
Esta calculadora te ayuda a estimar el coste mensual de la API de DeepSeek a partir del modelo, los tokens de entrada y salida, la caché y el volumen de peticiones.
Obtendrás el coste por petición, por día y por mes, junto con una comparación orientativa frente a GPT-5.5 y Claude Opus 4.7.
Calculadora de coste de la API de DeepSeek
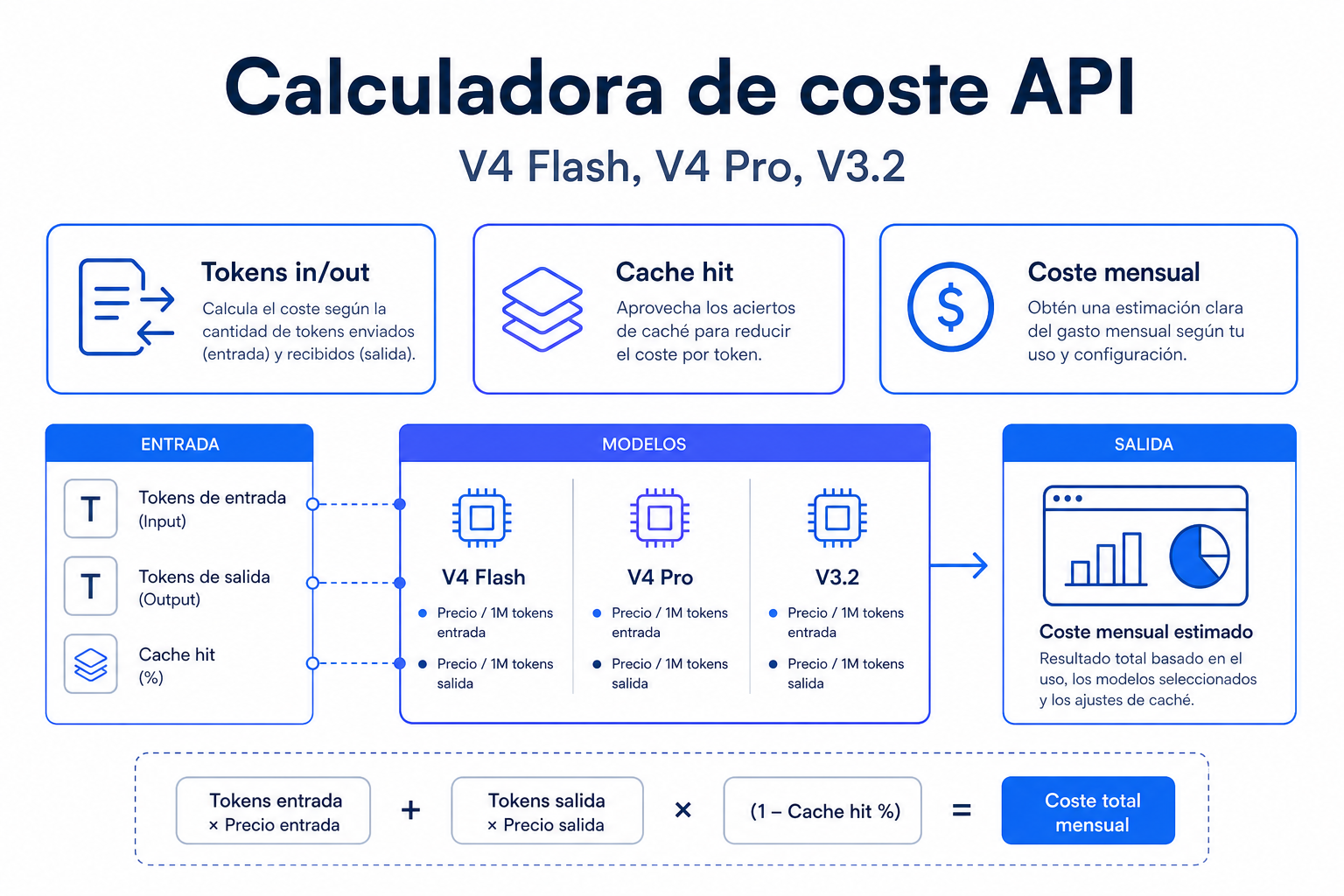
Cómo usar esta herramienta
La calculadora está pensada para estimar gasto antes de integrar la API en una aplicación real. Funciona mejor si introduces datos cercanos a tu uso esperado, no solo valores máximos teóricos.
Empieza eligiendo el modelo. DeepSeek V4 Flash suele encajar en tareas de alto volumen y baja latencia. DeepSeek V4 Pro tiene más sentido cuando necesitas mayor capacidad de razonamiento o respuestas más complejas. DeepSeek V3.2 aparece como opción heredada para comparar costes con integraciones antiguas.
Después introduce los tokens medios de entrada. Aquí debes contar el mensaje del usuario, instrucciones del sistema, contexto recuperado, historial de conversación y cualquier dato que envíes en cada llamada. Si aún no tienes métricas, usa una muestra de prompts reales y estima con una regla aproximada: en español, 1 token equivale a unos 3,7 caracteres; en inglés, a unos 4,0 caracteres.
Añade los tokens medios de salida. Este valor depende de cuánto texto genera el modelo. Un clasificador puede devolver 20 tokens, mientras que un informe técnico puede superar varios miles.
Configura la tasa de acierto de caché si reutilizas prefijos, instrucciones o contexto estable. Una tasa del 60 % significa que seis de cada diez tokens de entrada se facturan al precio reducido de caché, cuando el modelo lo admite. Por último, introduce peticiones por día y días por mes para convertir el coste unitario en presupuesto mensual.
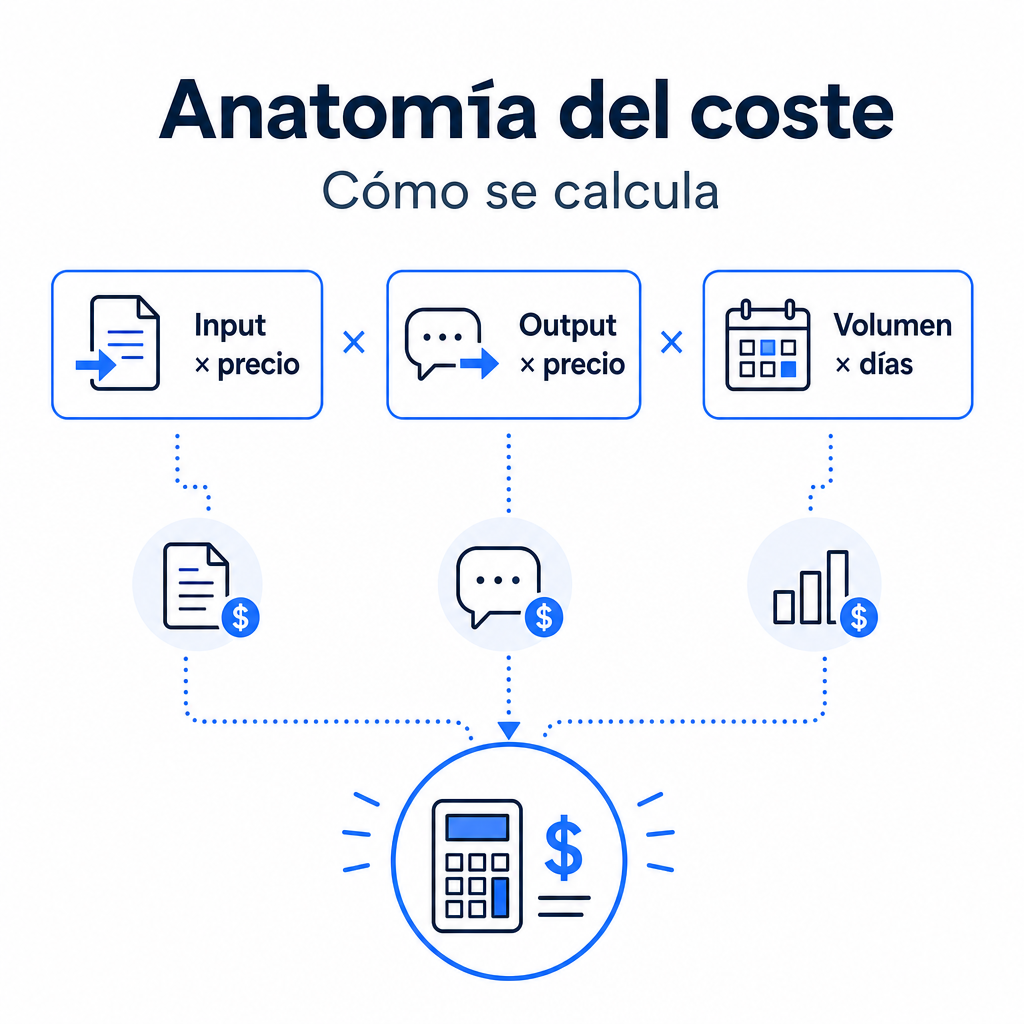
Qué calcula (la matemática detrás)
La API de DeepSeek factura por tokens, separados entre entrada y salida. La entrada incluye todo lo que envías al modelo. La salida incluye lo que el modelo genera como respuesta. Los precios se expresan por 1.000.000 de tokens, así que la calculadora divide tus tokens medios entre 1 M de tokens antes de aplicar la tarifa.
Con datos verificados en mayo de 2026, DeepSeek V4 Flash cuesta $0,14 por 1 M de tokens de entrada y $0,28 por 1 M de tokens de salida. Sus tokens de entrada servidos desde caché cuestan $0,028 por 1 M de tokens. DeepSeek V4 Pro cuesta $1,74 por entrada y $3,48 por salida, con entrada en caché a $0,87 por 1 M de tokens.
Las tarifas pueden cambiar; verifica los importes vigentes en la página de planes y precios antes de presupuestar una integración.
DeepSeek V3.2, opción heredada, usa $0,28 por 1 M de tokens de entrada y $0,42 por 1 M de tokens de salida. Los alias deepseek-chat y deepseek-reasoner quedan obsoletos el 24 de julio de 2026, así que conviene revisar integraciones antiguas antes de proyectar gasto a largo plazo.
La fórmula separa la entrada en dos partes: tokens que no aprovechan caché y tokens que sí la aprovechan. La salida no se beneficia de esa tasa en esta estimación. Después se multiplica el coste por petición por las peticiones diarias y por los días del mes.
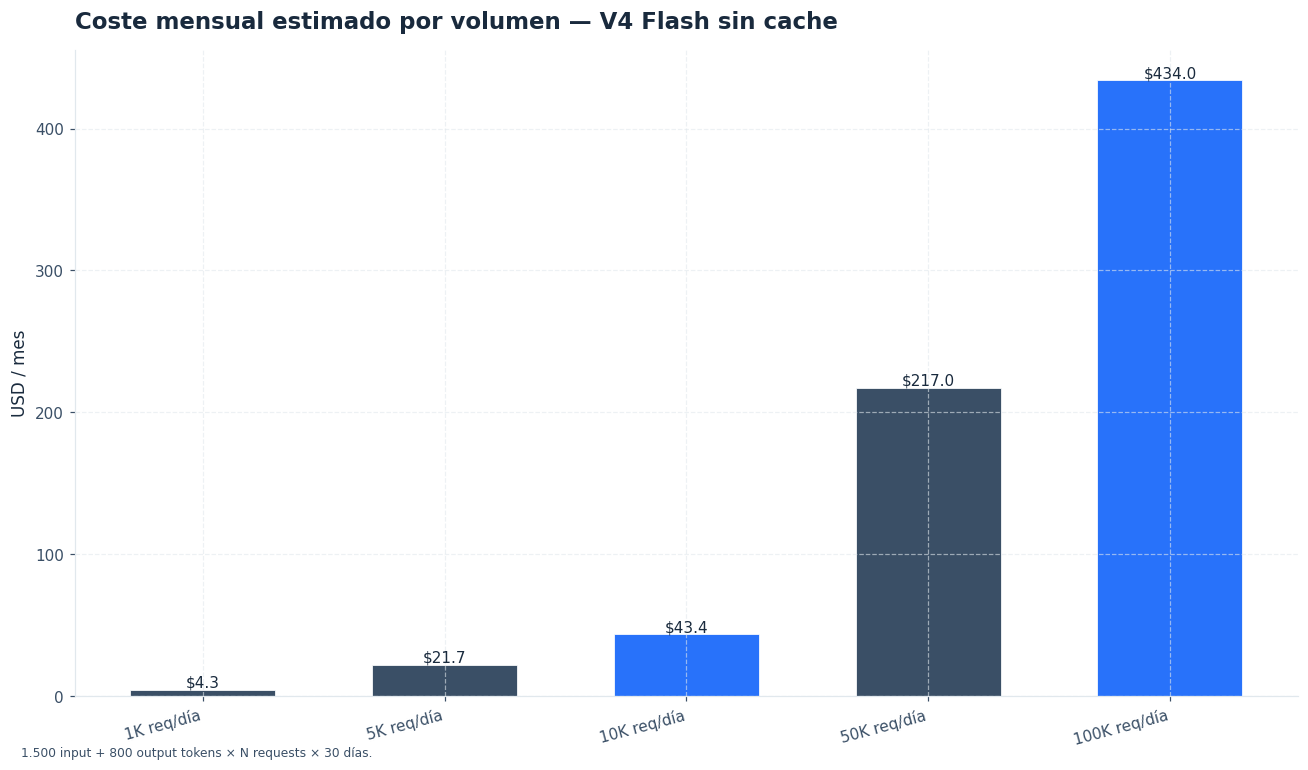
Ejemplo con DeepSeek V4 Flash
Datos:
- Entrada media: 4.000 tokens
- Salida media: 1.000 tokens
- Cache hit: 50 %
- Peticiones por día: 10.000
- Días por mes: 30
Precios:
- Entrada normal: $0,14 / 1M tokens
- Entrada en caché: $0,028 / 1M tokens
- Salida: $0,28 / 1M tokens
Cálculo por petición:
Entrada normal = 4.000 × 50 % × 0,14 / 1.000.000 = $0,00028
Entrada caché = 4.000 × 50 % × 0,028 / 1.000.000 = $0,000056
Salida = 1.000 × 0,28 / 1.000.000 = $0,00028
Coste por petición = $0,000616
Coste diario = $0,000616 × 10.000 = $6,16
Coste mensual = $6,16 × 30 = $184,80La comparación con GPT-5.5 y Claude Opus 4.7 sigue la misma lógica: tokens de entrada, tokens de salida y precio por millón. El resultado no mide calidad, latencia ni límites de uso. Solo compara coste estimado para el mismo patrón de llamadas.
Casos de uso típicos
La estimación cambia mucho según el tipo de producto. Un mismo precio por token puede producir facturas muy distintas si aumentan el contexto, la longitud de respuesta o el número de usuarios activos.
- Chatbot de soporte con base documental. Suele combinar instrucciones del sistema, historial breve y fragmentos recuperados de documentación. La entrada puede ser mayor que la salida, así que la caché resulta útil si repites instrucciones o plantillas.
- Generación de contenido interno. Informes, borradores comerciales, resúmenes largos y análisis tienden a consumir más tokens de salida. En este caso conviene probar límites de longitud y plantillas de respuesta.
- Clasificación y extracción de datos. Etiquetado de tickets, análisis de sentimiento o extracción de campos suelen tener salidas cortas. DeepSeek V4 Flash puede ser suficiente si la tarea no exige razonamiento profundo.
- Agentes con varias llamadas por tarea. Un flujo con planificación, búsqueda, validación y respuesta final puede multiplicar el coste. No basta con medir la última respuesta visible para la persona usuaria.
- Aplicaciones con contexto largo. DeepSeek V4 Pro admite 1 M de tokens de contexto y hasta 384 K de tokens de salida. Estos límites ayudan en cargas extensas, pero también pueden elevar el gasto si se envían documentos completos sin filtrar.
Para una primera aproximación, crea tres escenarios: conservador, esperado y alto. Cambia solo una variable por vez. Así podrás ver si el coste depende más del volumen de peticiones, de la longitud del contexto o de las respuestas generadas.
Errores frecuentes al estimar el coste
Los errores de estimación suelen venir de medir solo el prompt visible. En una integración real también cuentan las instrucciones, los mensajes previos, las herramientas, los resultados intermedios y el contexto añadido por recuperación.
- Ignorar el historial de conversación. Si envías diez turnos anteriores en cada llamada, el coste de entrada crece rápido. Limita el historial o resume conversaciones largas.
- Confundir caracteres con tokens. La relación varía por idioma y contenido. Usa la heurística de 3,7 caracteres por token en español solo como punto de partida.
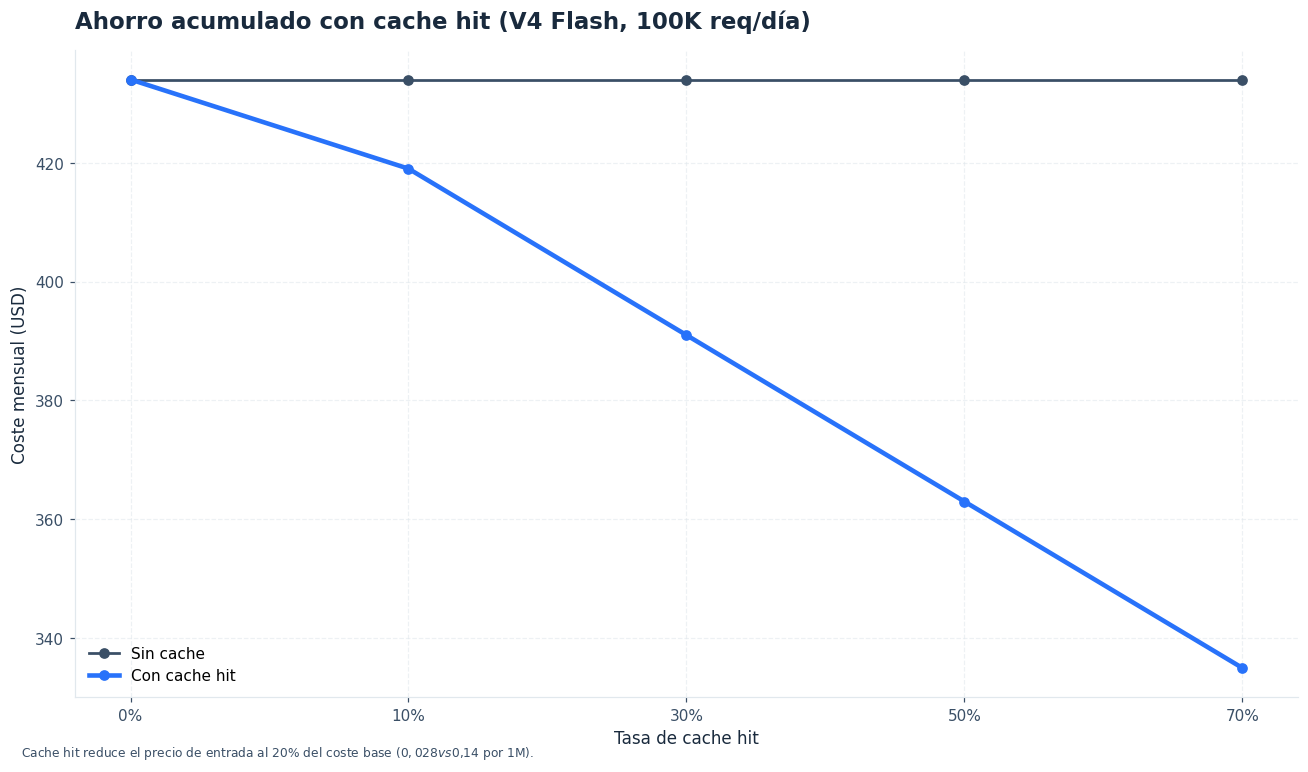
- Asumir un 100 % de caché. La caché depende de prefijos reutilizados y estabilidad del contenido. Prueba con tasas del 0 %, 50 % y 80 % para ver la sensibilidad.
- Olvidar llamadas internas de agentes. Una acción de usuario puede disparar varias llamadas al modelo. Estima coste por tarea completa, no solo por petición HTTP externa.
- No separar entorno de pruebas y producción. Las pruebas con prompts largos, reintentos y depuración pueden generar gasto relevante. Reserva una partida mensual para desarrollo.
- Comparar modelos solo por precio. El modelo más barato puede necesitar más llamadas o respuestas más largas. Mide coste por resultado útil, no solo coste por millón de tokens.
Una buena estimación debe actualizarse con registros reales. Guarda tokens de entrada, tokens de salida, modelo usado, caché y tipo de tarea. Con esos datos podrás ajustar la calculadora cada semana.
Preguntas frecuentes
¿La calculadora muestra el precio exacto de mi factura?
No. Muestra una estimación basada en tokens medios, volumen de peticiones y precios cargados en la herramienta. La factura real puede variar por reintentos, cambios de modelo, uso de caché, errores de integración y patrones de uso no previstos.
¿Qué modelo conviene elegir para estimar un proyecto nuevo?
Usa DeepSeek V4 Flash para escenarios de alto volumen, respuestas breves o tareas rutinarias. Usa DeepSeek V4 Pro si necesitas contexto largo, razonamiento más exigente o salidas complejas. Si migras desde una integración previa, compara también DeepSeek V3.2.
¿Cómo estimo tokens si todavía no tengo una aplicación en producción?
Toma entre 20 y 50 ejemplos reales de entrada, suma instrucciones y contexto, y estima tokens con la regla de caracteres. Después ejecuta pruebas con respuestas esperadas. Añade margen para reintentos y crecimiento de uso.
¿La tasa de acierto de caché reduce todo el coste?
No. En esta herramienta la caché se aplica a tokens de entrada cuando el modelo tiene precio reducido para entrada en caché. Los tokens de salida se calculan con su tarifa normal. Si tu prompt cambia por completo en cada llamada, la tasa efectiva será baja.
¿Por qué comparar contra GPT-5.5 y Claude Opus 4.7?
La comparación ayuda a ver el impacto presupuestario de mantener el mismo volumen de tokens en otros modelos. No sustituye una evaluación técnica. Para decidir, también debes medir calidad de respuesta, latencia, límites de contexto, disponibilidad y facilidad de integración.
¿Qué pasa con los alias deepseek-chat y deepseek-reasoner?
Los alias asociados a integraciones heredadas quedan obsoletos el 24 de julio de 2026. Si tu aplicación aún los usa, conviene planificar la migración y recalcular costes con los identificadores actuales antes de esa fecha.
Recursos adicionales
- Guía principal de DeepSeek en español
- Precios de DeepSeek y modelos disponibles
- Documentación práctica de la API de DeepSeek
- Visión general de DeepSeek V4
- Ficha de DeepSeek V4 Pro
- Ficha de DeepSeek V4 Flash
Conclusión
Calcula el coste de la API de DeepSeek con datos cercanos a tu uso real: tokens medios, caché efectiva, peticiones diarias y días activos. Después crea varios escenarios y revisa el resultado junto con métricas de calidad. Si el presupuesto cambia mucho al ajustar una variable, ahí está tu principal palanca de optimización. Empieza con una estimación conservadora, mide tráfico real y vuelve a la calculadora antes de escalar producción.