
Esta guía analiza los precios DeepSeek API para DeepSeek V4 con cifras verificadas, ejemplos de factura y comparativas útiles frente a V3.2 y otras APIs habituales del mercado. Si vas a integrar la API de DeepSeek en producción, entender cuánto pagas por entrada, salida y cache hit evita presupuestos mal calculados y sorpresas a final de mes.
Resumen rápido
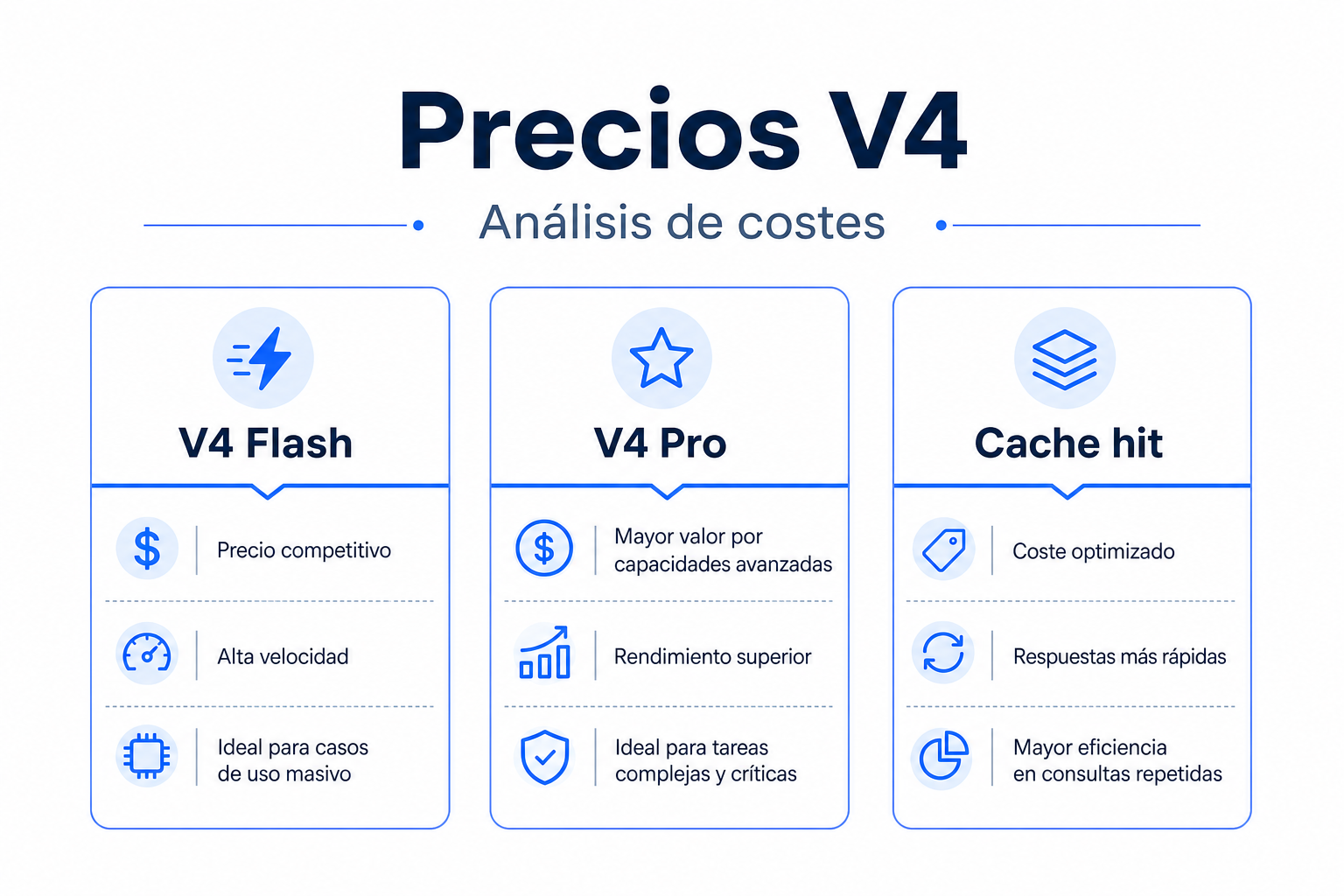
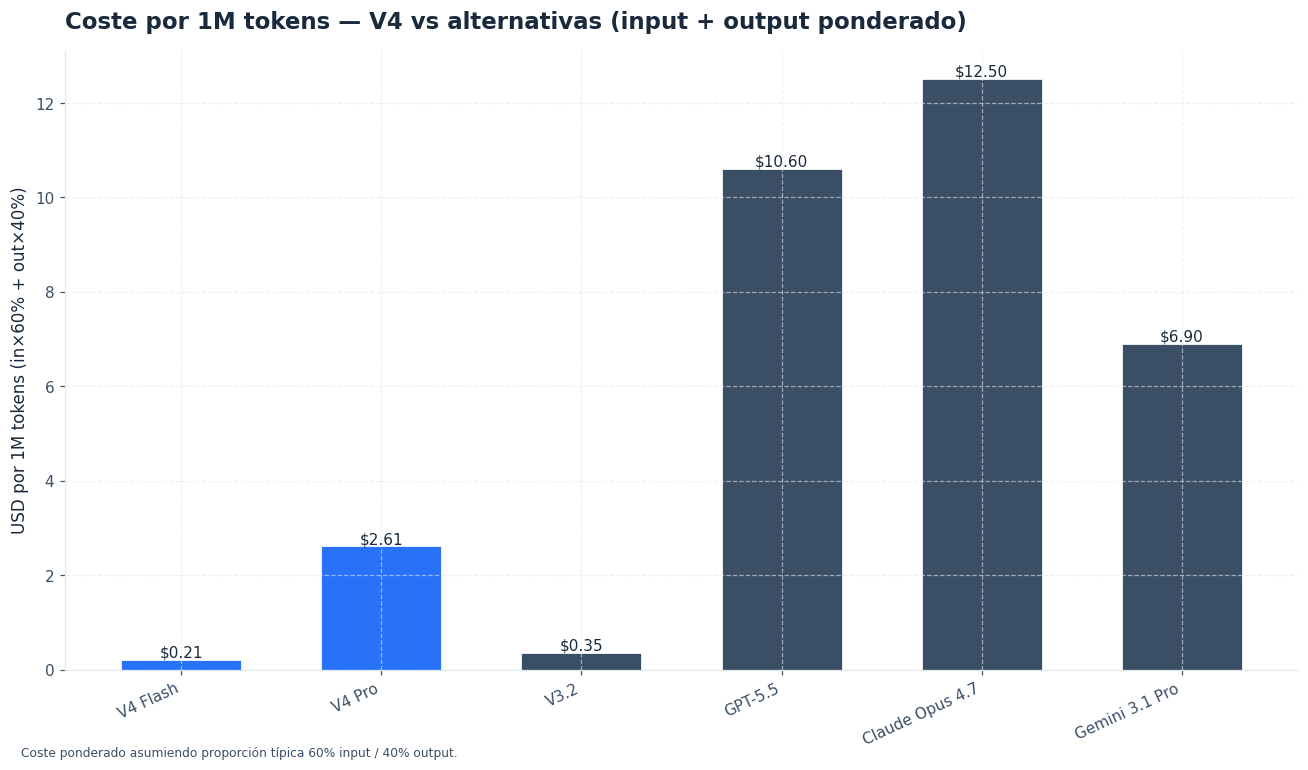
- DeepSeek V4 Flash cuesta $0,14 por 1M tokens de entrada, $0,028 con cache hit y $0,28 por 1M tokens de salida.[1]
- DeepSeek V4 Pro cuesta $1,74 por 1M tokens de entrada, $0,145 con cache hit y $3,48 por 1M tokens de salida.[1]
- Los alias heredados
deepseek-chatydeepseek-reasonersiguen disponibles, pero se retiran el 24 de julio de 2026. Durante esta transición apuntan a modos de deepseek-v4-flash.[2][3] - DeepSeek V4 amplía el contexto a 1M tokens y permite hasta 384K tokens de salida. Eso cambia mucho el coste potencial por petición si no limitas la respuesta.[1]
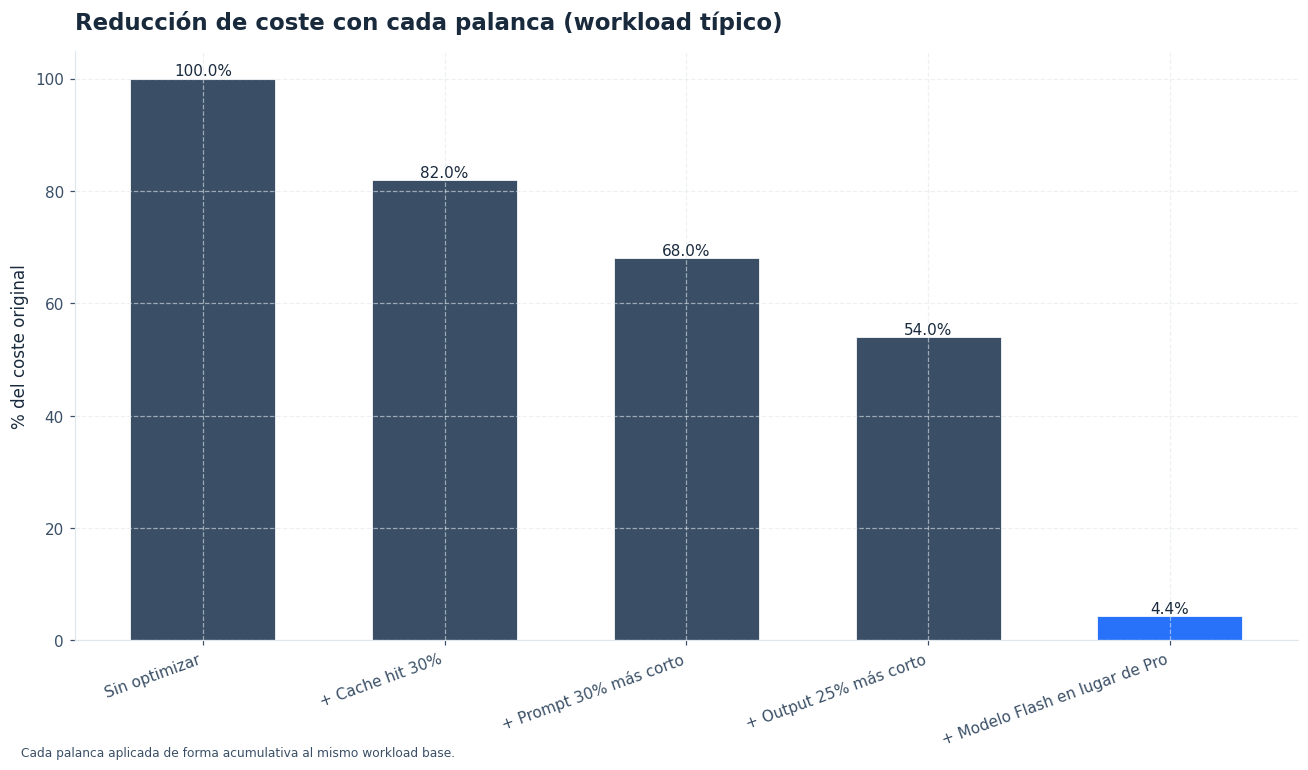
- El ahorro real llega por tres palancas: reutilizar prefijos con caché, recortar el prompt y limitar la salida. Son las medidas que más reducen la factura en uso continuo.[4]
- La API mantiene formato compatible con OpenAI en
https://api.deepseek.com, así que migrar o comparar costes por llamada suele ser sencillo.[2]
Precios oficiales de DeepSeek V4: qué pagas exactamente
La página oficial de precios de DeepSeek factura por 1.000.000 tokens y separa tres conceptos: entrada con cache miss, entrada con cache hit y salida. Esa distinción importa porque una aplicación con mucho contexto repetido puede pagar una fracción del coste de entrada normal.[1][4]
| Modelo | Entrada | Entrada con cache hit | Salida | Contexto | Salida máxima |
|---|---|---|---|---|---|
| DeepSeek V4 Flash | $0,14 / 1M | $0,028 / 1M | $0,28 / 1M | 1M tokens | 384K tokens |
| DeepSeek V4 Pro | $1,74 / 1M | $0,145 / 1M | $3,48 / 1M | 1M tokens | 384K tokens |
| DeepSeek V3.2 heredado | $0,28 / 1M | $0,028 / 1M | $0,42 / 1M | 128K tokens | 8K o 64K según modo |
La diferencia principal entre Flash y Pro no está solo en la calidad del modelo. Está en cuánto te cuesta cada millón de tokens cuando la carga sube. V4 Pro multiplica el coste de entrada y salida frente a Flash, así que conviene reservarlo para tareas donde esa mejora realmente aporte valor: razonamiento complejo, agentes, código difícil o flujos donde el error es caro.[1][5]
Además, V4 permite dos familias de uso: modo normal y modo de razonamiento. En la documentación de DeepSeek, el modo de pensamiento está activado por defecto y en V4 Pro admite ajuste de esfuerzo hasta max, lo que puede aumentar la longitud total generada si no controlas bien la respuesta.[5]
Cómo se calcula la factura de verdad
La fórmula básica es simple: coste = tokens de entrada × precio de entrada + tokens de salida × precio de salida. Si una parte del prefijo entra en caché, esos tokens se cobran a la tarifa de cache hit y no a la de entrada normal.[1][4]
Un ejemplo rápido con V4 Flash:
- Entrada total: 20.000 tokens
- De esos, 12.000 tokens son cache hit
- Salida: 4.000 tokens
El coste sería:
- 8.000 tokens de entrada sin caché × $0,14 / 1M = $0,00112
- 12.000 tokens con caché × $0,028 / 1M = $0,000336
- 4.000 tokens de salida × $0,28 / 1M = $0,00112
- Total: $0,002576
El punto clave es este: en muchas aplicaciones reales, la salida pesa más de lo que parece. Si tu asistente responde con textos largos, informes, JSON extensos o pasos intermedios de razonamiento, la factura crece rápido aunque el prompt sea corto. En V4 Pro esto se nota más, porque el precio de salida es $3,48 por 1M tokens.[1]
Las tarifas pueden cambiar; verifica los importes vigentes en la página de planes y precios antes de presupuestar una integración.
DeepSeek también expone en la respuesta campos de uso relacionados con la caché, incluido prompt_cache_hit_tokens. Eso te permite medir con precisión cuánto ahorro consigues y ajustar tu arquitectura con datos, no con estimaciones vagas.[4]
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer TU_API_KEY" \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{"role": "system", "content": "Responde de forma breve y estructurada."},
{"role": "user", "content": "Resume este documento en 5 puntos."}
],
"max_tokens": 400
}'Ese ejemplo usa la ruta compatible con OpenAI sobre https://api.deepseek.com. Si ya trabajas con herramientas compatibles, la migración suele centrarse en cambiar la URL base, la clave y el nombre del modelo.[2]
V4 frente a V3.2: cuándo pagas menos y cuándo pagas más
DeepSeek V3.2 heredado mantiene un precio de entrada de $0,28 por 1M tokens y salida de $0,42 por 1M tokens, con entrada en caché a $0,028. Frente a eso, V4 Flash baja la entrada a $0,14 y la salida a $0,28, mientras amplía el contexto de 128K a 1M tokens. En precio puro, Flash mejora claramente la relación coste/capacidad frente a V3.2.[1][3]
V4 Pro es otra historia. Es bastante más caro que V3.2, pero no compite por precio mínimo. Compite por calidad de razonamiento, margen de contexto y control del esfuerzo de pensamiento. Si tu carga es atención al cliente básica, clasificación, extracción o reformateo de texto, Flash suele encajar mejor. Si manejas agentes, código complejo o decisiones multipaso, Pro puede compensar aunque suba el coste unitario.[1][5]
También hay una razón operativa para planificar el cambio ya: los alias deepseek-chat y deepseek-reasoner se retiran el 24 de julio de 2026. Si hoy sigues calculando costes con nombres antiguos, conviene actualizar los cuadros de mando, los SDK y las previsiones antes de esa fecha.[2][3]
Comparación práctica con otras APIs: dónde está la ventaja
En una comparación editorial, DeepSeek V4 Flash destaca cuando buscas coste bajo por token, contexto muy amplio y una integración sencilla por compatibilidad con OpenAI. Esa combinación es útil para asistentes con mucho historial, análisis documental, copilotos internos y flujos con prefijos repetidos que aprovechan la caché.[1][2][4]
La comparación con la competencia cambia según el caso de uso, porque no todas las APIs separan igual el precio de entrada, salida y caché. Por eso, la forma correcta de comparar no es mirar solo el coste por 1M tokens. Conviene revisar cuatro variables a la vez: contexto útil, longitud media de salida, tasa de cache hit y calidad suficiente para tu tarea. Esa es la métrica que determina el coste real por tarea completada.
En términos prácticos, DeepSeek suele salir mejor parado en tres escenarios:
- Mucho contexto repetido: documentación fija, instrucciones largas, bases de conocimiento o historiales grandes.
- Mucho volumen: procesos por lotes, clasificación, extracción o enriquecimiento de datos.
- Migraciones rápidas: proyectos que ya hablan con una API compatible con OpenAI y quieren cambiar de proveedor con poco trabajo.
Si buscas una visión actualizada del catálogo y de cada variante, puedes revisar la página de precios, la documentación de DeepSeek V4 Flash y la ficha de DeepSeek V4 Pro para encajar mejor el coste con el rendimiento esperado.
Errores frecuentes al estimar el gasto mensual
El error más común es pensar que el coste depende casi solo del prompt. En muchos productos ocurre justo lo contrario: la salida manda. Un asistente que devuelve respuestas largas, bloques JSON o razonamiento detallado puede duplicar o triplicar la factura prevista si nadie fija límites de salida.
- No separar entrada y salida. Son tarifas distintas y la salida suele ser más cara.
- Ignorar la caché. Si repites instrucciones largas en cada petición, podrías estar pagando de más o midiendo mal el ahorro real.
- Usar V4 Pro por defecto. No todas las tareas necesitan el modelo más caro.
- No fijar
max_tokens. Dejarlo abierto hace que el gasto por respuesta sea menos predecible. - Olvidar el cambio de alias heredados. Si sigues usando nombres antiguos tras el 24 de julio de 2026, romperás integraciones y cuadros de coste.[2][3]
Otro fallo habitual es convertir tokens a palabras con una regla fija. Esa equivalencia cambia según idioma, formato, código y cantidad de números. Para presupuestar, lo más fiable es medir tráfico real durante unos días y usar el campo usage de la API como fuente de verdad.[1][4]
Cómo reducir el coste sin degradar demasiado la calidad
Si quieres bajar gasto de forma visible, conviene actuar en este orden. Son medidas simples, pero tienen impacto inmediato.
- Usa Flash como modelo por defecto. Reserva Pro para las rutas donde una mejora clara justifique el precio.
- Reutiliza prefijos estables. Instrucciones del sistema, contexto fijo y plantillas largas deben mantenerse lo más iguales posible para aumentar el cache hit.[4]
- Acorta el prompt. Elimina repeticiones, ejemplos sobrantes y contexto que el modelo no necesita para decidir.
- Limita la salida. Fija
max_tokens, pide respuestas breves y usa formatos más compactos cuando baste con eso. - Divide tareas. Clasifica primero con Flash y envía solo los casos difíciles a Pro.
- Mide por caso de uso. No optimices a ciegas. Compara coste por tarea correcta, no solo coste por llamada.
Un patrón útil es este: primera pasada con Flash para decidir, resumir o extraer; segunda pasada con Pro solo cuando la confianza sea baja o la tarea requiera razonamiento profundo. Esa arquitectura híbrida suele recortar bastante la factura mensual sin perder calidad donde de verdad importa.
Preguntas frecuentes
¿Cuál es el modelo más barato de DeepSeek V4 en la API?
El más barato es DeepSeek V4 Flash. Cuesta $0,14 por 1M tokens de entrada, $0,028 con cache hit y $0,28 por 1M tokens de salida.[1]
¿DeepSeek V4 Pro merece la pena frente a Flash?
Depende del trabajo. Si tu aplicación necesita razonamiento complejo, agentes o tareas de código difíciles, Pro puede justificar su precio. Para chat general, extracción, clasificación o automatizaciones simples, Flash suele dar mejor equilibrio entre coste y rendimiento.[1][5]
¿Qué pasa con deepseek-chat y deepseek-reasoner?
Son alias heredados. La documentación indica que se retiran el 24 de julio de 2026. Durante el periodo actual apuntan a los modos sin pensamiento y con pensamiento de deepseek-v4-flash por compatibilidad.[2][3]
¿Cómo se factura el cache hit?
Los tokens de entrada que la API puede resolver desde caché se cobran a una tarifa reducida. DeepSeek también devuelve métricas específicas de caché en la sección de uso, así que puedes medir el ahorro real por petición.[1][4]
¿La API de DeepSeek es compatible con OpenAI?
Sí. DeepSeek documenta una API compatible con formato OpenAI en https://api.deepseek.com. Eso facilita reutilizar SDK, herramientas y parte del código existente.[2]
¿Los pesos de DeepSeek V4 son abiertos?
DeepSeek presenta sus modelos y repositorios con licencia MIT en su documentación y materiales oficiales. Si vas a usar pesos abiertos o derivados concretos, conviene revisar siempre el repositorio exacto y sus condiciones antes de desplegar.[6][7]
Recursos relacionados
- DeepSeek en español
- tabla actual de precios
- guía de la API
- probar DeepSeek Chat
- análisis de DeepSeek V4 Flash
- análisis de DeepSeek V4 Pro
Conclusión
Si buscas optimizar precios DeepSeek API, la decisión correcta no es elegir siempre el modelo más barato ni el más potente. La clave está en medir coste por tarea útil. Hoy, DeepSeek V4 Flash ofrece una base muy competitiva para producción, mientras V4 Pro encaja mejor en flujos exigentes donde el razonamiento adicional sí aporta valor. Antes de escalar, revisa tres puntos: cuánto contexto repites, cuánta salida generas y qué porcentaje puedes mover a caché. Con eso tendrás una previsión bastante más realista y una factura más controlable.