
La comparativa DeepSeek V4 vs Claude Opus 4.7 enfrenta dos modelos grandes de razonamiento con prioridades distintas: DeepSeek V4 Pro busca coste bajo, contexto largo y pesos abiertos; Claude Opus 4.7 apuesta por máxima calidad en flujos complejos, herramientas de Anthropic y razonamiento adaptativo. Opus 4.7 con contexto de 1M tokens se anunció recientemente, el 16 de abril de 2026, así que conviene revisar precios, límites y cambios de API antes de migrar una carga de trabajo.
Resumen rápido
- Elige DeepSeek V4 Pro si tu prioridad es coste por volumen, automatización de código, contexto largo asequible o despliegues con pesos abiertos bajo licencia MIT.
- Elige Claude Opus 4.7 si necesitas la mejor lectura de matices, razonamiento abstracto de alto nivel, agentes con herramientas Anthropic o flujos empresariales donde el error cuesta más que la inferencia.
- Claude Opus 4.7 cuesta $5 por 1M tokens de entrada y $25 por 1M tokens de salida, según Anthropic. DeepSeek V4 Pro parte de una tarifa de lista de $1,74/$3,48 por 1M tokens, mucho más agresiva para uso intensivo [1][2].
- Ambos modelos soportan contexto de 1M tokens. DeepSeek V4 Pro declara hasta 384K tokens de salida; Claude Opus 4.7 declara 128K tokens máximos de salida [1][4].
- La diferencia de razonamiento importa: DeepSeek V4 Pro expone modos como
non-thinking,thinking-highythinking-max. Claude Opus 4.7 usa adaptive thinking y niveles de esfuerzo que pueden elevar el gasto en tokens [4]. - No hay ganador universal. Para producto con millones de llamadas, DeepSeek V4 Pro suele ser más racional. Para análisis legal, financiero, multimodal o tareas de agente con muchas dependencias, Claude Opus 4.7 puede justificar el sobrecoste.
Qué compara realmente DeepSeek V4 vs Claude Opus 4.7
DeepSeek V4 Pro y Claude Opus 4.7 pertenecen a la misma categoría de compra: modelos de frontera para tareas donde un modelo barato puede quedarse corto. Ambos pueden escribir código, razonar sobre documentos largos, usar herramientas y trabajar con instrucciones complejas. La decisión no se reduce a “cuál es más inteligente”, sino a qué coste, con qué control y dentro de qué ecosistema.
DeepSeek V4 Pro es la opción más atractiva cuando necesitas escalar. Sus precios de lista son más bajos, su API es compatible con el formato de OpenAI y sus pesos abiertos permiten auditoría, adaptación y despliegues con más control. Si ya utilizas la API de DeepSeek, el salto a deepseek-v4-pro es directo en la mayoría de integraciones.
Claude Opus 4.7, por su parte, se posiciona como el modelo prémium de Anthropic para razonamiento largo, agentes, visión y trabajo empresarial. Anthropic lo presenta como su modelo generalmente disponible más capaz, con mejoras en ingeniería de software, tareas de agente, memoria, visión de alta resolución y seguimiento literal de instrucciones [2][3][4].
La comparación también tiene una dimensión estratégica. DeepSeek V4 Pro favorece a equipos que quieren evitar dependencia total de un proveedor cerrado. Claude Opus 4.7 favorece a organizaciones que ya trabajan con Claude, Claude Code, Amazon Bedrock, Vertex AI, Microsoft Foundry o herramientas específicas de Anthropic.
Especificaciones clave: contexto, salida, API y apertura
La primera diferencia práctica está en la ficha técnica. Los dos modelos ofrecen una ventana de contexto de 1M tokens, suficiente para repositorios grandes, bases documentales extensas o sesiones de agente prolongadas. La ventaja de DeepSeek aparece en salida máxima y apertura. La ventaja de Claude aparece en herramientas, visión y madurez del entorno Anthropic.
| Característica | DeepSeek V4 Pro | Claude Opus 4.7 |
|---|---|---|
| Tipo de modelo | Modelo grande de razonamiento, familia DeepSeek V4 | Modelo prémium de razonamiento y agentes de Anthropic |
| Contexto | 1M tokens | 1M tokens |
| Salida máxima | Hasta 384K tokens | Hasta 128K tokens |
| Razonamiento | non-thinking, thinking-high, thinking-max | Adaptive thinking con niveles de esfuerzo |
| API | Compatible con OpenAI en https://api.deepseek.com/v1/ | Claude API, Bedrock, Vertex AI y Microsoft Foundry |
| Pesos | Abiertos con licencia MIT | Cerrados |
| Modelo recomendado | deepseek-v4-pro | claude-opus-4-7 |
Para probar DeepSeek sin preparar una integración completa, puedes usar el chat de DeepSeek en español. Para revisar la ficha general de la familia, la página de DeepSeek V4 resume diferencias entre Pro y Flash.
Un detalle operativo: los alias heredados deepseek-chat y deepseek-reasoner quedan deprecados el 24 de julio de 2026. Si mantienes código antiguo, conviene migrar a deepseek-v4-flash o deepseek-v4-pro con el modo de razonamiento adecuado.
Costes: dónde DeepSeek V4 Pro marca la diferencia
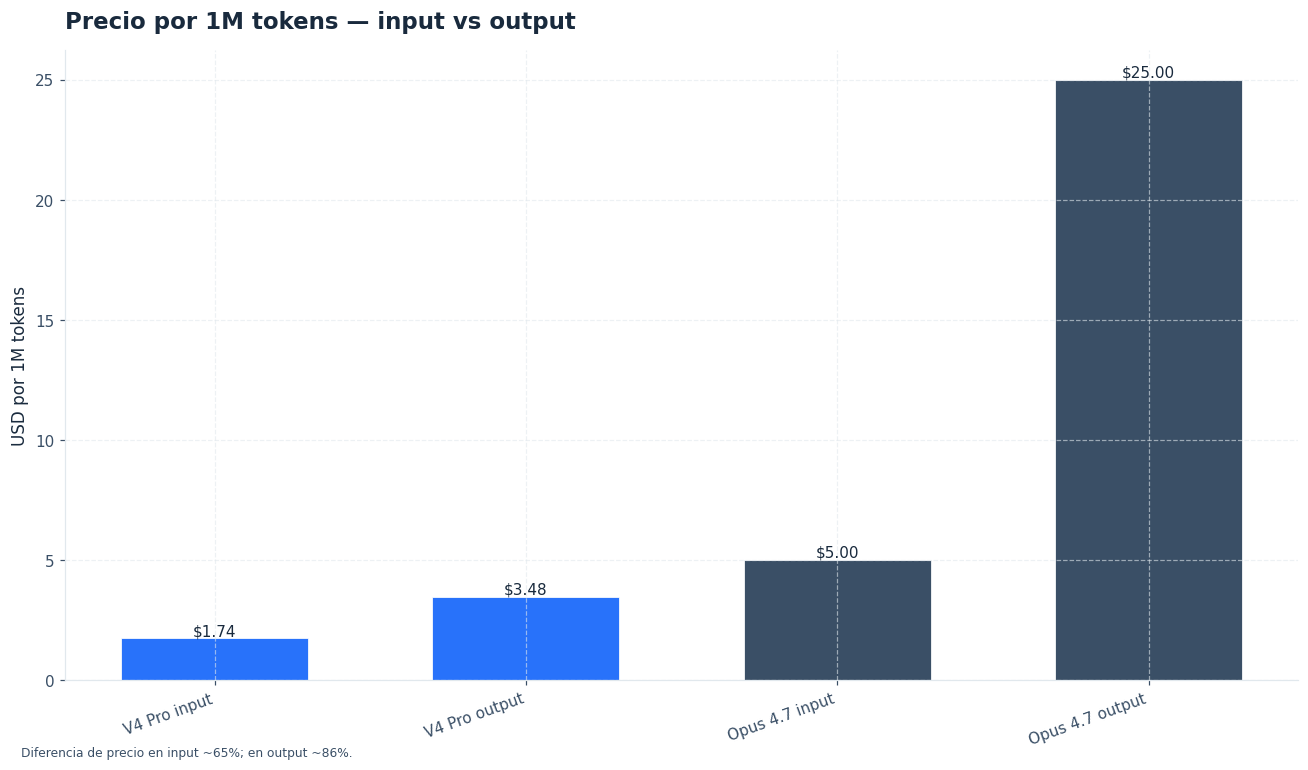
El precio es el argumento más fuerte para DeepSeek V4 Pro. Anthropic fija Claude Opus 4.7 en $5 por 1M tokens de entrada y $25 por 1M tokens de salida [2][3]. DeepSeek V4 Pro tiene una tarifa de lista de $1,74 por 1M tokens de entrada y $3,48 por 1M tokens de salida. La página oficial de DeepSeek puede mostrar descuentos promocionales temporales, así que la tabla siguiente usa tarifas de lista para no mezclar campañas con coste estructural [1].
Las tarifas pueden cambiar; verifica los importes vigentes en la página de planes y precios antes de presupuestar una integración.
| Escenario | DeepSeek V4 Pro | Claude Opus 4.7 | Lectura práctica |
|---|---|---|---|
| 1M entrada + 100K salida | $2,09 | $7,50 | Claude cuesta unas 3,6 veces más. |
| 500K entrada + 50K salida | $1,04 | $3,75 | DeepSeek encaja mejor en RAG y análisis masivo. |
| 100K entrada + 200K salida | $0,87 | $5,50 | La salida larga penaliza mucho más en Claude. |
| 10M entrada + 1M salida | $20,88 | $75,00 | La brecha crece en tareas de producción. |
En cargas reales, el coste final depende de caché, longitud de salida, herramientas, reintentos y razonamiento. Aun así, la diferencia de salida es difícil de ignorar. Claude Opus 4.7 cobra $25 por 1M tokens de salida; DeepSeek V4 Pro cobra $3,48. En agentes que generan planes, parches, explicaciones y registros largos, ese diferencial puede cambiar la arquitectura del producto.
Claude compensa parte del coste con prompt caching y procesamiento por lotes. Anthropic indica hasta un 90 % de ahorro con caché de prompts y 50 % con lotes [3]. DeepSeek también incluye precios de caché y una versión más económica, DeepSeek V4 Flash, con $0,14 de entrada y $0,28 de salida por 1M tokens. Para tareas donde no necesitas thinking-max, Flash reduce el coste de forma drástica.
Razonamiento: modos de DeepSeek frente a adaptive thinking
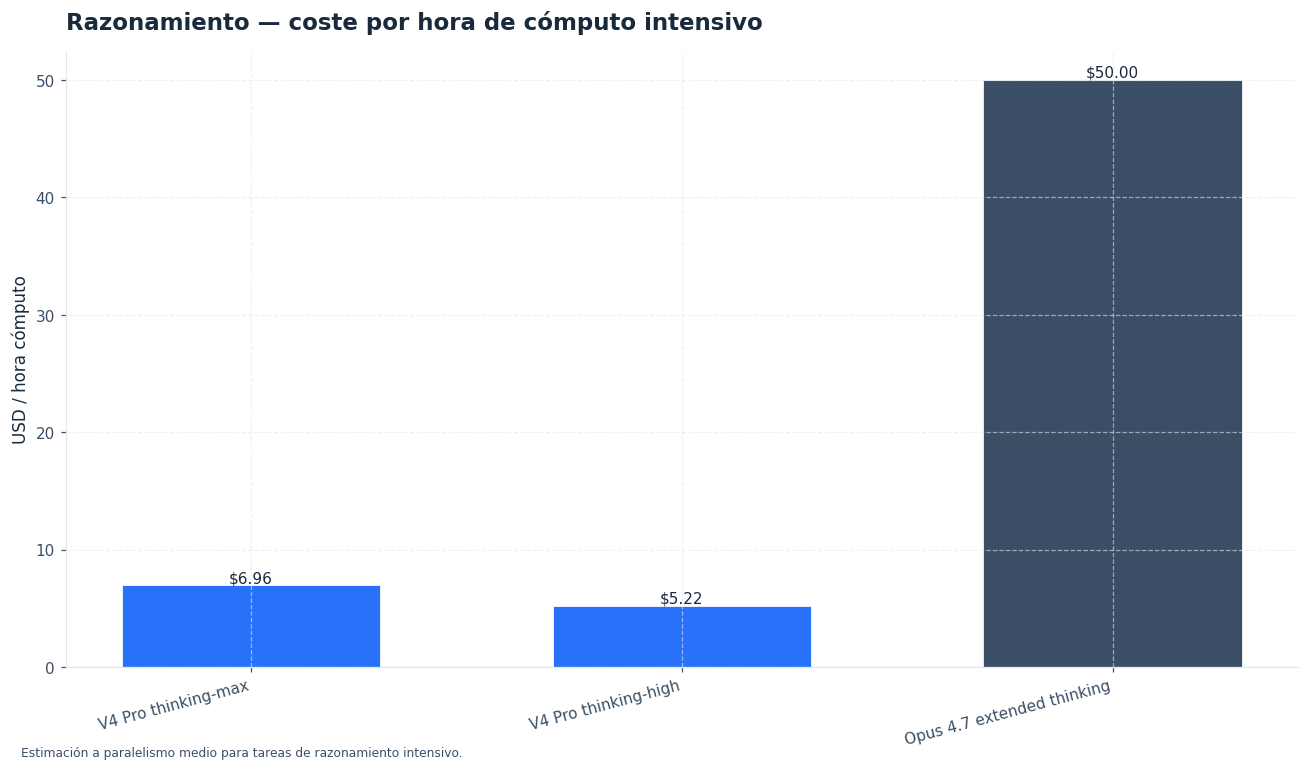
La segunda diferencia clave está en cómo se controla el razonamiento. DeepSeek V4 Pro separa modos. Puedes ejecutar una petición en non-thinking para respuestas rápidas, subir a thinking-high para análisis complejo o usar thinking-max cuando quieres exprimir el modelo. Solo DeepSeek V4 Pro incluye thinking-max; V4 Flash queda en modos más ligeros.
Claude Opus 4.7 cambió el enfoque. Anthropic retiró los presupuestos clásicos de extended thinking en favor de adaptive thinking. También introdujo niveles de esfuerzo, incluido xhigh, orientado a código y agentes. La propia documentación explica que el parámetro de esfuerzo permite intercambiar capacidad por velocidad y gasto en tokens [4].
Esto tiene una consecuencia económica. En DeepSeek, el modo de razonamiento se expone como una decisión explícita dentro del modelo, sin un recargo separado por “nivel” de razonamiento. En Claude, el razonamiento adaptativo y el esfuerzo se monetizan de forma indirecta: más esfuerzo puede implicar más tokens de salida, más latencia y una factura mayor. No es un precio fijo adicional, pero sí una palanca de coste.
Para un equipo técnico, la diferencia se nota en control presupuestario. DeepSeek permite diseñar rutas como: Flash para clasificación, V4 Pro sin razonamiento para respuestas simples y V4 Pro thinking-max para revisión final. Claude Opus 4.7 funciona mejor cuando aceptas delegar más al modelo y ajustar esfuerzo según calidad esperada.
Código y agentes: cuándo gana cada modelo
En código, la respuesta depende del tipo de trabajo. Claude Opus 4.7 es especialmente fuerte en tareas largas con dependencias, cambios en varios archivos, análisis de errores poco obvios y flujos donde el modelo debe verificar su propia salida. Anthropic destaca mejoras en ingeniería de software avanzada, tareas prolongadas, uso de herramientas y seguimiento de instrucciones [2][3].
DeepSeek V4 Pro gana cuando el trabajo de código se repite mucho. Si tienes que revisar miles de incidencias, generar pruebas, migrar patrones, explicar cambios o alimentar agentes internos, el coste por token pesa más que una ligera ventaja de razonamiento. Los pesos abiertos también ayudan si el equipo quiere inspeccionar, adaptar o ejecutar variantes fuera de la nube pública.
Una estrategia práctica es combinar ambos. Usa DeepSeek V4 Pro para el 80% de tareas de programación: lectura de repositorios, generación de parches, pruebas, documentación y análisis de registros. Reserva Claude Opus 4.7 para bloqueos de alto valor: diseños difíciles, revisión arquitectónica, errores intermitentes o decisiones donde una interpretación sutil cambia el resultado.
El siguiente ejemplo muestra una llamada básica a DeepSeek V4 Pro con formato compatible con OpenAI. Ajusta el modo de razonamiento según la carga de trabajo definida en tu integración.
curl https://api.deepseek.com/v1/chat/completions \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-v4-pro",
"messages": [
{
"role": "system",
"content": "Actúa como revisor senior de código. Sé preciso y prioriza riesgos reales."
},
{
"role": "user",
"content": "Analiza este diff y devuelve: riesgos, pruebas faltantes y una propuesta de parche."
}
],
"reasoning_mode": "thinking-high",
"max_tokens": 4096
}'Si tu producto ya usa SDK de OpenAI, esta compatibilidad reduce el trabajo de migración. Revisa también la página de precios de DeepSeek antes de estimar un presupuesto, porque la caché y las promociones temporales pueden cambiar el coste real.
Contexto largo: 1M tokens no significa el mismo coste
Ambos modelos permiten trabajar con ventanas de 1M tokens, pero no se usan igual. En Claude Opus 4.7, Anthropic indica que el contexto de 1M tokens se ofrece a precio estándar de API, sin prima de contexto largo [4]. Eso elimina una barrera típica en modelos cerrados. Aun así, el precio base de Claude sigue siendo alto frente a DeepSeek.
En DeepSeek V4 Pro, el contexto largo es más económico y la salida máxima de 384K tokens abre casos más agresivos: generación de informes extensos, síntesis de expedientes completos, refactorizaciones con explicación detallada o agentes que devuelven planes largos. Esa salida máxima no debe usarse por defecto, pero da margen cuando una tarea lo requiere.
Claude Opus 4.7 tiene un matiz técnico: usa un nuevo tokenizador que puede generar entre 1x y 1,35x tokens frente a modelos Claude anteriores, según el contenido. Anthropic recomienda contar tokens y ajustar presupuestos, porque la eficiencia puede variar por tipo de carga [4]. En migraciones desde Opus 4.6, esta diferencia puede elevar el coste efectivo aunque la tarifa por token no cambie.
Para recuperación aumentada con generación (RAG), DeepSeek V4 Pro suele ser la opción base. Permite pasar más documentos por dólar y experimentar con estrategias de contexto amplio. Claude Opus 4.7 entra cuando la tarea exige una lectura más fina: contratos ambiguos, documentos con excepciones, decisiones financieras o análisis donde la omisión de un matiz puede ser cara.
Privacidad, control y dependencia de proveedor
La apertura de pesos cambia la conversación. DeepSeek V4 Pro, al distribuirse con licencia MIT, resulta más flexible para equipos que necesitan auditoría, investigación, adaptación interna o despliegues con más soberanía técnica. No todas las organizaciones van a ejecutar un modelo de ese tamaño por su cuenta, pero tener la opción reduce dependencia.
Claude Opus 4.7 es cerrado. A cambio, Anthropic aporta una plataforma madura, integraciones empresariales, herramientas de agente, documentación amplia y disponibilidad en nubes relevantes. Para muchas empresas, ese paquete operativo pesa más que la apertura. El modelo cerrado simplifica compras, soporte y cumplimiento cuando ya existe relación con Anthropic o con un proveedor de nube compatible.
La elección también depende de política de datos. Si no puedes enviar ciertos datos a un proveedor externo, DeepSeek V4 Pro puede encajar mejor en una arquitectura híbrida. Si ya tienes controles aprobados para Claude en Bedrock, Vertex AI o Microsoft Foundry, Claude Opus 4.7 puede ser más fácil de introducir sin rediseñar procesos.
Para uso individual, la decisión es más simple. Si quieres conversar, comparar respuestas y probar casos reales, empieza con DeepSeek Chat. Si necesitas desplegar producto, mide coste por tarea resuelta, no solo puntuaciones de referencia.
Recomendación por caso de uso
La comparativa DeepSeek V4 vs Claude Opus 4.7 se entiende mejor por escenarios. Cada modelo gana en un tipo de restricción distinto: presupuesto, calidad máxima, control, herramientas o velocidad de integración.
- Agentes de código a gran escala: empieza con DeepSeek V4 Pro. Usa Claude Opus 4.7 como revisor prémium en tareas bloqueadas.
- Producto SaaS con muchas llamadas: DeepSeek V4 Pro o DeepSeek V4 Flash reducen coste y permiten experimentar más.
- Análisis legal o financiero sensible: Claude Opus 4.7 puede ganar por matiz, calibración y disciplina en instrucciones complejas.
- RAG sobre millones de documentos: DeepSeek V4 Pro ofrece mejor economía de contexto largo.
- Flujos ya basados en Claude Code o herramientas Anthropic: Claude Opus 4.7 reduce fricción de adopción.
- Investigación, adaptación o despliegue soberano: DeepSeek V4 Pro gana por pesos abiertos y licencia MIT.
Una regla simple: si una tarea puede repetirse 10.000 veces al mes, prueba primero DeepSeek. Si una tarea se ejecuta pocas veces pero afecta a una decisión crítica, prueba Claude Opus 4.7 y compara calidad humana revisada.
Preguntas frecuentes
¿Claude Opus 4.7 es más caro que DeepSeek V4 Pro?
Sí. Claude Opus 4.7 cuesta $5 por 1M tokens de entrada y $25 por 1M tokens de salida. DeepSeek V4 Pro tiene una tarifa de lista de $1,74 y $3,48, respectivamente. La diferencia se nota mucho en salidas largas y agentes con varios pasos.
¿Cuál conviene para programar?
Para volumen, generación de pruebas, refactorizaciones y revisión continua, DeepSeek V4 Pro suele ser mejor compra. Para errores difíciles, razonamiento abstracto, diseño de arquitectura o flujos con herramientas Anthropic, Claude Opus 4.7 puede ofrecer una respuesta más fiable.
¿Los dos modelos tienen contexto de 1M tokens?
Sí. DeepSeek V4 Pro y Claude Opus 4.7 soportan contexto de 1M tokens. La diferencia está en coste, salida máxima y comportamiento. DeepSeek V4 Pro declara hasta 384K tokens de salida; Claude Opus 4.7 declara 128K tokens máximos.
¿Qué significa que DeepSeek V4 Pro tenga pesos abiertos?
Significa que el modelo puede evaluarse, adaptarse y desplegarse con más control que un modelo cerrado. Para investigación, cumplimiento interno o soberanía técnica, esa apertura puede ser tan relevante como el precio de API.
¿Claude Opus 4.7 conserva extended thinking?
No en el formato clásico de presupuestos fijos. Anthropic cambió a adaptive thinking con niveles de esfuerzo. En la práctica, subir el esfuerzo puede mejorar tareas difíciles, pero también puede aumentar tokens, latencia y coste.
Conclusión
DeepSeek V4 Pro es la elección lógica si buscas coste bajo, contexto largo, código a escala y control mediante pesos abiertos. Claude Opus 4.7 tiene sentido cuando la prioridad es calidad máxima en razonamiento complejo, agentes con herramientas Anthropic, visión o tareas empresariales de alto impacto. La mejor decisión no sale de una prueba de referencia aislada: mide coste por tarea resuelta, tasa de revisión humana y estabilidad en tus datos. Empieza con DeepSeek V4 Pro como base y reserva Claude Opus 4.7 para los casos donde su precisión compense el precio.
Fuentes
’]