
La migración DeepSeek V4 sustituye los alias heredados deepseek-chat y deepseek-reasoner por los identificadores explícitos deepseek-v4-flash y deepseek-v4-pro. El cambio conviene planificarlo antes del 24 de julio de 2026, fecha en la que esos alias heredados dejan de estar disponibles en la API [1].
Resumen rápido
deepseek-chatydeepseek-reasonerquedan obsoletos el 24 de julio de 2026; cambia los nombres de modelo cuanto antes [1].- La URL base compatible con OpenAI se mantiene:
https://api.deepseek.com/v1/. En muchos SDK basta con cambiarmodel. - Usa
deepseek-v4-flashpara chat general, extracción, clasificación y flujos sensibles a coste. - Usa
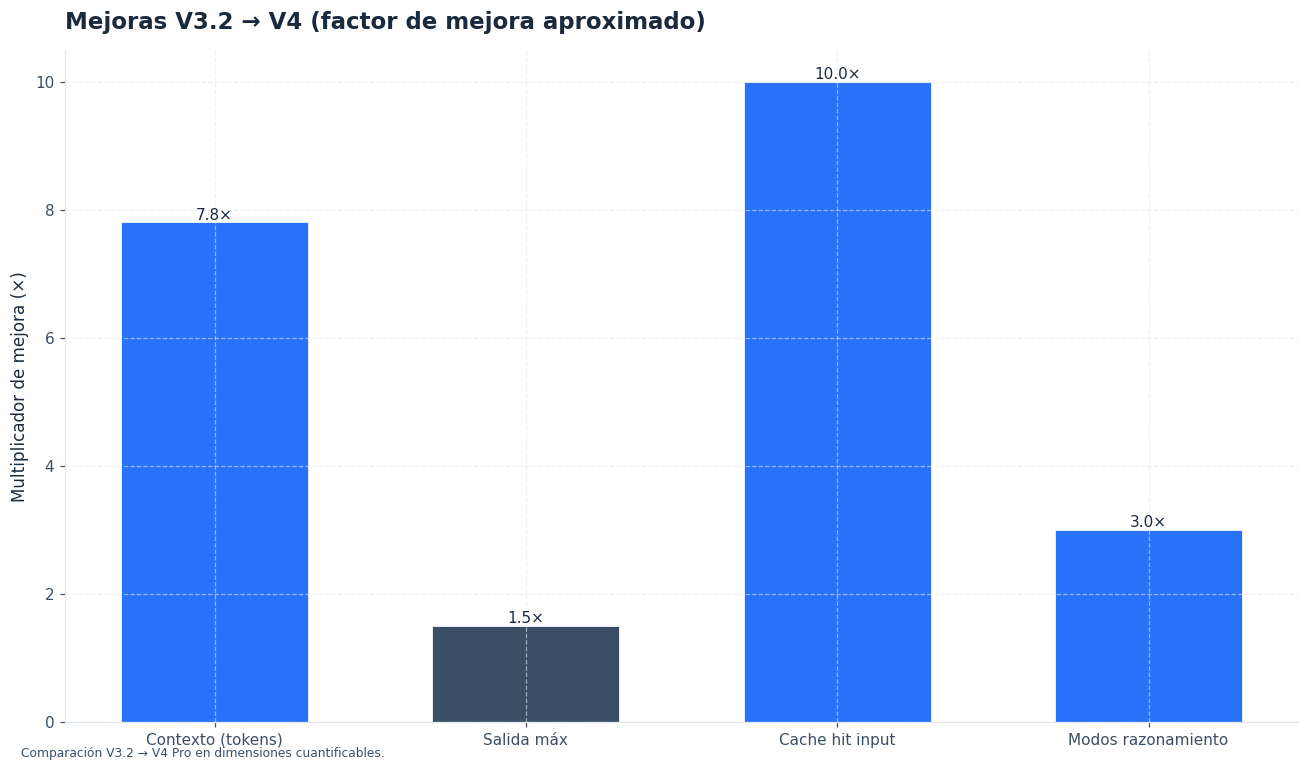
deepseek-v4-propara razonamiento complejo, agentes, generación de código exigente y contextos largos. - DeepSeek V4 añade una ventana de contexto de 1 M de tokens y salida máxima de hasta 384 000 tokens en V4 Pro [2].
- La migración DeepSeek V4 debe cubrir pruebas de regresión, JSON estructurado, llamadas a herramientas, streaming, caché y límites de coste.
Antes de empezar
Antes de tocar código, crea una rama de migración y fija el alcance. El objetivo no es solo reemplazar cadenas: también hay que validar razonamiento, límites de salida, formato JSON y consumo de tokens.
Ten preparados estos prerrequisitos:
- Una clave activa de DeepSeek en la variable
DEEPSEEK_API_KEY. - Acceso al repositorio donde se configuran los modelos heredados.
- Un conjunto de prompts reales, con casos de chat, JSON, herramientas y errores.
- Un entorno de pruebas separado de producción.
- Registro de
usage, latencia, errores HTTP y coste por petición. - Un plan de reversión hasta retirar por completo los alias heredados.
Si necesitas revisar conceptos generales antes de migrar, consulta la documentación de API de DeepSeek, la página de DeepSeek V4 y la guía de precios de DeepSeek.
export DEEPSEEK_API_KEY="sk-..."
export DEEPSEEK_BASE_URL="https://api.deepseek.com/v1"
git checkout -b migracion-deepseek-v4También conviene congelar versiones de SDK durante la migración. Así evitas mezclar cambios del proveedor con cambios de dependencias.
python -m pip freeze > requirements.lock.before-v4.txt
npm ls --depth=0 > npm.lock.before-v4.txt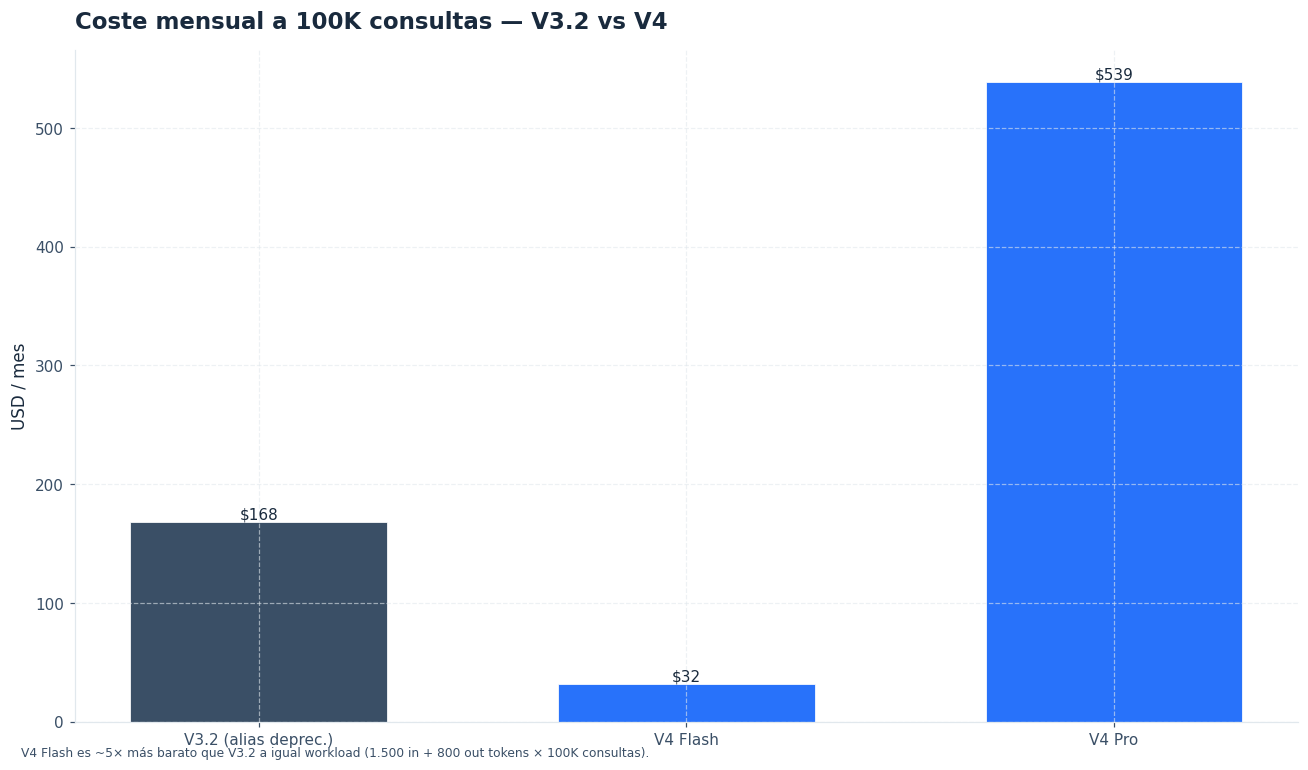
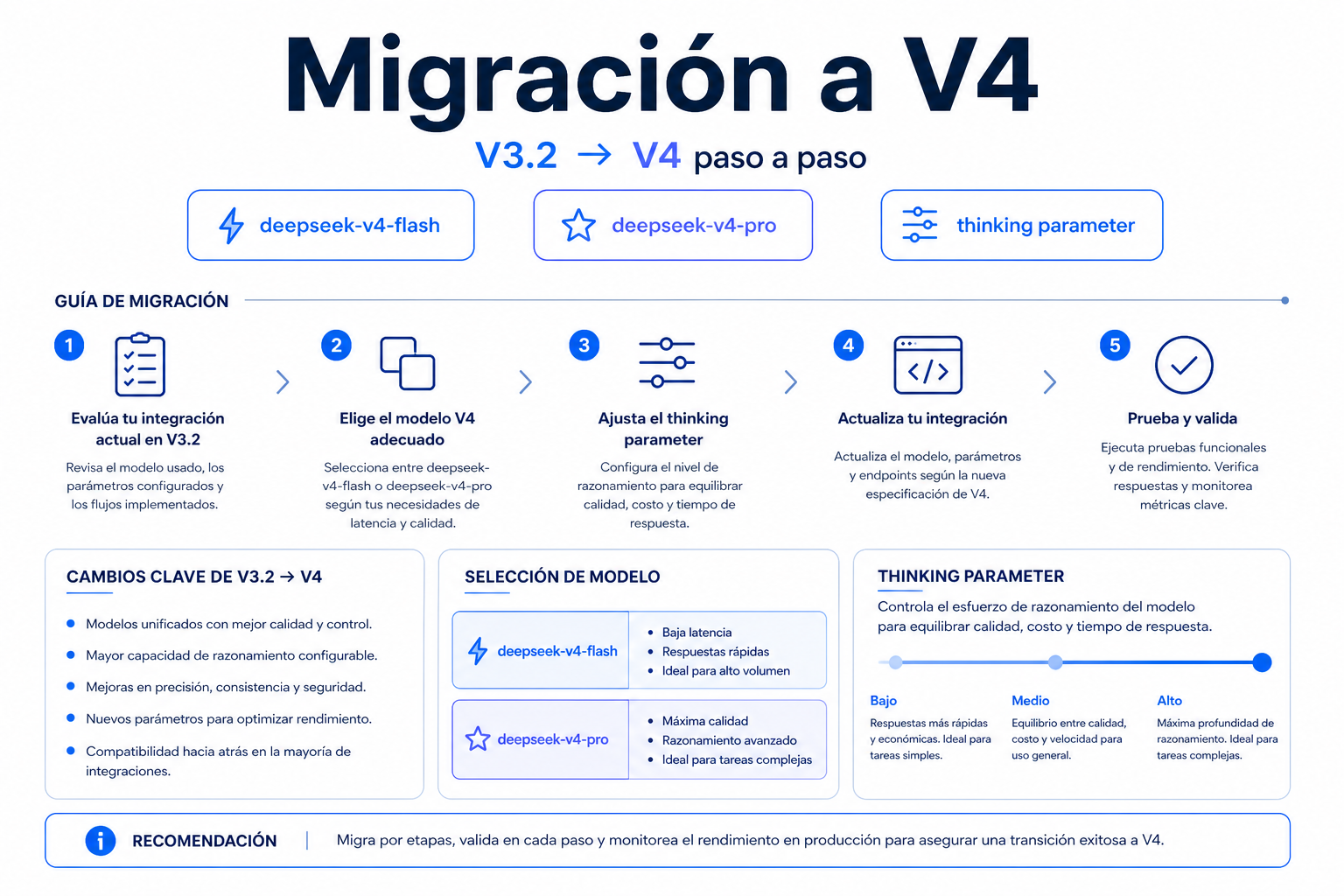
Qué cambia al pasar de V3.2 a V4
En V3.2, los alias deepseek-chat y deepseek-reasoner apuntaban a modos distintos del modelo disponible. En V4, DeepSeek expone nombres explícitos para Flash y Pro, y conserva la interfaz compatible con OpenAI [1].
| Área | V3.2 heredado | V4 recomendado | Acción |
|---|---|---|---|
| Chat general | deepseek-chat | deepseek-v4-flash | Cambiar model y ejecutar pruebas de regresión. |
| Razonamiento | deepseek-reasoner | deepseek-v4-pro | Activar thinking y fijar reasoning_effort. |
| URL base OpenAI | https://api.deepseek.com/v1/ | https://api.deepseek.com/v1/ | Mantenerla salvo que tu SDK quite la barra final. |
| Contexto | Menor que V4 | 1 M de tokens | Revisar truncado, RAG y límites propios. |
| Salida máxima | Menor que V4 | Hasta 384 000 tokens en V4 Pro | Definir max_tokens para controlar coste. |
| Licencia de pesos | Pesos abiertos en versiones previas | MIT para V4 Pro y V4 Flash | Validar licencia si usas despliegue propio [5]. |
La elección práctica es sencilla. DeepSeek V4 Flash encaja mejor en volumen alto y baja latencia. DeepSeek V4 Pro encaja mejor cuando el fallo de razonamiento cuesta más que la inferencia.
| Modelo | Entrada por 1 M de tokens | Salida por 1 M de tokens | Acierto de caché de entrada | Uso típico |
|---|---|---|---|---|
deepseek-v4-flash | $0,14 | $0,28 | $0,028 | Chat, clasificación, extracción, resumen y asistentes de alto volumen. |
deepseek-v4-pro | $1,74 | $3,48 | $0,87 | Agentes, razonamiento largo, código complejo y tareas con alta exigencia. |
Las tarifas pueden cambiar; verifica los importes vigentes en la página de planes y precios antes de presupuestar una integración.
Los precios pueden cambiar y DeepSeek aplica descuentos temporales en algunos periodos [2]. Para presupuestos cerrados, calcula con precio de lista y revisa la página de precios antes del despliegue.
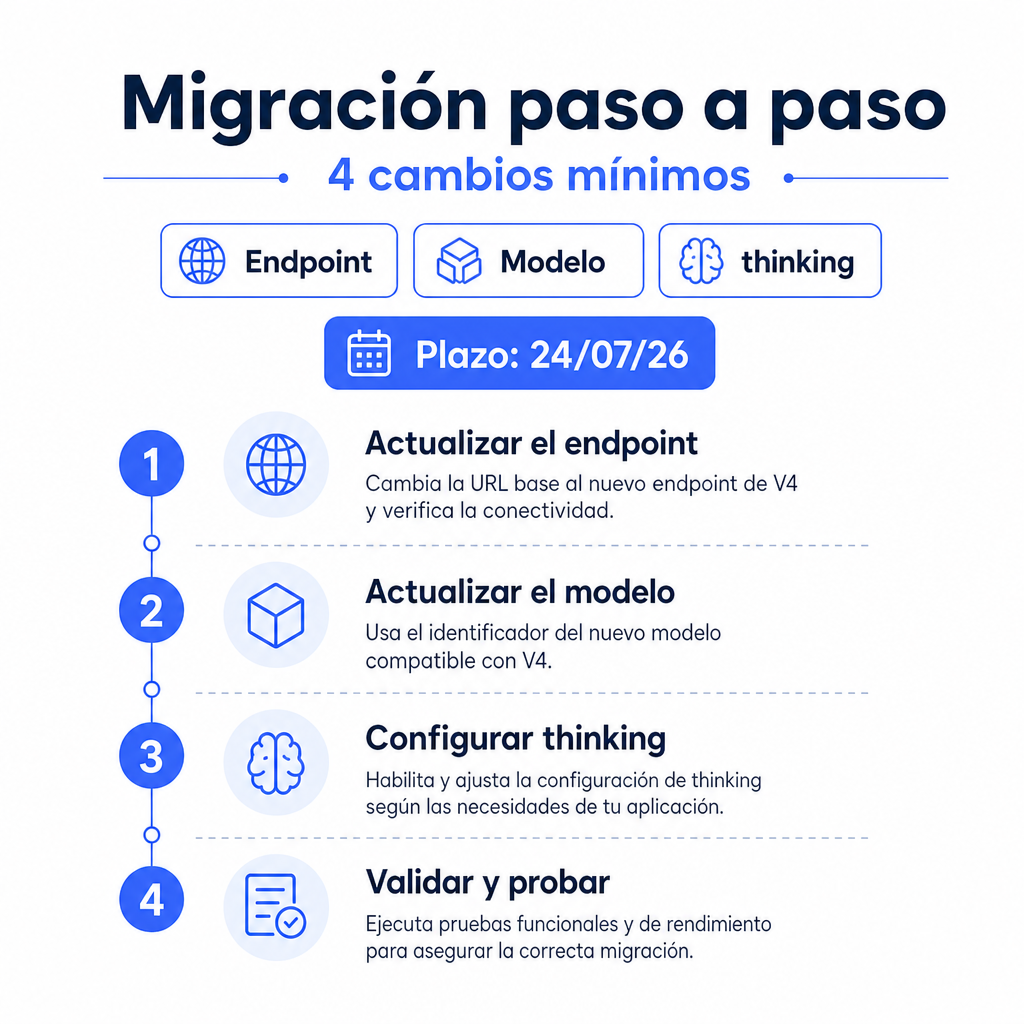
Migración paso a paso
Esta sección concentra la migración DeepSeek V4 en cambios pequeños y verificables. Aplica cada paso en una rama, ejecuta pruebas y deja trazas comparables.
Paso 1: inventaria llamadas a modelos heredados
Busca los alias en código, variables, plantillas, paneles de configuración y pruebas. No limites la búsqueda al backend: muchos clientes guardan el modelo en ficheros .env, YAML o JSON.
rg -n "deepseek-chat|deepseek-reasoner|api.deepseek.com" \
./src ./config ./tests .env* package.json pyproject.tomlRegistra cada hallazgo con propietario, entorno y criticidad. Una tabla simple evita que el despliegue deje un servicio menor apuntando a un alias que caduca.
cat > deepseek-v4-inventory.csv <<'CSV'
ruta,alias_actual,modelo_v4,riesgo,propietario
src/chat.ts,deepseek-chat,deepseek-v4-flash,medio,backend
src/agent.py,deepseek-reasoner,deepseek-v4-pro,alto,agents
CSVPaso 2: cambia el identificador de modelo
El cambio mínimo es sustituir model. Mantén la URL base compatible con OpenAI si ya usabas /v1. El siguiente ejemplo muestra el antes y el después en cURL.
Antes: V3.2 con deepseek-chat
curl https://api.deepseek.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "Responde en español claro."},
{"role": "user", "content": "Resume este ticket de soporte."}
],
"stream": false
}'Después: V4 con deepseek-v4-flash
curl https://api.deepseek.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{"role": "system", "content": "Responde en español claro."},
{"role": "user", "content": "Resume este ticket de soporte."}
],
"thinking": {"type": "disabled"},
"stream": false
}'Para migraciones mecánicas, usa sustituciones controladas. Revisa el diff antes de confirmar.
python - <<'PY'
from pathlib import Path
exts = {".py", ".ts", ".tsx", ".js", ".json", ".yaml", ".yml", ".env"}
for path in Path(".").rglob("*"):
if path.is_file() and path.suffix in exts:
text = path.read_text(errors="ignore")
new = text.replace("deepseek-chat", "deepseek-v4-flash")
new = new.replace("deepseek-reasoner", "deepseek-v4-pro")
if new != text:
path.write_text(new)
print(path)
PY
git diff -- src config testsPaso 3: migra el razonamiento de deepseek-reasoner
Si usabas deepseek-reasoner, no migres a Flash sin medir calidad. Para tareas de razonamiento, usa V4 Pro con thinking activado y reasoning_effort en high o max. El modo thinking-max corresponde a Pro.
Antes: V3.2 con razonamiento heredado
curl https://api.deepseek.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-reasoner",
"messages": [
{"role": "user", "content": "Depura este algoritmo y explica el fallo."}
]
}'Después: V4 Pro con razonamiento alto
curl https://api.deepseek.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-v4-pro",
"messages": [
{"role": "user", "content": "Depura este algoritmo y explica el fallo."}
],
"thinking": {"type": "enabled"},
"reasoning_effort": "high"
}'En el SDK de OpenAI para Python, pasa thinking dentro de extra_body. DeepSeek documenta este patrón para conservar compatibilidad con clientes existentes [3].
from openai import OpenAI
import os
client = OpenAI(
api_key=os.environ["DEEPSEEK_API_KEY"],
base_url="https://api.deepseek.com/v1",
)
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{"role": "user", "content": "Encuentra el bug y propone un parche."}
],
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}},
)
print(response.choices[0].message.content)Paso 4: valida JSON, herramientas y streaming
La migración DeepSeek V4 debe verificar los contratos de salida. Si tu aplicación parsea JSON, usa response_format, incluye la palabra “json” en el prompt y limita max_tokens para evitar respuestas cortadas [4].
curl https://api.deepseek.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{"role": "system", "content": "Devuelve solo json válido con claves: title, priority."},
{"role": "user", "content": "json: Error 500 al guardar factura. Cliente bloqueado."}
],
"response_format": {"type": "json_object"},
"max_tokens": 200,
"thinking": {"type": "disabled"}
}' | jq -r '.choices[0].message.content' | jq .Si usas llamadas a herramientas, prueba los dos modos: sin razonamiento y con razonamiento. En modo thinking, conserva el mensaje del asistente con reasoning_content cuando haya llamadas a herramientas, porque omitirlo puede producir errores 400 [3].
pytest tests/deepseek/test_json_contract.py -q
pytest tests/deepseek/test_tool_calls.py -q
pytest tests/deepseek/test_streaming.py -qPaso 5: configura observabilidad y despliegue gradual
No cambies todo el tráfico en un solo despliegue. Empieza con un porcentaje bajo, compara respuestas y sube el tráfico cuando latencia, errores y coste sean estables.
export DEEPSEEK_V4_TRAFFIC_PERCENT=10
export DEEPSEEK_DEFAULT_MODEL="deepseek-v4-flash"
export DEEPSEEK_REASONING_MODEL="deepseek-v4-pro"Un enrutador mínimo puede elegir modelo por tipo de tarea. Ajusta la lógica según tus métricas, no por intuición.
def select_deepseek_model(task: str, requires_reasoning: bool) -> dict:
if requires_reasoning or task in {"agent", "code_review", "math"}:
return {
"model": "deepseek-v4-pro",
"thinking": {"type": "enabled"},
"reasoning_effort": "high",
}
return {
"model": "deepseek-v4-flash",
"thinking": {"type": "disabled"},
}Si tu producto tiene interfaz conversacional, prueba también el flujo de chat con DeepSeek para verificar expectativas de usuario final. La calidad percibida puede variar aunque las pruebas unitarias pasen.
Pruebas, despliegue gradual y control de costes
Después del cambio de código, mide cuatro señales: exactitud, estabilidad de formato, latencia y coste. Guarda métricas separadas por modelo, tipo de tarea y modo de razonamiento.
Una prueba de regresión útil compara la salida heredada con V4 usando prompts reales. No busques igualdad literal; busca equivalencia funcional, validez JSON, ausencia de campos perdidos y cumplimiento de instrucciones.
python scripts/eval_deepseek_migration.py \
--before-model deepseek-chat \
--after-model deepseek-v4-flash \
--dataset datasets/prompts_chat.jsonl \
--out reports/v4_flash_regression.json
python scripts/eval_deepseek_migration.py \
--before-model deepseek-reasoner \
--after-model deepseek-v4-pro \
--dataset datasets/prompts_reasoning.jsonl \
--out reports/v4_pro_regression.jsonPara costes, registra tokens de entrada, tokens de salida y tokens de caché. DeepSeek expone campos de uso para distinguir prompt_cache_hit_tokens y prompt_cache_miss_tokens [6]. Esa separación permite detectar si tus prompts largos reutilizan prefijos.
python - <<'PY'
def estimate_cost(model, input_tokens, output_tokens, cache_hit_tokens=0):
prices = {
"deepseek-v4-flash": {"in": 0.14, "out": 0.28, "hit": 0.028},
"deepseek-v4-pro": {"in": 1.74, "out": 3.48, "hit": 0.87},
}
p = prices[model]
miss_tokens = max(input_tokens - cache_hit_tokens, 0)
return (miss_tokens / 1_000_000) * p["in"] + \
(cache_hit_tokens / 1_000_000) * p["hit"] + \
(output_tokens / 1_000_000) * p["out"]
print(estimate_cost("deepseek-v4-flash", 120_000, 8_000, 80_000))
print(estimate_cost("deepseek-v4-pro", 120_000, 8_000, 80_000))
PYDefine umbrales de reversión antes de producción. Por ejemplo: tasa de error superior al 1 %, latencia p95 un 30 % mayor o coste diario un 20 % por encima del presupuesto. En la página principal de deepseek-espanol.chat puedes enlazar esta guía desde el área de recursos técnicos si tu equipo la usa como referencia interna.
Solución de problemas frecuentes
Error 400 al usar herramientas con thinking
El patrón habitual es perder reasoning_content al reconstruir la conversación. Cuando el modelo realiza una llamada a herramienta en modo thinking, conserva el mensaje completo del asistente y vuelve a enviarlo en los turnos siguientes [3].
# Correcto: conserva content, reasoning_content y tool_calls
messages.append(response.choices[0].message)Error 401 tras cambiar a V4
El modelo no suele ser la causa. DeepSeek asocia el 401 a fallos de autenticación [7]. Revisa que la clave llegue al proceso y que no estés mezclando variables de otro proveedor.
test -n "$DEEPSEEK_API_KEY" || echo "Falta DEEPSEEK_API_KEY"
curl https://api.deepseek.com/v1/chat/completions \
-H "Authorization: Bearer ${DEEPSEEK_API_KEY}" \
-H "Content-Type: application/json" \
-d '{"model":"deepseek-v4-flash","messages":[{"role":"user","content":"ping"}]}'JSON vacío, inválido o truncado
Añade response_format, pide JSON de forma explícita y sube max_tokens si el objeto puede crecer. DeepSeek recomienda incluir la palabra “json” en el prompt y proporcionar un ejemplo de estructura [4].
{
"response_format": {"type": "json_object"},
"max_tokens": 800,
"messages": [
{"role": "system", "content": "Devuelve json válido. Ejemplo: {\"ok\": true, \"items\": []}"}
]
}La factura sube tras migrar
Revisa si estás enviando demasiado contexto o si V4 Pro se usa en tareas que Flash resolvería. Limita max_tokens, activa rutas por tipo de tarea y mide caché con prompt_cache_hit_tokens.
jq '.usage | {
prompt_tokens,
completion_tokens,
prompt_cache_hit_tokens,
prompt_cache_miss_tokens
}' reports/sample_response.jsonEl SDK no acepta thinking
Algunos clientes compatibles con OpenAI validan parámetros estrictamente. En Python, usa extra_body. En JavaScript, pasa el campo en el cuerpo si tu versión del SDK lo permite.
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=messages,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}},
)Preguntas frecuentes
¿Tengo que cambiar la URL base en la migración DeepSeek V4?
No, si ya usas la interfaz compatible con OpenAI. Puedes mantener https://api.deepseek.com/v1/ y cambiar el campo model. Algunos ejemplos oficiales usan https://api.deepseek.com sin /v1, pero la ruta /v1/chat/completions sigue siendo el patrón compatible con OpenAI [1].
¿Qué modelo sustituye a deepseek-chat?
Para la mayoría de usos, deepseek-v4-flash. Es la opción natural para chat general, clasificación, extracción, resumen y automatizaciones de volumen alto. Si el caso exige razonamiento fuerte, evalúa deepseek-v4-pro.
¿Qué modelo sustituye a deepseek-reasoner?
deepseek-v4-pro con thinking activado. Para tareas muy complejas, usa reasoning_effort: "max" si tu presupuesto lo permite. Reserva ese modo para agentes, código difícil o razonamiento largo.
¿Puedo migrar primero solo una parte del tráfico?
Sí. Es lo más prudente. Usa una bandera de configuración, envía un 5-10 % del tráfico a V4, compara métricas y aumenta el porcentaje por etapas. Mantén reversión rápida hasta estabilizar producción.
¿Los pesos de DeepSeek V4 son abiertos?
Sí. Los repositorios de DeepSeek V4 Pro y V4 Flash en Hugging Face muestran licencia MIT [5]. Si vas a desplegar pesos por tu cuenta, revisa también requisitos de hardware, cuantización y cumplimiento interno.
¿Qué pasa si no migro antes del 24 de julio de 2026?
Las llamadas que dependan de deepseek-chat o deepseek-reasoner pueden fallar cuando los alias se retiren. Migra antes, ejecuta pruebas y elimina referencias heredadas de documentación, paneles y variables de entorno.
Conclusión
La migración de DeepSeek V3.2 a V4 es manejable si se trata como cambio de contrato, no como simple renombrado. Empieza por inventariar alias, migra deepseek-chat a V4 Flash y deepseek-reasoner a V4 Pro, valida formatos y despliega por porcentaje. Antes del 24 de julio de 2026, elimina toda dependencia heredada y actualiza manuales de operaciones, pruebas y documentación interna. Si tu integración combina chat, agentes y JSON, prioriza los flujos críticos y mide coste por tarea desde el primer despliegue.