
DeepSeek OCR es el modelo de DeepSeek orientado al reconocimiento óptico de caracteres: extrae texto y estructura desde imágenes de documentos, capturas, escaneos y páginas de PDF convertidas a imagen. No sustituye a DeepSeek V4, DeepSeek V4 Flash ni DeepSeek V4 Pro para chat general; encaja mejor como capa de lectura visual antes de enviar el texto a un LLM.
Resumen rápido
- DeepSeek OCR es un modelo especializado en OCR y comprensión documental, no un asistente conversacional general.
- El modelo acepta imágenes como entrada y puede generar texto plano, Markdown o salidas con información de disposición mediante prompts.
- Según el informe técnico, el entrenamiento incluyó documentos en cerca de 100 idiomas; para OCR en escenas naturales, el foco principal fue chino e inglés [1].
- En OmniDocBench, DeepSeek OCR se evalúa con distancias de edición, no con CER puro; cuanto menor es el valor, mejor es el resultado [1].
- Para los PDF, el flujo práctico suele consistir en convertir cada página a imagen y después procesarla con DeepSeek OCR.
- La API oficial de DeepSeek lista DeepSeek V4 Flash y DeepSeek V4 Pro, pero no DeepSeek OCR como modelo servido en la API pública general a 7 de mayo de 2026 [4].
Qué es DeepSeek OCR y cuándo usarlo
DeepSeek OCR es un modelo de visión-lenguaje centrado en convertir contenido visual con texto en contenido digital utilizable. Su nombre oficial en Hugging Face es deepseek-ai/DeepSeek-OCR, está etiquetado como modelo image-text-to-text, multilingüe y con licencia MIT [2].
El caso de uso principal es leer documentos que no llegan como texto limpio. En la práctica, esto incluye fotografías de recibos, facturas escaneadas, capturas de pantalla, páginas de informes, notas manuscritas simples, tablas y documentos con fórmulas. También puede trabajar con páginas de PDF cuando se renderizan como imágenes.
La diferencia frente a un LLM general es clara. DeepSeek OCR está optimizado para reconocer y reconstruir texto desde píxeles. Para redactar, razonar sobre varios documentos, generar código o mantener una conversación, tiene más sentido usar DeepSeek en chat o un modelo de la familia V4 mediante la API de DeepSeek.
El flujo más robusto suele ser de dos pasos. Primero, DeepSeek OCR extrae el texto y la estructura. Después, DeepSeek V4 Flash o DeepSeek V4 Pro analiza, resume, clasifica o convierte ese texto a JSON. Esta separación reduce errores y facilita auditar qué parte del sistema leyó el documento.
Capacidades principales del modelo
DeepSeek OCR combina un codificador visual llamado DeepEncoder con un decodificador DeepSeek3B-MoE-A570M. El informe técnico lo presenta como una investigación sobre compresión óptica de contexto: usar tokens visuales para representar documentos con menos tokens que el texto equivalente [1].
Esta idea es útil para OCR porque una página escaneada concentra mucha información visual: bloques de texto, tablas, fórmulas, pies de página, columnas y marcas de disposición. El modelo puede recibir una imagen y devolver una representación textual más manejable para indexación, búsqueda o análisis posterior.
En los ejemplos oficiales se usan prompts como <image>\nFree OCR., <image>\n<|grounding|>Convert the document to markdown. y <image>\n<|grounding|>OCR this image. [2]. Esto permite adaptar la salida: texto libre, Markdown con estructura o extracción más orientada a disposición.
DeepSeek OCR también incluye capacidades de «OCR 2.0» en el informe técnico. Ese bloque cubre tareas como análisis de gráficos, fórmulas químicas y geometría simple. Conviene tratar esas salidas como extracción asistida, no como datos contables o científicos validados sin revisión humana.
| Aspecto | Dato verificado | Implicación práctica |
|---|---|---|
| Modelo | deepseek-ai/DeepSeek-OCR | Se usa desde Hugging Face, Transformers o despliegues compatibles. |
| Tipo | Imagen a texto | Entrada visual; salida textual o estructurada por prompt. |
| Licencia | MIT [2] | Permite despliegues propios con revisión legal interna. |
| Tamaño | 3B parámetros, BF16 en Hugging Face [2] | Más viable para infraestructura propia que un VLM de frontera. |
| Resoluciones nativas | 512, 640, 1024 y 1280 píxeles [3] | Permite equilibrar coste, velocidad y calidad. |
| Modo dinámico | Gundam: mosaicos de 640 más vista global de 1024 [3] | Útil para periódicos, informes densos y páginas grandes. |
| Idiomas | Cerca de 100 idiomas para documentos PDF en entrenamiento [1] | Buena base multilingüe; prueba tus idiomas reales antes de producción. |
Entrada, salida y preparación de PDF
DeepSeek OCR trabaja con imágenes. En el código oficial de Transformers, la entrada se pasa como image_file = 'your_image.jpg'; en vLLM se prepara cada imagen con PIL y se envía como dato multimodal [2]. Para los PDF, el repositorio oficial incluye una ruta de inferencia específica, pero el patrón operativo sigue siendo renderizar páginas y tratarlas como imágenes [3].
Antes de procesar documentos, conviene normalizar el archivo. Un PDF digital puede contener texto embebido que se extrae mejor con herramientas nativas. Un PDF escaneado, en cambio, necesita OCR. Si no distingues ambos casos, gastarás recursos leyendo con visión algo que ya estaba disponible como texto.
Para fotografías de móvil, el preprocesado importa. Recorta márgenes excesivos, corrige rotación, aumenta contraste y evita compresión agresiva. En recibos y facturas, una imagen borrosa puede cambiar importes, fechas o identificadores. En documentos legales o fiscales, guarda siempre la imagen original junto a la salida del modelo.
La salida puede ser texto plano cuando solo interesa el contenido. Para informes, manuales o artículos con tablas, Markdown suele ser más útil. Si necesitas campos concretos, por ejemplo invoice_number, date y total, lo más seguro es extraer primero el texto y pedir a un modelo V4 que genere JSON validado después.
Rendimiento: benchmarks y límites medidos
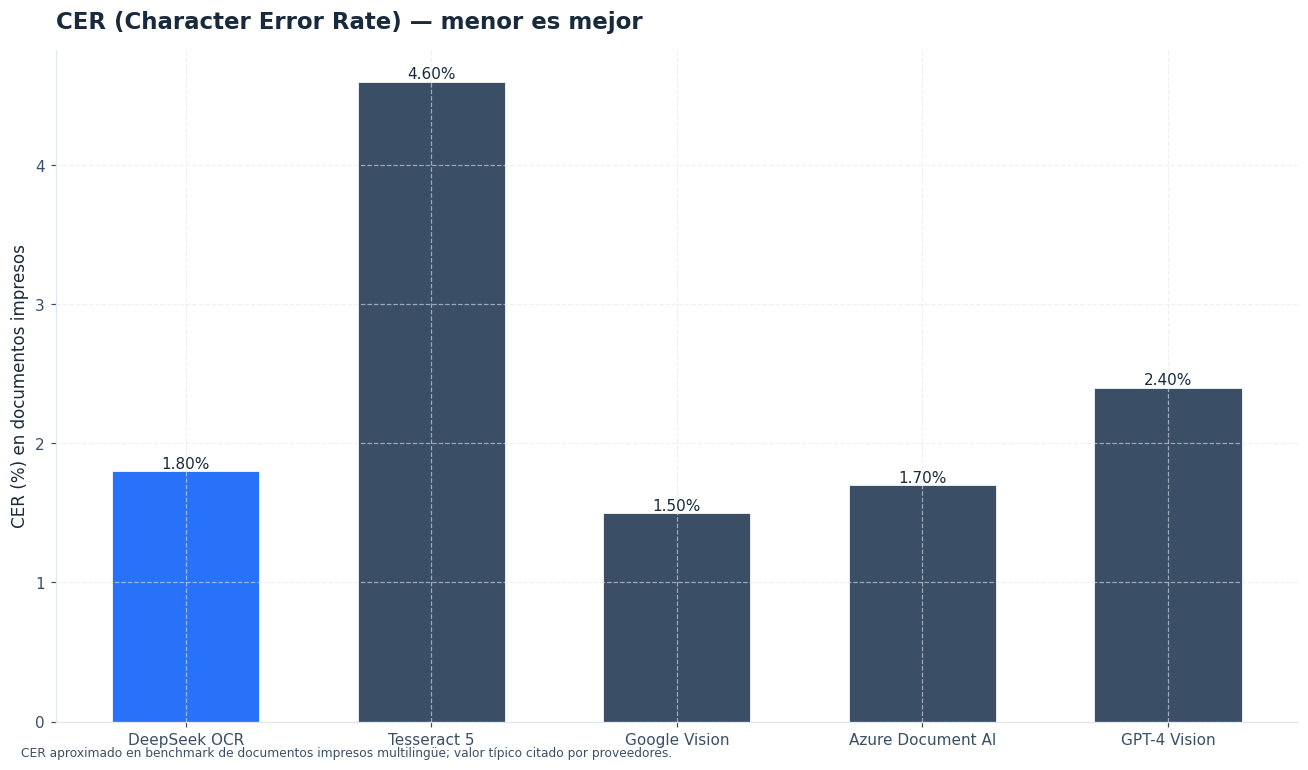
El informe técnico de DeepSeek OCR no presenta sus métricas principales como CER en todos los casos. Para OmniDocBench usa distancias de edición por categoría, donde los valores menores indican mejor rendimiento [1]. Por eso, no conviene convertir esas cifras a CER si la fuente no lo declara.
En el benchmark Fox, el informe mide precisión de reconstrucción bajo distintas ratios de compresión. Con documentos en inglés de 600 a 1.300 tokens, el modo Small con 100 tokens visuales mantiene entre 98,5% y 87,1% de precisión según el tramo de longitud; el modo Tiny con 64 tokens cae más rápido en documentos largos [1].
En OmniDocBench, DeepSeek OCR Base obtiene 0,137 de distancia de edición global en inglés y 0,240 en chino. El modo Gundam mejora a 0,127 en inglés y 0,181 en chino, con más tokens visuales por página [1]. Estas cifras no significan «lectura perfecta»; indican una mejora medible en un benchmark concreto.
El mismo informe muestra que los periódicos y documentos muy densos requieren modos de mayor resolución. En categorías como libros, diapositivas o informes, los modos con menos tokens pueden ser suficientes. Para páginas con muchas columnas, letra pequeña o mezcla de gráficos, conviene probar Gundam o una resolución superior.
| Benchmark / modo | Métrica publicada | Resultado citado | Lectura correcta |
|---|---|---|---|
| Fox, Small, 600-700 tokens | Precisión | 98,5% | Muy buen resultado en páginas cortas en inglés. |
| Fox, Small, 1.200-1.300 tokens | Precisión | 87,1% | La precisión baja al aumentar densidad y compresión. |
| OmniDocBench, Base, inglés | Distancia de edición | 0,137 | Menor es mejor; no equivale directamente a CER. |
| OmniDocBench, Gundam, chino | Distancia de edición | 0,181 | Mejora frente a Base en chino, con más coste visual. |
| Producción declarada | Páginas por día | 200.000+ con una A100-40G | Dato del informe técnico; requiere replicar entorno y carga. |
Cómo integrarlo con DeepSeek V4
A 7 de mayo de 2026, la API oficial de DeepSeek lista deepseek-v4-flash y deepseek-v4-pro como modelos disponibles en el endpoint de modelos [4]. La página oficial de precios también se centra en esos dos modelos V4, con contexto de 1M tokens y salida máxima de 384K [5].
Esto afecta al diseño de arquitectura. Si quieres usar DeepSeek OCR hoy, lo normal es desplegarlo por tu cuenta con Transformers, vLLM o una plataforma que lo sirva. Después, puedes enviar el texto extraído a la API compatible con OpenAI de DeepSeek para procesarlo con deepseek-v4-flash o deepseek-v4-pro.
Para grandes volúmenes, separa tres colas: renderizado de PDF, OCR y análisis con LLM. Así puedes reintentar páginas fallidas, medir calidad por documento y evitar que un error de lectura contamine toda la extracción. También facilita aplicar reglas distintas a facturas, recibos, contratos y manuscritos.
curl https://api.deepseek.com/v1/models \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-H "Content-Type: application/json"Ese comando sirve para comprobar qué modelos expone tu cuenta en la API oficial. Si solo aparecen deepseek-v4-flash y deepseek-v4-pro, usa DeepSeek OCR en un despliegue separado y reserva V4 para razonamiento, limpieza, clasificación y generación de salidas estructuradas. Puedes revisar costes actualizados en precios de DeepSeek.
Comparativa con Tesseract, Azure, Google Vision y GPT-4 Vision
Tesseract sigue siendo la referencia clásica de OCR abierto. Su repositorio oficial indica soporte UTF-8, más de 100 idiomas de serie, entrada en formatos como PNG, JPEG y TIFF, y salidas como texto, hOCR, PDF, TSV, ALTO y PAGE [6]. Es una gran opción si necesitas control local, coste cero por llamada y un pipeline determinista.
Azure AI Vision Read está más orientado a OCR gestionado en producción. La documentación de Microsoft indica extracción de texto impreso y manuscrito, idiomas globales, ubicación por palabras y líneas, soporte de idiomas mixtos y formatos JPEG, PNG, BMP, PDF y TIFF [7]. Encaja bien si tu infraestructura ya depende de Azure y necesitas soporte empresarial.
Google Cloud Vision admite OCR con TEXT_DETECTION y DOCUMENT_TEXT_DETECTION. Su documentación lista formatos como JPEG, PNG, GIF, BMP, WEBP, RAW, ICO, PDF y TIFF, y recomienda 1024×768 para OCR porque el texto requiere más resolución [8]. Es una alternativa gestionada sólida para equipos ya integrados en Google Cloud.
GPT-4 Vision y los modelos de visión de OpenAI sirven para análisis visual general y pueden leer texto en imágenes, pero no son un OCR documental puro. La documentación actual de OpenAI admite entradas PNG, JPEG, WEBP y GIF no animado, y advierte limitaciones con texto pequeño, rotación y alfabetos no latinos [9]. Para extracción masiva y verificable, conviene medirlo contra un OCR dedicado.
| Opción | Ventaja principal | Limitación típica | Cuándo elegirla |
|---|---|---|---|
| DeepSeek OCR | OCR documental con enfoque de compresión visual y salida flexible. | No aparece como modelo público en la API oficial general. | Despliegue propio, investigación, pipelines con DeepSeek V4. |
| Tesseract | Abierto, local, maduro y muy controlable. | Requiere preprocesado; peor en diseños complejos. | OCR clásico, lotes internos, documentos simples. |
| Azure AI Vision Read | Servicio gestionado con soporte empresarial y PDF nativos. | Dependencia de nube y facturación por servicio. | Producción corporativa en Azure. |
| Google Cloud Vision | OCR gestionado con muchos formatos soportados. | Coste y dependencia de Google Cloud. | Aplicaciones ya desplegadas en Google Cloud. |
| GPT-4 Vision / OpenAI Vision | Comprensión visual general y razonamiento sobre imágenes. | No es un motor OCR dedicado; puede fallar con texto pequeño o rotado. | Preguntas visuales, interpretación contextual, casos no masivos. |
Buenas prácticas para producción
La calidad de DeepSeek OCR depende tanto del modelo como de la imagen. Una página limpia, bien orientada y con contraste suficiente produce mejores resultados que un escaneo torcido. Antes de evaluar el modelo, crea un conjunto de prueba con documentos reales, no solo ejemplos limpios.
- Define una resolución objetivo por tipo de documento: recibos, facturas, contratos, informes y capturas.
- Guarda imagen original, versión preprocesada, prompt, salida del OCR y salida final del LLM.
- Mide error por campo crítico, no solo texto completo: importes, fechas, nombres, NIF, SKU o número de factura.
- Usa validaciones externas para datos sensibles: sumas, formatos de fecha, divisas y códigos fiscales.
- Marca las salidas con baja confianza para revisión humana.
- Evita pedir al OCR que «interprete» demasiado; extrae primero y razona después.
En flujos de documentos largos, no juntes todas las páginas en una única petición posterior al LLM. Procesa por página, detecta secciones y consolida al final. Si usas DeepSeek V4 Pro, aprovecha su mayor capacidad de salida para informes largos. Si el objetivo es clasificar o extraer campos simples, DeepSeek V4 Flash suele ser más eficiente.
También debes decidir dónde se ejecuta el OCR. Un despliegue local reduce exposición de datos, pero exige GPU, mantenimiento y observabilidad. Un servicio gestionado acelera la integración, aunque introduce dependencia externa. Para datos personales, sanitarios o financieros, revisa políticas de retención, ubicación de datos y registros de auditoría antes de enviar documentos.
Costes y elección de modelo
DeepSeek OCR no tiene una tarifa oficial en la tabla pública de la API de DeepSeek. Sus costes dependen del despliegue: GPU, almacenamiento, conversión de PDF, colas, reintentos y monitorización. Por eso, el coste real se calcula por página procesada, no solo por tokens.
Para la parte posterior de análisis con LLM, la tabla oficial de DeepSeek indica que V4 Flash cuesta $0,14 por 1M tokens de entrada y $0,28 por 1M tokens de salida. V4 Pro figura con precio promocional activo de $0,435 de entrada y $0,87 de salida hasta el 31 de mayo de 2026, con precios base tachados de $1,74 y $3,48 [5]. En tu documentación interna, separa precio promocional y precio base.
La selección práctica es sencilla. Usa DeepSeek OCR para leer. Usa DeepSeek V4 Flash para normalizar campos, clasificar documentos o crear resúmenes cortos. Usa DeepSeek V4 Pro cuando necesites razonamiento más profundo, consolidación de muchos documentos o salida larga. En todos los casos, revisa los precios actuales de la API antes de estimar un presupuesto.
Preguntas frecuentes
¿DeepSeek OCR está disponible en la API oficial de DeepSeek?
A 7 de mayo de 2026, la documentación oficial de modelos de la API lista deepseek-v4-flash y deepseek-v4-pro, no DeepSeek OCR [4]. Para usar DeepSeek OCR, lo habitual es desplegar el modelo desde Hugging Face, GitHub, Transformers o vLLM, y conectar después la salida con la API de V4.
¿DeepSeek OCR puede leer PDF directamente?
El repositorio oficial incluye scripts orientados a PDF, pero el enfoque operativo es tratar cada página como imagen [3]. Si el PDF ya contiene texto seleccionable, primero intenta extraerlo con herramientas de PDF. Reserva OCR para escaneos, fotografías o documentos donde el texto no esté disponible.
¿DeepSeek OCR reconoce manuscritos?
Puede ayudar en manuscritos simples, pero no debe asumirse precisión alta en letra cursiva, notas degradadas o escritura muy personal. Para formularios manuscritos críticos, valida con una muestra real y aplica revisión humana en campos sensibles.
¿Qué idiomas soporta DeepSeek OCR?
El informe técnico indica entrenamiento con documentos PDF en cerca de 100 idiomas y visualizaciones en árabe y cingalés [1]. También indica que el OCR de escenas naturales se centró principalmente en chino e inglés [1]. Si tu caso depende de un idioma concreto, crea una evaluación propia.
¿DeepSeek OCR sustituye a Tesseract?
No necesariamente. Tesseract sigue siendo útil para OCR local, determinista y barato en documentos simples. DeepSeek OCR es más interesante cuando hay disposición compleja, Markdown, tablas, fórmulas o integración posterior con modelos de lenguaje.
¿Debo usar DeepSeek OCR o GPT-4 Vision?
Para OCR masivo y auditable, empieza con un motor especializado como DeepSeek OCR, Tesseract, Azure o Google Vision. GPT-4 Vision encaja mejor cuando necesitas interpretar la imagen, responder preguntas visuales o combinar lectura con razonamiento contextual.
Conclusión
DeepSeek OCR es una pieza útil para convertir documentos visuales en texto procesable. Su papel no es chatear ni razonar como DeepSeek V4 Pro, sino leer imágenes, escaneos, capturas y páginas renderizadas de PDF. Para un sistema fiable, separa OCR, validación y análisis con LLM. Empieza con un conjunto de documentos reales, mide errores por campo y decide si necesitas despliegue propio o un OCR gestionado. Después, conecta la salida con DeepSeek V4 para resumir, clasificar o estructurar los resultados.
Fuentes
’]