
Esta comparativa DeepSeek V4 vs GPT-5.5 enfrenta DeepSeek V4 Pro, con DeepSeek V4 Flash como alternativa secundaria, contra GPT-5.5 en precio, contexto, razonamiento, licencia, API y rendimiento publicado. La decisión no depende solo del mejor benchmark: depende de coste por tarea, privacidad, latencia, salida larga y control sobre el despliegue.

Resumen rápido
- DeepSeek V4 Pro gana en coste por token frente a GPT-5.5 en cargas de texto, agentes y análisis de repositorios grandes.
- GPT-5.5 mantiene ventaja en varios benchmarks publicados por OpenAI, sobre todo Terminal-Bench 2.0, uso de ordenador y tareas profesionales amplias [3].
- DeepSeek V4 Pro tiene pesos abiertos con licencia MIT, algo clave si necesitas auditoría, ajuste, despliegue propio o control de infraestructura [2].
- Ambos llegan a 1M tokens de contexto, pero DeepSeek V4 Pro permite hasta 384K tokens de salida según la documentación de la familia V4 [1].
- DeepSeek V4 Flash es la opción económica para extracción, clasificación, generación masiva y asistentes internos con bajo margen por usuario.
- El veredicto cambia por caso de uso: GPT-5.5 para máxima precisión cerrada y ecosistema OpenAI; DeepSeek V4 Pro para coste, apertura y contexto largo.
Qué es DeepSeek V4 y qué versiones compiten aquí
DeepSeek V4 es la generación de modelos de lenguaje grandes de DeepSeek orientada a contexto largo, razonamiento configurable y costes agresivos por millón de tokens. Para esta comparativa, el rival directo de GPT-5.5 es DeepSeek V4 Pro. DeepSeek V4 Flash aparece como opción secundaria cuando el criterio principal es coste, latencia o volumen.
DeepSeek V4 Pro trabaja con una ventana de contexto de 1M tokens y puede generar hasta 384K tokens de salida. Esto lo hace útil para repositorios completos, documentación extensa, revisión de contratos, análisis de logs y agentes que necesitan conservar mucho estado en una sola llamada.
La familia V4 usa tres modos de razonamiento: non-thinking, thinking-high y thinking-max. El modo thinking-max queda reservado para DeepSeek V4 Pro. En la práctica, conviene usar non-thinking para respuestas rutinarias, thinking-high para análisis técnico y thinking-max para problemas donde el coste adicional compensa.
El rasgo diferencial frente a GPT-5.5 no es solo el precio. DeepSeek V4 Pro publica pesos abiertos bajo licencia MIT, lo que permite despliegues propios, auditoría y adaptación interna. Si necesitas una ruta práctica para probarlo, puedes revisar la documentación de la API o ejecutar una prueba directa desde el chat de DeepSeek.
En la API, DeepSeek mantiene compatibilidad con el formato de OpenAI en https://api.deepseek.com/v1/. Esto facilita migraciones desde aplicaciones que ya usan clientes compatibles con Chat Completions. Los alias heredados deepseek-chat y deepseek-reasoner siguen existiendo por compatibilidad, pero quedarán obsoletos el 24 de julio de 2026.
Qué es GPT-5.5 y qué aporta frente a V4
GPT-5.5 es el modelo insignia de OpenAI para programación, trabajo profesional, razonamiento y uso de herramientas. OpenAI lo posiciona por encima de GPT-5.4, con mejoras en tareas de código, agentes, navegación, contexto largo y evaluaciones académicas [3].
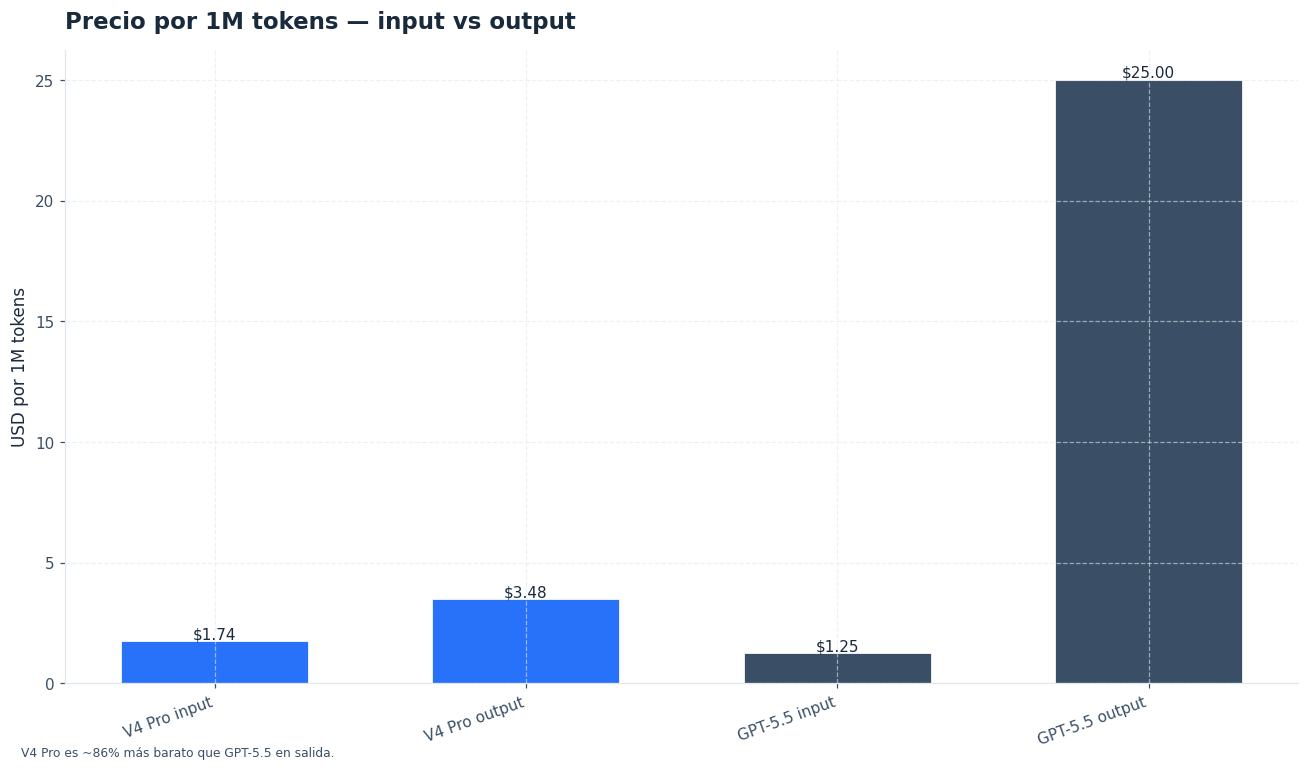
En la API, OpenAI lista gpt-5.5 con precios estándar de $5,00 por 1M tokens de entrada, $0,50 por 1M tokens de entrada cacheada y $30,00 por 1M tokens de salida en contexto corto. Para contexto largo, la tabla oficial sube a $10,00 de entrada, $1,00 de entrada cacheada y $45,00 de salida [4].
Las tarifas pueden cambiar; verifica los importes vigentes en la página de planes y precios antes de presupuestar una integración.
GPT-5.5 Pro también está previsto para tareas de mayor precisión. Su precio oficial es mucho más alto: $30,00 por 1M tokens de entrada y $180,00 por 1M tokens de salida en contexto corto. En contexto largo, sube a $60,00 de entrada y $270,00 de salida [4].
La ventaja principal de GPT-5.5 está en el ecosistema. Si tu producto ya depende de Responses API, herramientas alojadas, modelos multimodales de OpenAI, ChatGPT Enterprise o flujos de Codex, GPT-5.5 reduce fricción operativa. El coste por token es mayor, pero puede compensar si ahorra revisión humana, reintentos o integración.
Por eso, la pregunta DeepSeek V4 vs GPT-5.5 no debería formularse como “cuál es más inteligente” de forma abstracta. La pregunta correcta es qué modelo resuelve tu tarea con menor coste total, latencia aceptable, precisión suficiente y el nivel de control que exige tu organización.
Especificaciones lado a lado
La tabla resume las diferencias prácticas entre DeepSeek V4 Pro, DeepSeek V4 Flash y GPT-5.5. Los datos de DeepSeek se basan en la documentación de la familia V4 y la ficha pública del modelo; los precios de GPT-5.5 se han verificado en la página oficial de OpenAI el 7 de mayo de 2026 [1][2][4].
| Característica | DeepSeek V4 Flash | DeepSeek V4 Pro | GPT-5.5 |
|---|---|---|---|
| Rol principal | Modelo económico y rápido | Modelo V4 principal para razonamiento | Modelo cerrado insignia de OpenAI |
| Contexto | 1M tokens | 1M tokens | 1M tokens en API |
| Salida máxima | Hasta 384K tokens | Hasta 384K tokens | No se debe asumir la misma salida máxima sin revisar el límite de cuenta |
| Razonamiento | non-thinking y thinking-high | non-thinking, thinking-high y thinking-max | Razonamiento avanzado gestionado por OpenAI |
| Pesos | Abiertos | Abiertos | Cerrados |
| Licencia | MIT | MIT | Propietaria |
| API | Compatible con OpenAI | Compatible con OpenAI | API nativa de OpenAI |
| Mejor encaje | Volumen, extracción, clasificación, asistentes internos | Código, agentes, contexto largo, razonamiento coste-eficiente | Flujos OpenAI, precisión alta, herramientas integradas |
DeepSeek V4 Pro no intenta ganar solo por ficha técnica. Su propuesta es combinar contexto largo, salida extensa, pesos abiertos y precio inferior. GPT-5.5 compite desde otro ángulo: rendimiento cerrado, integración con herramientas de OpenAI y una ruta empresarial más consolidada.
Si tu aplicación vive dentro del ecosistema OpenAI, GPT-5.5 puede ser más sencillo de adoptar. Si tu equipo quiere independencia de proveedor, control de costes o despliegue alternativo, la balanza se inclina hacia DeepSeek V4 Pro.
Benchmarks: lectura técnica y límites de comparación
Los benchmarks publicados muestran una competición ajustada, pero no todos miden lo mismo. OpenAI publica resultados de GPT-5.5 en SWE-Bench Pro, Terminal-Bench 2.0, GDPval, OSWorld-Verified, BrowseComp, GPQA Diamond y pruebas de contexto largo [3]. DeepSeek publica resultados de DeepSeek V4 Pro Max frente a modelos frontera en programación, razonamiento, tareas agentivas y contexto largo [2].
| Benchmark | Qué mide | DeepSeek V4 Pro Max | GPT-5.5 | Lectura rápida |
|---|---|---|---|---|
| SWE-Bench Pro | Resolución de incidencias complejas de software | 55,4 % | 58,6 % | GPT-5.5 gana por margen moderado |
| Terminal-Bench 2.0 | Uso de terminal y tareas agentivas de código | 67,9 % | 82,7 % | Ventaja clara para GPT-5.5 |
| GPQA Diamond | Preguntas científicas difíciles | 90,1 % | 93,6 % | GPT-5.5 queda por delante |
| BrowseComp | Búsqueda y uso de información | 83,4 % | 84,4 % | Empate práctico |
| Toolathlon | Uso de herramientas | 51,8 % | 55,6 % | GPT-5.5 conserva ventaja |
| MRCR 1M / contexto largo | Recuperación en contexto amplio | 83,5 MMR | OpenAI publica Graphwalks y MRCR propios | No es una comparación directa perfecta |
La lectura responsable es clara: GPT-5.5 supera a DeepSeek V4 Pro en varios benchmarks publicados donde hay comparabilidad razonable. La ventaja más visible está en Terminal-Bench 2.0, lo que importa si tu agente ejecuta comandos, edita archivos, prueba código y decide pasos sucesivos.
DeepSeek V4 Pro mantiene una posición fuerte en SWE-Bench Pro, BrowseComp, MCPAtlas y pruebas de código. En esos casos, la diferencia de calidad puede ser menor que la diferencia de coste. Para muchos productos, un modelo algo menos dominante pero varias veces más barato produce mejor margen.
También conviene separar benchmark de producción. Un benchmark mide una muestra cerrada bajo una configuración concreta. Tu aplicación puede depender más de formato JSON estable, coste de reintentos, latencia por región, seguridad, instrucciones del sistema o calidad en español. Por tanto, antes de elegir entre DeepSeek V4 y GPT-5.5, ejecuta una evaluación propia con tus prompts reales.
Coste real: ejemplo trabajado con caché
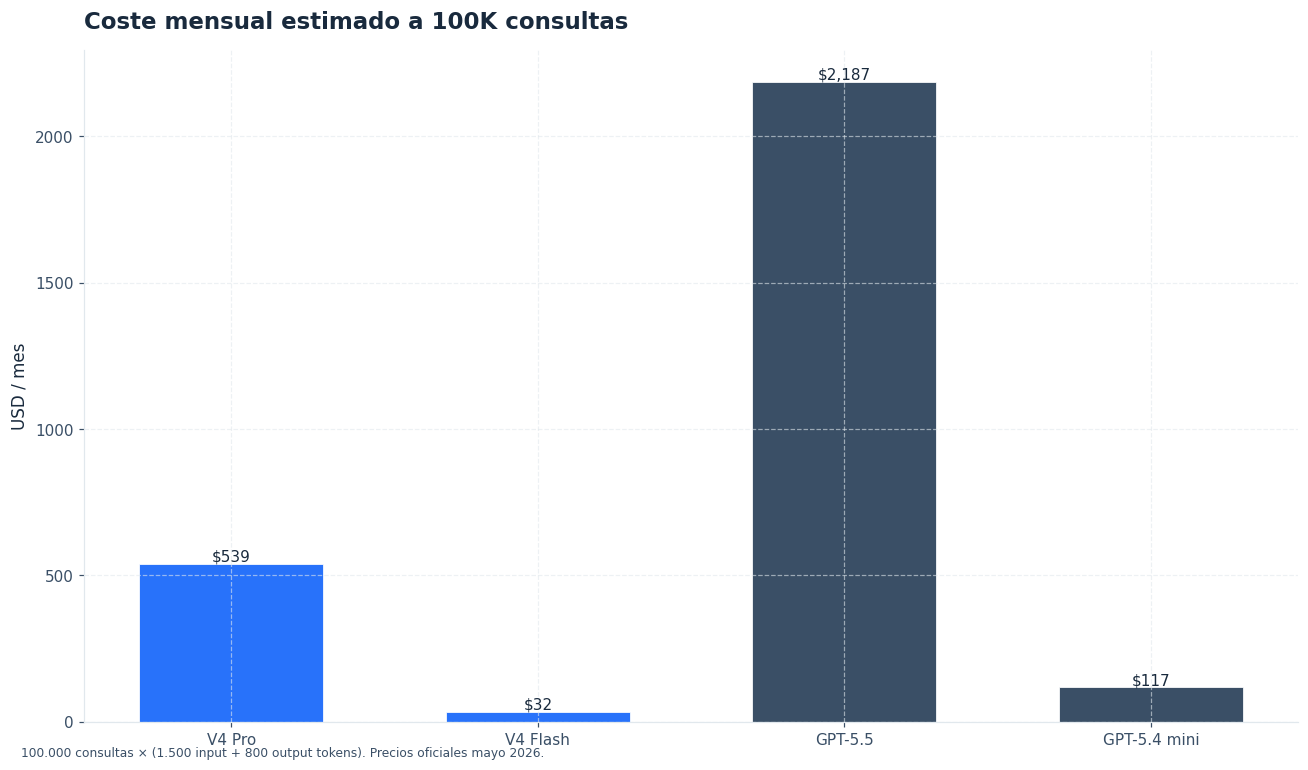
El coste cambia mucho cuando hay contexto repetido. Piensa en un asistente para soporte técnico con documentación fija, políticas internas y una conversación por usuario. Supongamos 100.000 llamadas mensuales, 10.000 tokens de entrada por llamada y 1.000 tokens de salida. Eso equivale a 1.000M tokens de entrada y 100M tokens de salida al mes.
Si el 70 % de la entrada se sirve como caché, el cálculo queda así: 300M tokens de entrada no cacheada, 700M tokens de entrada cacheada y 100M tokens de salida. La tabla usa las tarifas de referencia indicadas para DeepSeek V4 y la tarifa estándar oficial de GPT-5.5 en contexto corto [4]. Para revisar cambios, consulta la página de precios de DeepSeek.
| Modelo | Entrada no cacheada | Entrada cacheada | Salida | Coste mensual estimado |
|---|---|---|---|---|
| DeepSeek V4 Flash | 300 × $0,14 = $42,00 | 700 × $0,028 = $19,60 | 100 × $0,28 = $28,00 | $89,60 |
| DeepSeek V4 Pro | 300 × $1,74 = $522,00 | 700 × $0,87 = $609,00 | 100 × $3,48 = $348,00 | $1.479,00 |
| GPT-5.5 | 300 × $5,00 = $1.500,00 | 700 × $0,50 = $350,00 | 100 × $30,00 = $3.000,00 | $4.850,00 |
| GPT-5.5 contexto largo | 300 × $10,00 = $3.000,00 | 700 × $1,00 = $700,00 | 100 × $45,00 = $4.500,00 | $8.200,00 |
Este ejemplo muestra por qué DeepSeek V4 vs GPT-5.5 es una decisión económica antes que filosófica. Con la carga descrita, DeepSeek V4 Pro cuesta cerca del 30,5 % de GPT-5.5 estándar. DeepSeek V4 Flash cae a menos del 2 % de GPT-5.5, aunque no compite en la misma liga de razonamiento.
La salida pesa mucho. GPT-5.5 cobra $30,00 por 1M tokens de salida, así que los agentes verbosos, los generadores de informes y los sistemas que producen código largo pueden disparar el gasto. DeepSeek V4 Pro es más interesante cuando la aplicación genera muchas respuestas extensas o trabaja con contexto repetido.
OpenAI ofrece modos Batch y Flex con descuentos frente al precio estándar, y Priority con prima de coste [4]. Aun así, para cargas constantes y no interactivas conviene comparar Batch de OpenAI contra colas propias, caché agresiva y DeepSeek V4 Flash. La arquitectura de producto pesa tanto como el precio por token.
Ejemplo cURL: probar DeepSeek V4 Pro con API compatible
Si ya tienes una integración compatible con OpenAI, el cambio suele concentrarse en la URL base, el identificador del modelo y la clave. Este ejemplo usa deepseek-v4-pro con el endpoint compatible:
curl https://api.deepseek.com/v1/chat/completions \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-v4-pro",
"messages": [
{
"role": "system",
"content": "Responde en español técnico, con pasos verificables."
},
{
"role": "user",
"content": "Analiza este plan de migración y detecta riesgos de arquitectura."
}
],
"temperature": 0.2,
"max_tokens": 4000
}'Para una evaluación justa, no pruebes solo una conversación. Crea un conjunto de 50 a 200 tareas reales: incidencias de código, tickets de soporte, documentos largos, consultas en español y casos límite. Mide coste, acierto, formato, latencia, tasa de reintentos y revisión humana.
También conviene probar DeepSeek V4 Flash en paralelo. En muchos sistemas, Flash puede resolver el 70 % u 80 % de las peticiones y escalar a V4 Pro solo cuando la tarea supera un umbral. Esa combinación suele ganar en coste frente a usar GPT-5.5 para todo.
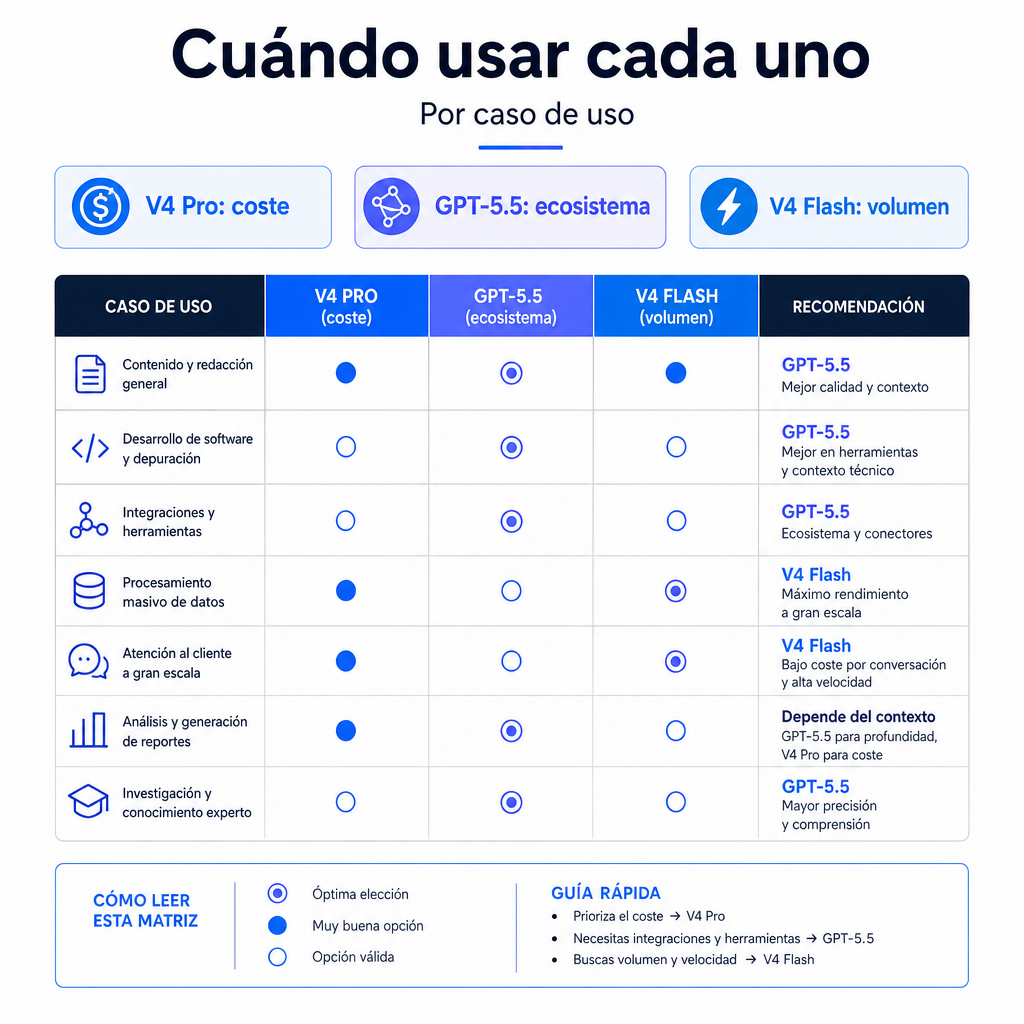
Cuándo usar cada modelo
El veredicto por caso de uso es más útil que una clasificación única. Un modelo puede ganar en benchmarks y perder en margen bruto. Otro puede ser más barato y no alcanzar la precisión necesaria en tareas de alto riesgo.
Usa DeepSeek V4 Pro si el contexto largo es central
DeepSeek V4 Pro encaja bien cuando necesitas leer repositorios completos, manuales, contratos, expedientes, transcripciones extensas o bases de conocimiento grandes. Su combinación de 1M tokens de contexto, salida larga y precio bajo por salida ayuda a contener el coste.
Usa GPT-5.5 si dependes del ecosistema OpenAI
GPT-5.5 es una opción sólida si ya usas herramientas de OpenAI, flujos de ChatGPT Enterprise, integraciones de Codex o componentes alojados. En ese escenario, cambiar de proveedor puede costar más que el ahorro por token.
Usa DeepSeek V4 Flash para volumen
DeepSeek V4 Flash es adecuado para clasificación, extracción, transformación de texto, resúmenes internos y respuestas de baja complejidad. También funciona como primera capa antes de escalar a V4 Pro o GPT-5.5.
Usa GPT-5.5 para agentes de terminal exigentes
Los resultados publicados de Terminal-Bench 2.0 favorecen a GPT-5.5 [3]. Si tu producto ejecuta comandos, corrige errores, interpreta salidas y decide planes largos sin supervisión, ese margen puede justificar el coste.
Usa DeepSeek V4 Pro si necesitas pesos abiertos
La licencia MIT cambia la discusión. Si tu organización necesita auditoría, despliegue propio, adaptación interna o menor dependencia de un proveedor cerrado, DeepSeek V4 Pro ofrece una ruta que GPT-5.5 no cubre.
Si estás empezando desde cero, revisa primero DeepSeek en español, compara planes en la página de precios y ejecuta una prueba corta desde DeepSeek Chat. Después, replica la misma batería de prompts contra GPT-5.5.
Veredicto: DeepSeek V4 vs GPT-5.5 por caso de uso
Para generación masiva, extracción de datos y asistentes internos, gana DeepSeek V4 Flash por coste. Para programación, análisis largo y agentes con presupuesto sensible, gana DeepSeek V4 Pro salvo que Terminal-Bench 2.0 sea representativo de tu producto. Para flujos ya integrados en OpenAI, máxima comodidad empresarial y herramientas alojadas, gana GPT-5.5.
En productos con margen ajustado, DeepSeek V4 Pro suele ser la primera evaluación razonable. En productos donde cada error cuesta mucho, GPT-5.5 merece una prueba frontal. El resultado final no debería salir de una tabla pública, sino de una evaluación con tus datos, tus idiomas, tus límites de latencia y tus costes de revisión.
Preguntas frecuentes
¿DeepSeek V4 Pro es mejor que GPT-5.5?
No de forma universal. GPT-5.5 gana en varios benchmarks publicados, especialmente en Terminal-Bench 2.0. DeepSeek V4 Pro compite mejor cuando el coste, la salida larga, los pesos abiertos y el contexto de 1M tokens pesan más que unos puntos de benchmark.
¿Cuál es más barato, DeepSeek V4 o GPT-5.5?
DeepSeek V4 es más barato por token en los escenarios habituales de texto. En el ejemplo de 100.000 llamadas mensuales, DeepSeek V4 Pro queda en $1.479,00 frente a $4.850,00 de GPT-5.5 estándar. DeepSeek V4 Flash baja hasta $89,60.
¿GPT-5.5 tiene también 1M tokens de contexto?
Sí. OpenAI indica una ventana de contexto de 1M tokens para gpt-5.5 en API, con precios diferenciados para contexto corto y contexto largo [3][4]. Antes de producción, revisa los límites concretos de tu cuenta y endpoint.
¿DeepSeek V4 permite despliegue propio?
Sí, los pesos de DeepSeek V4 Pro y Flash están publicados con licencia MIT [2]. El despliegue propio de V4 Pro exige hardware serio, así que muchas organizaciones empiezan con API y evalúan despliegue propio solo si hay requisitos de control o volumen.
¿Cuál elegir para programar?
Para agentes de terminal autónomos, GPT-5.5 tiene ventaja clara en Terminal-Bench 2.0. Para revisión de código, generación asistida, análisis de repositorios grandes y coste por tarea, DeepSeek V4 Pro puede ser mejor elección. La prueba debe usar incidencias reales de tu repositorio.
Conclusión
La comparativa DeepSeek V4 vs GPT-5.5 no tiene un ganador único. GPT-5.5 es fuerte si necesitas el mejor rendimiento cerrado, herramientas de OpenAI y mínima fricción empresarial. DeepSeek V4 Pro es más atractivo si priorizas coste, contexto largo, salida extensa y pesos abiertos. El siguiente paso práctico es crear una evaluación con tus tareas reales, medir coste por resolución correcta y probar una arquitectura híbrida: Flash para volumen, V4 Pro para razonamiento y GPT-5.5 solo donde su ventaja justifique el precio.
Fuentes
’]