
DeepSeek V4 Flash es la variante rápida y económica de DeepSeek V4, lanzada el 24 de abril de 2026 para cargas de alto volumen. Importa porque combina 1M tokens de contexto, precios muy bajos y una API compatible con OpenAI, lo que facilita migrar asistentes, chatbots y automatizaciones sin rediseñar toda la pila.

Resumen rápido
- DeepSeek V4 Flash está pensado para chat de alto volumen, asistentes internos, flujos de atención y automatización a gran escala.
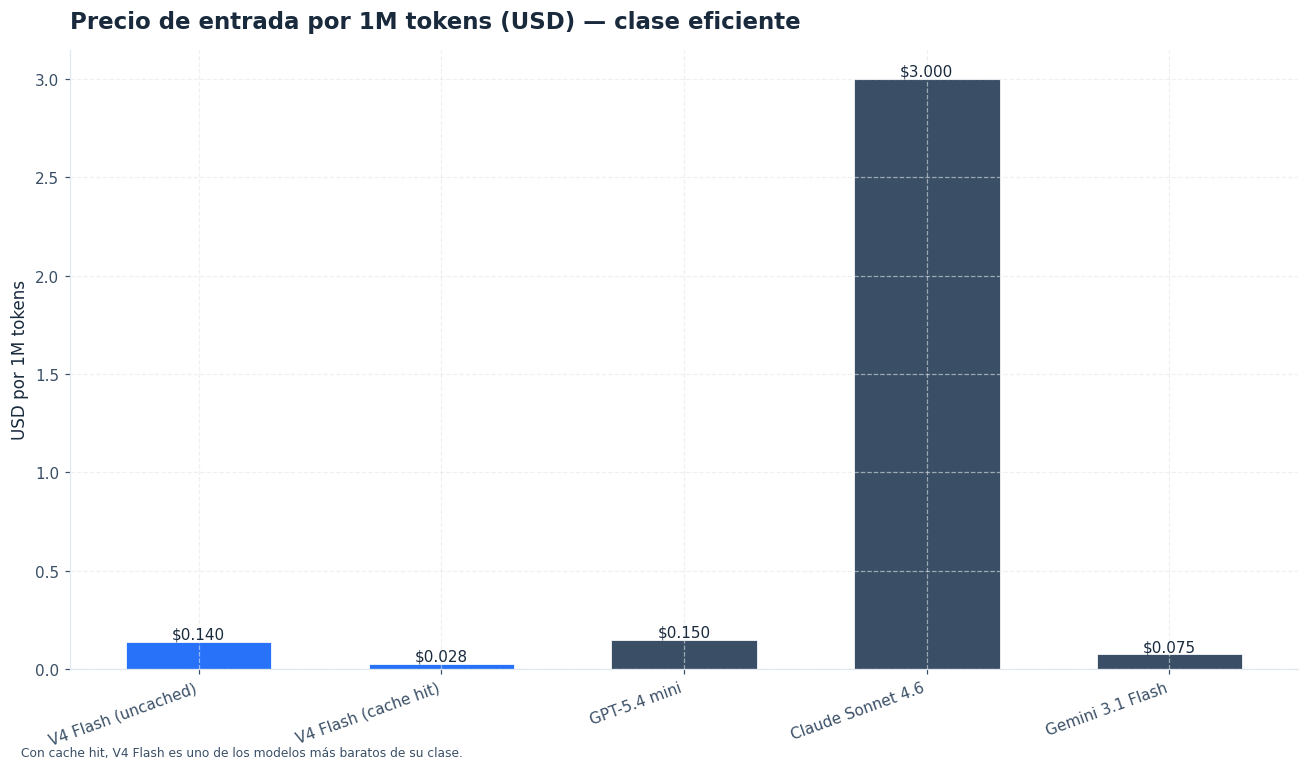
- Cuesta $0,14 por 1M tokens de entrada y $0,28 por 1M tokens de salida; el acierto de caché de entrada baja a $0,028 por 1M tokens.
- Admite 1M tokens de contexto, una ventaja clara para bases de conocimiento, historiales largos y procesamiento documental.
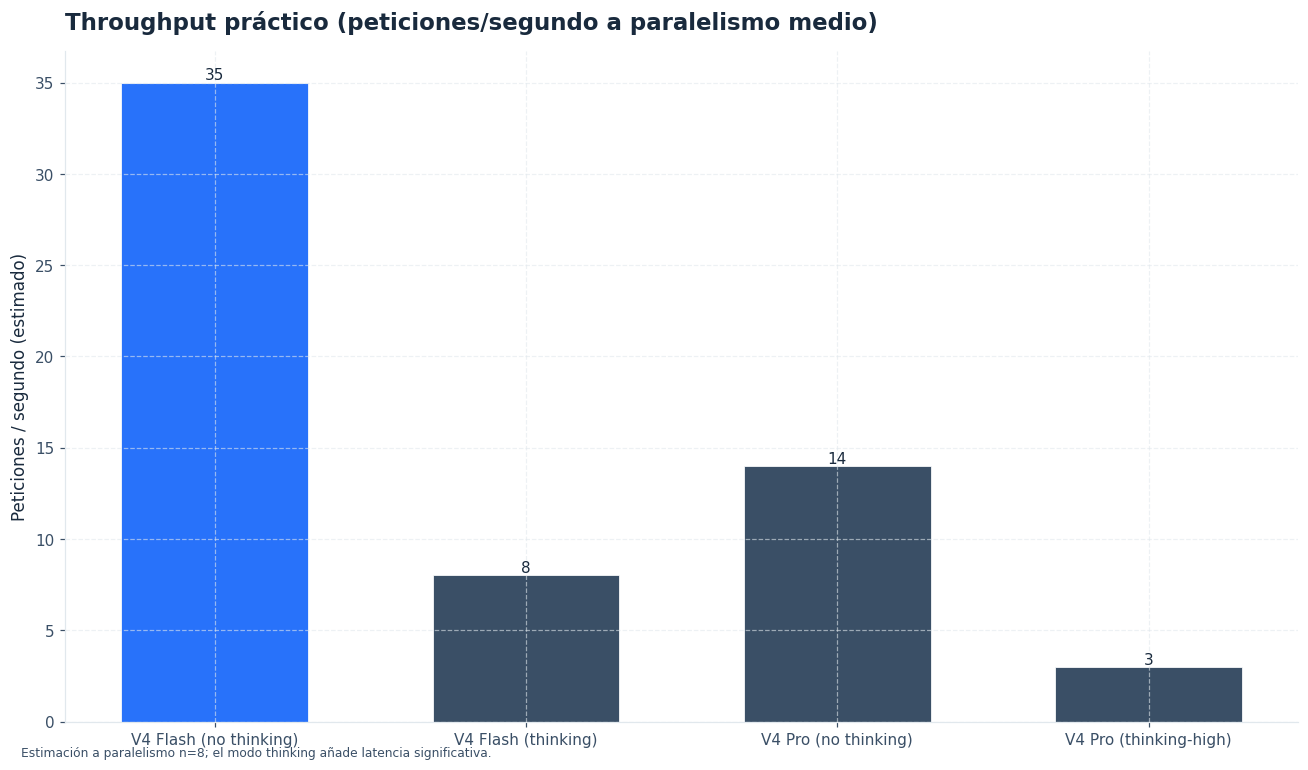
- Incluye modos de razonamiento non-thinking y thinking-high; thinking-max queda reservado para DeepSeek V4 Pro.
- Los pesos son abiertos con licencia MIT, lo que facilita auditorías, despliegues propios y experimentación fuera de la API gestionada.
- Compite de forma directa con modelos rápidos como GPT-5.4 mini y Claude Sonnet 4.6, aunque DeepSeek V4 Flash se centra en coste y escala.
¿Qué es DeepSeek V4 Flash?
DeepSeek V4 Flash es el modelo ligero de la familia DeepSeek V4. La familia se lanzó el 24 de abril de 2026 con dos variantes principales: DeepSeek V4 Pro, orientado a razonamiento profundo, y DeepSeek V4 Flash, optimizado para velocidad, coste y rendimiento sostenido en producción [1].
Su papel no es sustituir siempre a un modelo de máxima capacidad. Su valor aparece cuando necesitas muchas respuestas fiables, con baja latencia y gasto predecible. Por eso encaja en asistentes conversacionales, clasificación de mensajes, extracción de datos, respuestas sobre documentación y flujos automatizados que consumen millones de tokens al día.
DeepSeek V4 Flash conserva una ventana de contexto de 1M tokens, algo poco habitual en modelos económicos. Esa ventana permite trabajar con documentos extensos, historiales de conversación, catálogos, registros técnicos o bases de conocimiento completas sin fragmentar tanto la entrada.
El modelo usa la API compatible con OpenAI en https://api.deepseek.com/v1/. Si tu aplicación ya utiliza clientes, SDK o pasarelas compatibles con OpenAI, la migración suele limitarse al endpoint, la clave API, el identificador del modelo y los parámetros propios de razonamiento. Puedes probarlo desde DeepSeek Chat o integrarlo directamente desde la documentación de la API.
Capacidades y casos de uso
DeepSeek V4 Flash brilla cuando el coste por token condiciona el diseño del producto. En lugar de reservarlo para tareas puntuales, puedes usarlo como modelo principal en flujos donde cada interacción genera poco margen económico.
Chat de alto volumen
Un producto SaaS con miles de conversaciones diarias puede utilizar DeepSeek V4 Flash para respuestas de soporte, navegación por la base de ayuda y triaje inicial. El modo non-thinking encaja en respuestas simples. thinking-high sirve para incidencias con más pasos, como diagnosticar errores de configuración.
Asistentes internos
En equipos de operaciones, ventas o recursos humanos, el modelo puede responder sobre políticas internas, contratos, procedimientos y documentación. La ventana de 1M tokens permite cargar más contexto antes de recurrir a técnicas de recuperación. Aun así, para producción conviene combinarlo con búsqueda semántica y control de permisos.
Automatización a gran escala
DeepSeek V4 Flash encaja en tareas repetitivas: clasificar tickets, resumir llamadas, normalizar datos, transformar textos comerciales o generar respuestas preliminares. El precio de salida de $0,28 por 1M tokens ayuda cuando el sistema produce mucho texto.
Las tarifas pueden cambiar; verifica los importes vigentes en la página de planes y precios antes de presupuestar una integración.
Procesamiento documental
El contexto largo permite analizar expedientes, manuales, licitaciones o historiales de cliente. Para documentos críticos, conviene pedir respuestas con citas internas, rangos de página o fragmentos de soporte. Así reduces el riesgo de respuestas plausibles pero no verificadas.
Enrutamiento de modelos
Una arquitectura práctica usa DeepSeek V4 Flash como primera capa y escala a DeepSeek V4 Pro solo cuando detecta ambigüedad, bajo nivel de confianza o necesidad de thinking-max. Esta estrategia mejora el coste medio sin renunciar a una ruta de mayor razonamiento.
Especificaciones técnicas
La tabla resume los datos clave de DeepSeek V4 Flash para evaluar coste, límites y modo de uso. Los precios se expresan por 1M tokens.
| Campo | DeepSeek V4 Flash |
|---|---|
| Parámetros | 284B totales, 13B activos [1] |
| Contexto | 1M tokens |
| Modos de razonamiento | non-thinking, thinking-high; thinking-max solo en DeepSeek V4 Pro |
| Precio de entrada | $0,14 por 1M tokens |
| Precio de salida | $0,28 por 1M tokens |
| Precio de acierto de caché de entrada | $0,028 por 1M tokens |
Si tu caso depende mucho del prompt del sistema, instrucciones largas o documentación fija, el acierto de caché de entrada puede cambiar el coste real. Reutilizar contexto estable ayuda a pagar menos por las partes repetidas del prompt. Consulta los detalles actualizados en precios de DeepSeek.
Cómo usar la API
La API de DeepSeek V4 es compatible con el formato de OpenAI. El endpoint base es https://api.deepseek.com/v1/. Usa deepseek-v4-flash para la variante rápida y deepseek-v4-pro cuando necesites razonamiento más profundo.
curl https://api.deepseek.com/v1/chat/completions \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{
"role": "system",
"content": "Responde de forma breve y verifica los datos antes de concluir."
},
{
"role": "user",
"content": "Resume este ticket y propón la siguiente acción."
}
],
"thinking": "thinking-high",
"temperature": 0.2
}'
# Para tareas más complejas, cambia el modelo:
# "model": "deepseek-v4-pro"
# En Pro también puedes usar:
# "thinking": "thinking-max"Ejemplo opcional con Python usando un cliente compatible con OpenAI:
from openai import OpenAI
client = OpenAI(
api_key="DEEPSEEK_API_KEY",
base_url="https://api.deepseek.com/v1/"
)
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[
{"role": "system", "content": "Responde con una lista breve."},
{"role": "user", "content": "Extrae las acciones pendientes del texto."}
],
extra_body={"thinking": "non-thinking"},
temperature=0
)
print(response.choices[0].message.content)Si vienes de una integración anterior, revisa /docs/api/ antes de producción. Los alias heredados deepseek-chat y deepseek-reasoner quedan obsoletos el 24 de julio de 2026.
Comparativa rápida
DeepSeek V4 Flash compite por coste y volumen frente a modelos rápidos de otras plataformas. GPT-5.4 mini ofrece 400K tokens de contexto, 128K tokens máximos de salida y precios de $0,75 de entrada, $0,075 de entrada en caché y $4,50 de salida por 1M tokens [2]. Claude Sonnet 4.6 tiene 1M tokens de contexto en la plataforma Claude y mantiene el precio de $3 de entrada y $15 de salida por 1M tokens [3][4].
| Modelo | Mejor para | Contexto | Precio de entrada / salida | Notas |
|---|---|---|---|---|
| DeepSeek V4 Flash | Chat de alto volumen, automatización, asistentes económicos | 1M tokens | $0,14 / $0,28 por 1M tokens | Pesos abiertos MIT; API compatible con OpenAI |
| GPT-5.4 mini | Código, uso de ordenador y subagentes dentro del ecosistema OpenAI | 400K tokens | $0,75 / $4,50 por 1M tokens [2] | Entrada de texto e imagen; salida de texto |
| Claude Sonnet 4.6 | Código, agentes, uso de ordenador y tareas de conocimiento | 1M tokens | $3 / $15 por 1M tokens [3][4] | Modelo equilibrado de Anthropic con mejoras en razonamiento y contexto largo |
La elección depende del cuello de botella. Si el gasto por token pesa más que la máxima capacidad, DeepSeek V4 Flash es una opción clara. Si necesitas herramientas nativas del ecosistema OpenAI o Anthropic, los modelos competidores pueden encajar mejor pese al coste superior.
Limitaciones y consideraciones
DeepSeek V4 Flash no es la mejor opción para todos los trabajos. Al estar optimizado para eficiencia, puede quedar por detrás de modelos más caros en razonamiento profundo, planificación larga, matemáticas difíciles o tareas donde una sola respuesta incorrecta tenga impacto alto. Para esos casos, usa DeepSeek V4 Pro o un sistema de enrutamiento con evaluación automática.
También es un modelo centrado en texto. Si tu producto necesita comprensión nativa de audio, vídeo o generación de imagen, tendrás que combinarlo con otros modelos especializados. En documentos largos, la ventana de 1M tokens no elimina la necesidad de control de fuentes, permisos y trazabilidad. Un contexto mayor reduce fragmentación, pero no garantiza que el modelo use siempre el dato correcto.
Para producción, mide latencia, coste real con caché, tasa de reintentos, calidad por idioma y estabilidad ante prompts adversarios. No migres solo por precio. Crea un conjunto de evaluación con conversaciones reales, casos límite y ejemplos donde el modelo anterior fallaba.
Migración desde versiones previas
Si usas DeepSeek V3.2, R1 o alias antiguos, planifica la migración antes del 24 de julio de 2026. Sustituye deepseek-chat por deepseek-v4-flash en flujos generales y reserva deepseek-v4-pro para razonamiento intenso. Después, ajusta thinking, temperatura, límites de salida y pruebas de regresión.
Para una ruta paso a paso, consulta la guía de migración de DeepSeek V4 vs V3.2, revisa /pricing/ para estimar costes y valida los cambios técnicos en /docs/api/. También puedes comparar familias desde la página de DeepSeek V3.2.
Preguntas frecuentes
¿DeepSeek V4 Flash es mejor que DeepSeek V4 Pro?
No en capacidad máxima. DeepSeek V4 Flash es mejor cuando priorizas coste, velocidad y volumen. DeepSeek V4 Pro conviene para razonamiento más profundo, tareas críticas y el modo thinking-max.
¿Cuál es el ID de modelo de DeepSeek V4 Flash?
El ID de API es deepseek-v4-flash. Para la variante Pro, utiliza deepseek-v4-pro. Ambos se usan desde el endpoint compatible con OpenAI.
¿DeepSeek V4 Flash admite thinking-max?
No. DeepSeek V4 Flash admite non-thinking y thinking-high. El modo thinking-max está disponible solo en DeepSeek V4 Pro.
¿Puedo usar DeepSeek V4 Flash con código compatible con OpenAI?
Sí. La API usa una base compatible con OpenAI en https://api.deepseek.com/v1/. En muchos proyectos basta con cambiar la URL base, la clave API y el nombre del modelo.
¿Cuándo quedan obsoletos deepseek-chat y deepseek-reasoner?
Los alias heredados deepseek-chat y deepseek-reasoner quedan obsoletos el 24 de julio de 2026. Conviene migrar antes a deepseek-v4-flash o deepseek-v4-pro.
Conclusión
DeepSeek V4 Flash es una opción sólida si necesitas IA conversacional barata, rápida y preparada para mucho contexto. Su mayor atractivo está en producción: asistentes, automatizaciones, soporte y análisis documental con costes controlados. Empieza probándolo en tareas de bajo riesgo desde /chat/, mide calidad con tus propios datos y pasa a la API cuando tengas umbrales claros. Si una tarea exige más razonamiento, enrútala a DeepSeek V4 Pro.