significa para la IA abierta.
En su informe técnico destacaron que su modelo “alcanza un rendimiento comparable al de OpenAI-o1 en tareas de matemáticas, código y razonamiento”, equiparando por primera vez a una IA abierta con los referentes comerciales en un espectro amplio de desafíos.
Asimismo, subrayan el carácter inédito de su enfoque de entrenamiento, afirmando que “es la primera investigación abierta que valida que las capacidades de razonamiento de los LLM pueden incentivarse puramente mediante RL, sin necesidad de ajuste fino supervisado”.
Esta filosofía de explorar los límites de la autonomía del aprendizaje máquina, dicen, fue clave para descubrir las sorprendentes habilidades emergentes de R1-Zero.
El equipo de DeepSeek-AI también ha hecho hincapié en el valor de compartir estas innovaciones con la comunidad.
“Nuestro objetivo es apoyar a la comunidad investigadora”, indicaron al publicar no solo el modelo grande sino también todas las variantes distilladas y los datos necesarios para replicar sus resultados.
Confían en que otros desarrolladores aprovecharán las cadenas de razonamiento y el pipeline de entrenamiento que han liberado para distillar mejores modelos pequeños en el futuro, llevando capacidades de razonamiento de punta a entornos más accesibles.
En última instancia, DeepSeek-R1-0528 se presenta no solo como una hazaña técnica, sino como un ejemplo del impacto que la colaboración abierta puede tener en el progreso de la inteligencia artificial.