
DeepSeek V4 es la familia de modelos lanzada el 24 de abril de 2026 para cubrir dos necesidades distintas: máxima calidad con DeepSeek V4 Pro y baja latencia con DeepSeek V4 Flash. Importa porque combina contexto de 1M tokens, pesos abiertos con licencia MIT y una API compatible con OpenAI para migrar aplicaciones con menos fricción.

Resumen rápido
- DeepSeek V4 agrupa dos modelos principales: DeepSeek V4 Pro para tareas exigentes y DeepSeek V4 Flash para volumen, coste y velocidad.
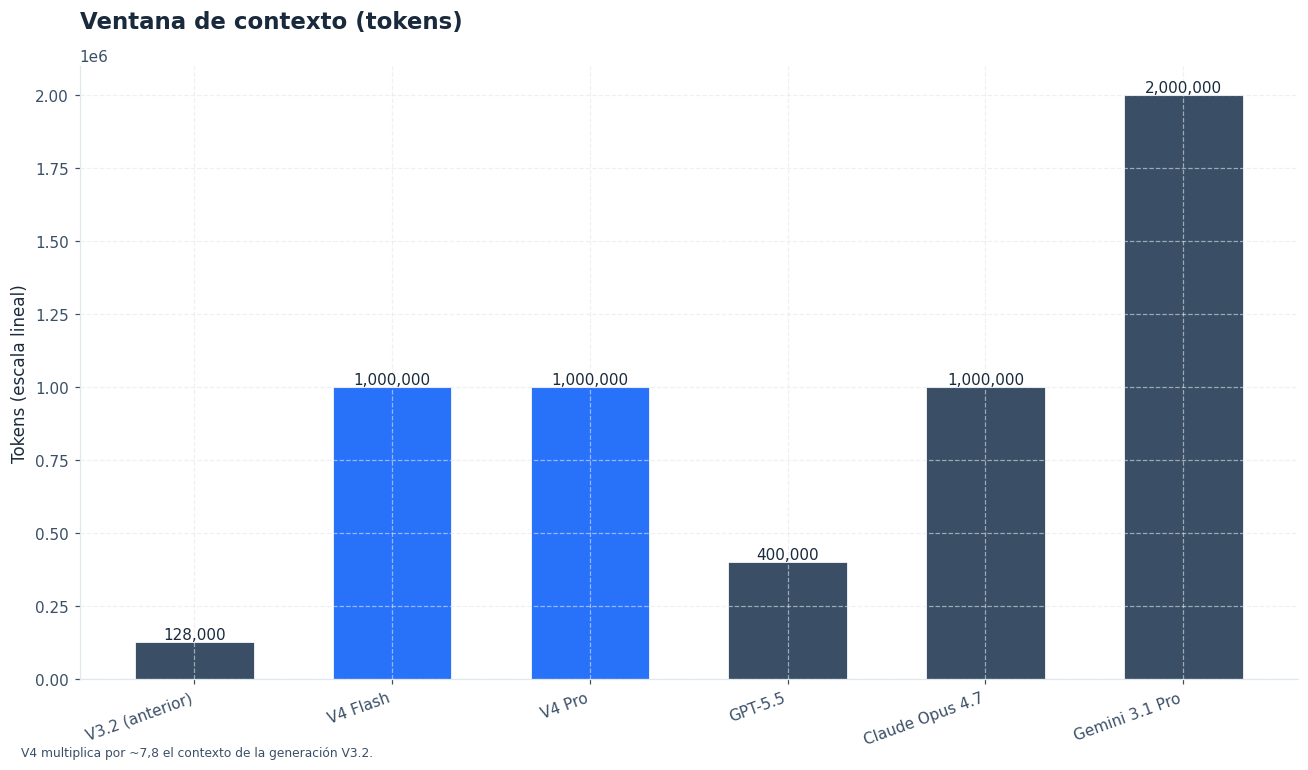
- Ambos modelos usan una ventana de contexto de 1M tokens, útil para bases de código, historiales largos, contratos y documentación extensa.
- DeepSeek V4 Pro añade el modo
thinking-max, pensado para razonamiento más profundo cuando la precisión pesa más que la latencia. - DeepSeek V4 Flash cuesta $0,14 por 1M tokens de entrada y $0,28 por 1M tokens de salida; Pro cuesta $1,74 y $3,48, respectivamente.
- La API es compatible con OpenAI y se usa desde
https://api.deepseek.com/v1/, así que muchas integraciones pueden cambiar solo la URL base y el identificador del modelo. - Los alias antiguos
deepseek-chatydeepseek-reasonerquedan obsoletos el 24 de julio de 2026; conviene migrar a los nuevos identificadores antes de esa fecha.
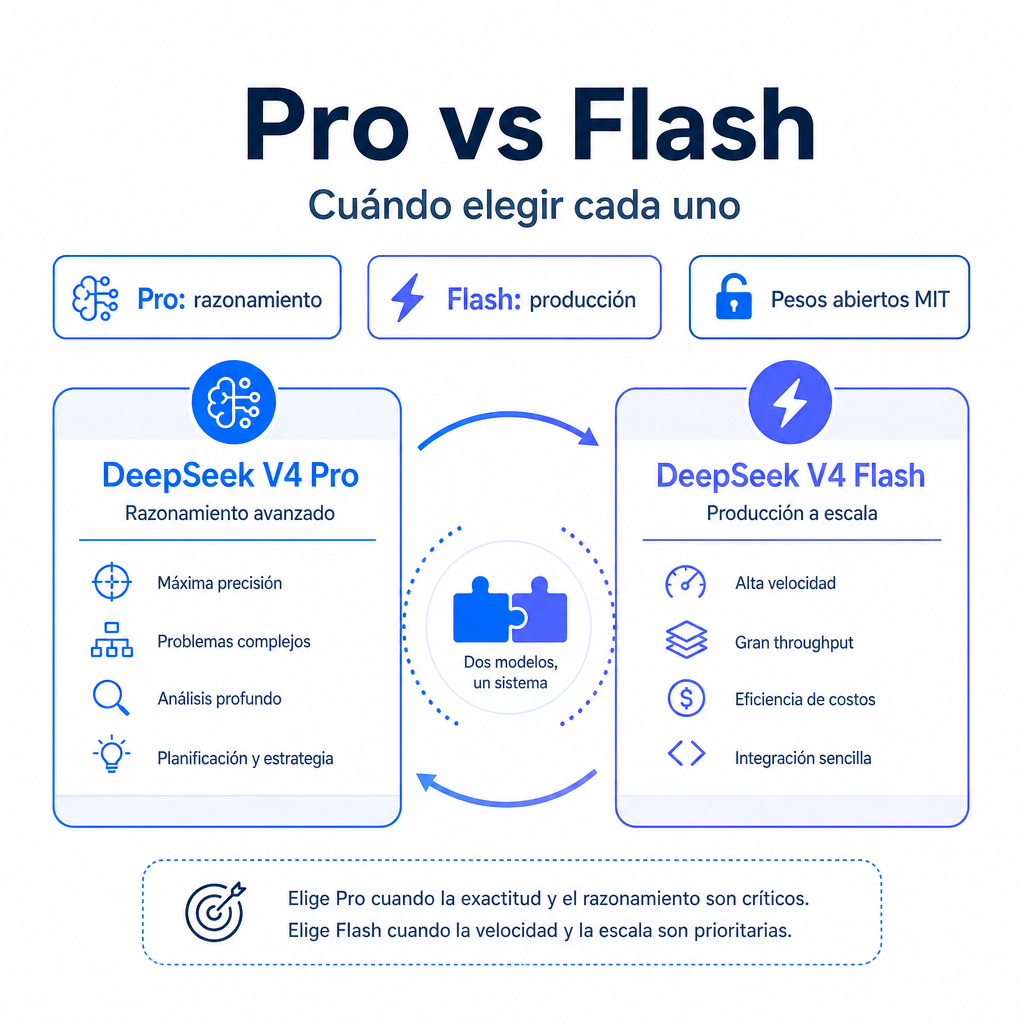
¿Qué es DeepSeek V4?
DeepSeek V4 es la nueva generación de modelos de DeepSeek y funciona como una familia, no como un único modelo. La idea central es separar dos perfiles de uso: un modelo Pro para tareas donde la calidad es prioritaria y un modelo Flash para aplicaciones que necesitan muchas respuestas rápidas a bajo coste.
DeepSeek V4 Pro está orientado a programación compleja, razonamiento multietapa, análisis documental largo y agentes que necesitan mantener coherencia durante muchas acciones. DeepSeek V4 Flash busca una respuesta más económica para asistentes, clasificación, extracción de datos, generación de contenido operativo y flujos con alto volumen de peticiones.
La familia mantiene una ventana de contexto de 1M tokens. Esto cambia el diseño de muchas aplicaciones: puedes enviar repositorios amplios, documentación completa o historiales de soporte largos sin trocearlos de forma agresiva. Aun así, una ventana grande no elimina la necesidad de preparar buenos prompts, limpiar datos duplicados y controlar costes.
Otro punto clave es la licencia MIT para los pesos abiertos. Para equipos técnicos, esto significa más margen para auditoría, despliegues propios y experimentación, aunque la API alojada sigue siendo la vía más sencilla para producción. Si quieres probarlo sin configurar infraestructura, puedes empezar desde DeepSeek Chat o revisar la documentación de la API.
Capacidades y casos de uso
DeepSeek V4 cubre varios escenarios donde una familia de modelos resulta más práctica que un único modelo generalista. La elección depende del equilibrio entre coste, latencia, profundidad de razonamiento y volumen de uso.
Programación y revisión de código
DeepSeek V4 Pro encaja mejor cuando el sistema debe leer varios archivos, localizar dependencias y proponer cambios con impacto limitado. Por ejemplo, puede analizar una regresión en un monorepo, explicar por qué falla una prueba y sugerir un parche con pasos de verificación. Para tareas más repetitivas, como generar pruebas unitarias sencillas o documentar funciones, DeepSeek V4 Flash puede reducir el coste por ejecución.
Análisis de documentos largos
La ventana de 1M tokens permite trabajar con contratos extensos, informes financieros, documentación técnica y expedientes internos. Un caso típico es cargar un conjunto de políticas corporativas y pedir una matriz de obligaciones, riesgos y excepciones. Pro conviene cuando hay ambigüedad legal o técnica; Flash basta para extracción estructurada y resúmenes controlados.
Agentes con herramientas
Los modos de razonamiento ayudan a ajustar cuánto esfuerzo dedica el modelo antes de actuar. En un agente de soporte, Flash puede clasificar incidencias, consultar una base de conocimiento y redactar respuestas. Pro puede reservarse para escalados donde el agente debe comparar logs, historial de cambios y políticas internas antes de recomendar una acción.
Automatización de contenido y datos
Para flujos de alto volumen, DeepSeek V4 Flash es la opción natural. Sirve para normalizar catálogos, etiquetar conversaciones, generar borradores, convertir texto libre en JSON y crear variantes de mensajes. El precio de caché de entrada, especialmente en Flash, permite ahorrar cuando muchas peticiones comparten instrucciones, taxonomías o documentación base.
Especificaciones técnicas
La tabla resume los datos verificados para la familia DeepSeek V4. Los precios están expresados por 1M tokens y en USD. Para calcular escenarios concretos, consulta también la página de precios de DeepSeek.
| Modelo | Parámetros | Contexto | Modos de razonamiento | Precio de entrada | Precio de salida | Precio de entrada con acierto de caché |
|---|---|---|---|---|---|---|
| DeepSeek V4 Flash | No publicado en los datos verificados de esta página | 1M tokens | non-thinking, thinking-high | $0,14 / 1M tokens | $0,28 / 1M tokens | $0,028 / 1M tokens |
| DeepSeek V4 Pro | No publicado en los datos verificados de esta página | 1M tokens; hasta 384K tokens de salida | non-thinking, thinking-high, thinking-max | $1,74 / 1M tokens | $3,48 / 1M tokens | $0,87 / 1M tokens |
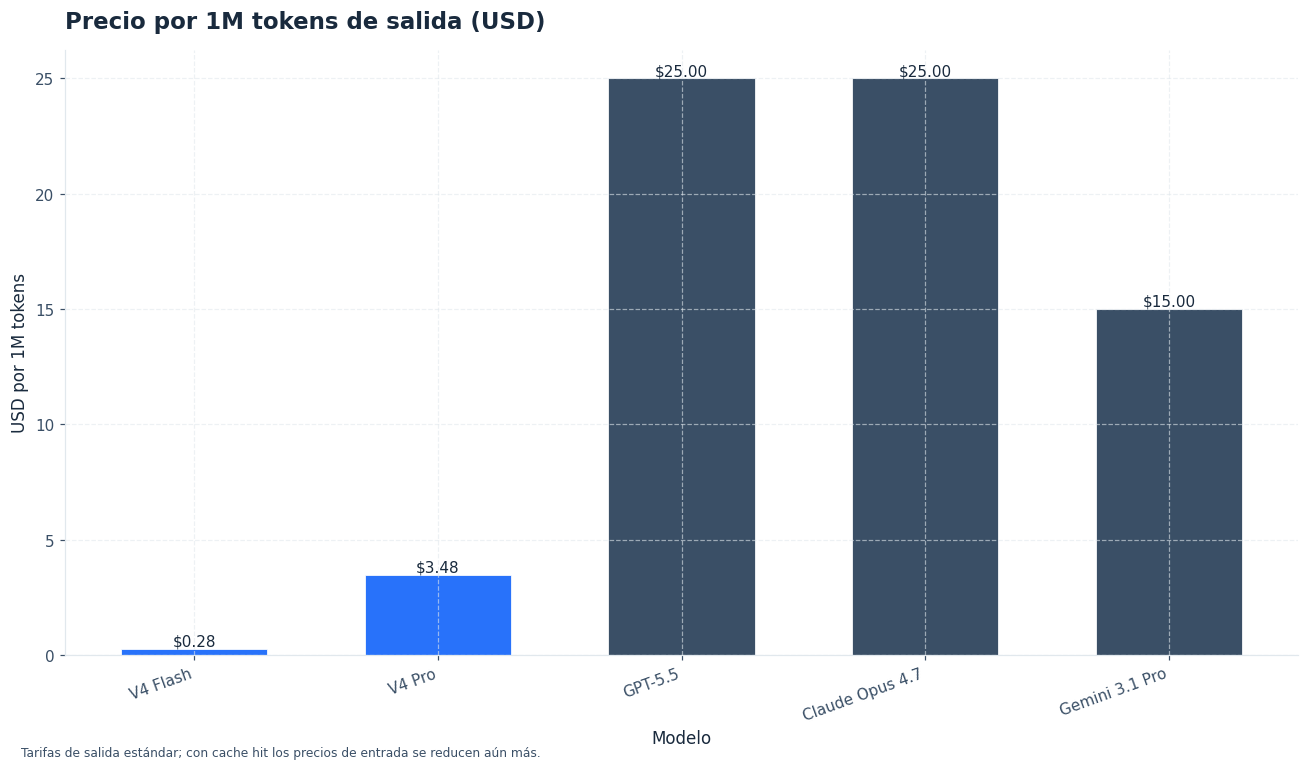
Como referencia externa, OpenAI publicó GPT-5.5 con 1M tokens de contexto y precio previsto de $5 por 1M tokens de entrada y $30 por 1M tokens de salida en la API. Anthropic lista Claude Opus 4.7 con 1M tokens de contexto y precios desde $5 y $25 por 1M tokens, respectivamente. ([openai.com](https://openai.com/index/introducing-gpt-5-5/))
Las tarifas pueden cambiar; verifica los importes vigentes en la página de planes y precios antes de presupuestar una integración.
Cómo usar la API
La API de DeepSeek V4 es compatible con el formato de OpenAI. En una integración existente, normalmente debes cambiar la URL base, el identificador del modelo y añadir el parámetro thinking cuando quieras controlar el modo de razonamiento.
curl https://api.deepseek.com/v1/chat/completions \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-v4-pro",
"thinking": "thinking-max",
"messages": [
{
"role": "system",
"content": "Responde con precisión y muestra supuestos relevantes."
},
{
"role": "user",
"content": "Analiza este plan de migración y detecta riesgos técnicos."
}
]
}'
curl https://api.deepseek.com/v1/chat/completions \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-v4-flash",
"thinking": "thinking-high",
"messages": [
{
"role": "user",
"content": "Extrae los campos clave de este texto y devuelve JSON válido."
}
]
}'Usa thinking-max solo con DeepSeek V4 Pro. Para respuestas simples, non-thinking reduce latencia y coste. Para tareas con varios pasos, thinking-high suele ser el punto medio antes de escalar a Pro.
from openai import OpenAI
client = OpenAI(
api_key="DEEPSEEK_API_KEY",
base_url="https://api.deepseek.com/v1/"
)
response = client.chat.completions.create(
model="deepseek-v4-pro",
thinking="thinking-high",
messages=[
{"role": "user", "content": "Resume este contrato y enumera riesgos."}
]
)
print(response.choices[0].message.content)Comparativa rápida
Para una página pilar, la comparación más útil es interna: elegir entre DeepSeek V4 Pro y DeepSeek V4 Flash. Las alternativas cerradas cambian rápido, así que conviene verificarlas antes de fijar una arquitectura. OpenAI lista GPT-5.4 mini con 400K tokens de contexto, 128K tokens de salida máxima y precio de $0,75 / $4,50 por 1M tokens; Anthropic presenta Claude Sonnet 4.6 con 1M tokens de contexto en beta de la API y precio desde $3 / $15 por 1M tokens. ([developers.openai.com](https://developers.openai.com/api/docs/models/gpt-5.4-mini))
| Criterio | DeepSeek V4 Pro | DeepSeek V4 Flash |
|---|---|---|
| Uso principal | Razonamiento complejo, programación avanzada, análisis largo y agentes críticos | Alto volumen, baja latencia, extracción, clasificación y asistentes cotidianos |
| Contexto | 1M tokens | 1M tokens |
| Salida máxima indicada | Hasta 384K tokens | No indicada en los datos verificados de esta página |
| Razonamiento | non-thinking, thinking-high, thinking-max | non-thinking, thinking-high |
| Precio de entrada | $1,74 / 1M tokens | $0,14 / 1M tokens |
| Precio de salida | $3,48 / 1M tokens | $0,28 / 1M tokens |
| Cuándo elegirlo | Cuando un error sale caro o la tarea exige razonamiento profundo | Cuando necesitas muchas respuestas buenas con coste muy bajo |
Una estrategia habitual es usar Flash como modelo por defecto y enrutar a Pro solo cuando una petición supera un umbral de complejidad. Puedes definir ese umbral por longitud del contexto, presencia de código, riesgo del dominio o baja confianza de una primera respuesta.
Limitaciones y consideraciones
DeepSeek V4 no elimina los problemas habituales de los modelos de lenguaje grandes (LLM). Puede producir respuestas plausibles pero incorrectas, interpretar mal instrucciones ambiguas o depender demasiado de patrones presentes en el contexto. En aplicaciones con impacto legal, médico, financiero o de seguridad, debes validar la salida con reglas, revisión humana o pruebas automáticas.
La ventana de 1M tokens tampoco debe usarse como excusa para enviar todo sin filtrar. Más contexto aumenta el coste, puede introducir ruido y complica la trazabilidad de la respuesta. Conviene aplicar recuperación selectiva, deduplicación y plantillas de entrada estables.
El modo thinking-max aporta más esfuerzo de razonamiento, pero no siempre mejora una tarea simple. Úsalo para problemas difíciles y mide latencia, coste y tasa de acierto. Si el flujo necesita respuestas inmediatas, DeepSeek V4 Flash con non-thinking puede ser más adecuado que Pro con razonamiento alto.
Migración desde versiones previas
Si vienes de DeepSeek V3.2, deepseek-chat o deepseek-reasoner, planifica la migración antes del 24 de julio de 2026. Sustituye los alias heredados por deepseek-v4-flash o deepseek-v4-pro, revisa el parámetro thinking y vuelve a ejecutar tus pruebas de calidad.
Para una guía paso a paso, usa la comparativa DeepSeek V4 vs V3.2: migración. Después revisa precios y límites en la documentación de la API antes de pasar tráfico de producción.
Preguntas frecuentes
¿DeepSeek V4 es un único modelo?
No. DeepSeek V4 es una familia con dos variantes principales: DeepSeek V4 Pro y DeepSeek V4 Flash. Pro prioriza razonamiento y calidad; Flash prioriza coste, velocidad y escalabilidad.
¿Qué modelo debería usar por defecto?
Para la mayoría de aplicaciones de alto volumen, empieza con DeepSeek V4 Flash. Usa DeepSeek V4 Pro cuando necesites razonamiento más profundo, análisis de código complejo, decisiones con más riesgo o el modo thinking-max.
¿DeepSeek V4 Pro y Flash tienen el mismo contexto?
Sí. Ambos modelos trabajan con una ventana de contexto de 1M tokens. La diferencia está en el coste, los modos de razonamiento y la orientación de uso.
¿La API de DeepSeek V4 es compatible con OpenAI?
Sí. La API utiliza una ruta compatible con OpenAI en https://api.deepseek.com/v1/. En muchos casos puedes reutilizar clientes existentes cambiando la URL base, la clave y el nombre del modelo.
¿Cuándo quedan obsoletos deepseek-chat y deepseek-reasoner?
Los alias deepseek-chat y deepseek-reasoner quedan obsoletos el 24 de julio de 2026. Migra antes a deepseek-v4-flash o deepseek-v4-pro para evitar cambios inesperados.
Conclusión
DeepSeek V4 es la base actual para construir con DeepSeek: Flash cubre el uso diario a bajo coste y Pro queda para tareas donde necesitas más razonamiento. La ruta recomendada es simple: prueba Flash primero, mide calidad y latencia, y escala a Pro solo en peticiones complejas. Empieza desde la página principal, consulta la API y compara costes en precios antes de migrar a producción.
Fuentes
’]