
Este generador de prompts para DeepSeek V4 te ayuda a transformar una idea vaga en una instrucción clara, estructurada y lista para copiar. Combina rol, tarea, audiencia, tono, longitud, formato de salida y ejemplos para que obtengas respuestas más consistentes en el chat o en la API.
Generador de prompts para DeepSeek V4
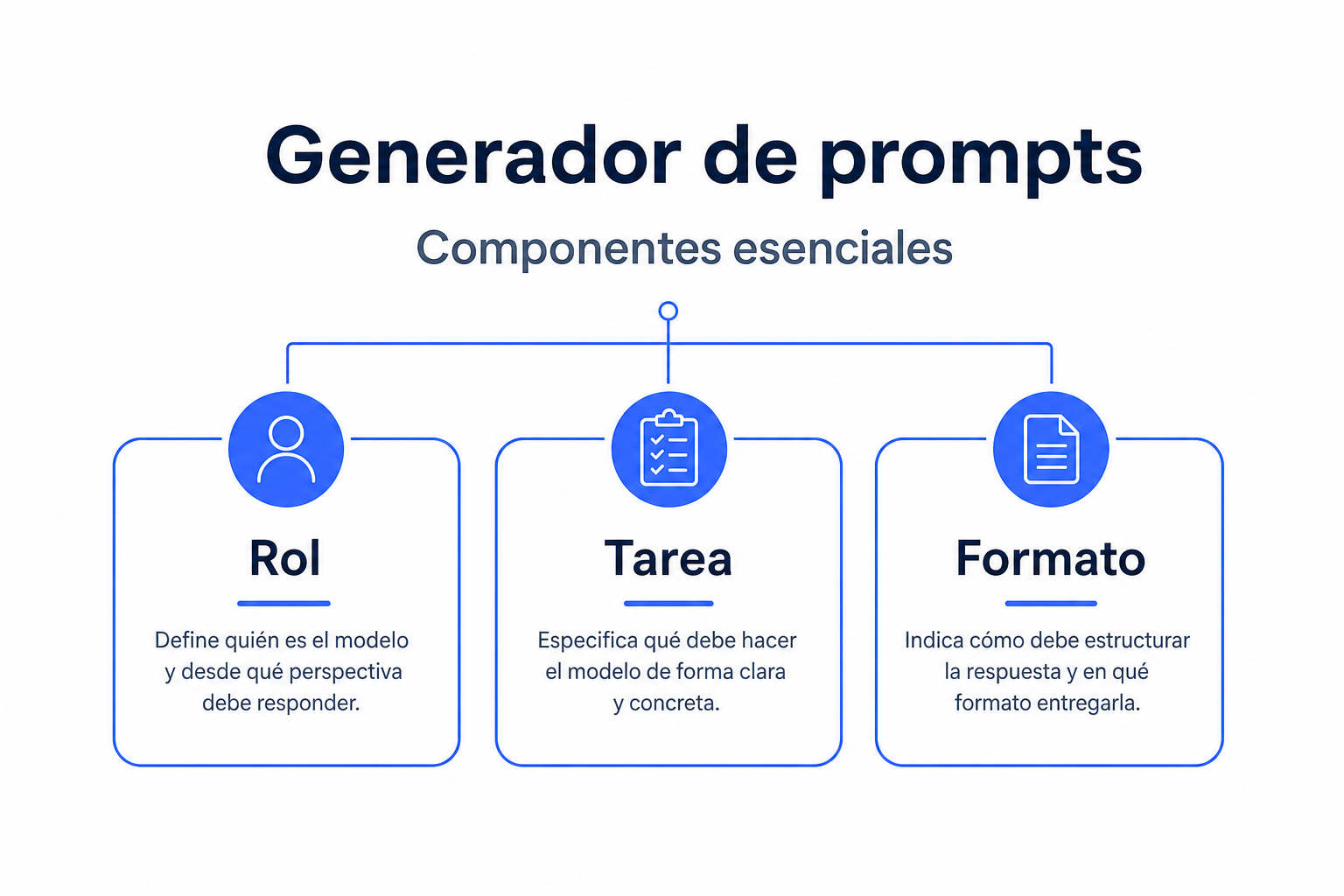
Cómo usar esta herramienta
La herramienta está pensada para crear un prompt completo sin escribirlo desde cero. Empieza por definir el rol que debe adoptar DeepSeek V4. No es lo mismo pedir una respuesta como “redactor técnico” que como “analista financiero” o “profesor de secundaria”. El rol acota el punto de vista y reduce respuestas genéricas.
Después, describe la tarea con un verbo claro: resumir, comparar, explicar, corregir, clasificar, generar código o convertir un texto a otro formato. Añade la audiencia para ajustar el nivel. Una explicación para un equipo legal no requiere el mismo vocabulario que una guía para personas sin perfil técnico.
Elige el tono, la longitud aproximada y el formato de salida. Si necesitas una tabla, una lista numerada, JSON o un correo electrónico, indícalo aquí. DeepSeek V4 suele seguir mejor las instrucciones cuando el formato aparece de forma explícita, especialmente en tareas repetibles.
Si tienes una muestra de respuesta ideal, activa el ejemplo few-shot. Un ejemplo few-shot es una pequeña demostración de entrada y salida esperada. Sirve para enseñar el patrón sin entrenar el modelo. Al final, copia el prompt generado y pégalo en el chat, o intégralo como mensaje de sistema o usuario en tu llamada a la API.
Qué calcula (la matemática detrás)
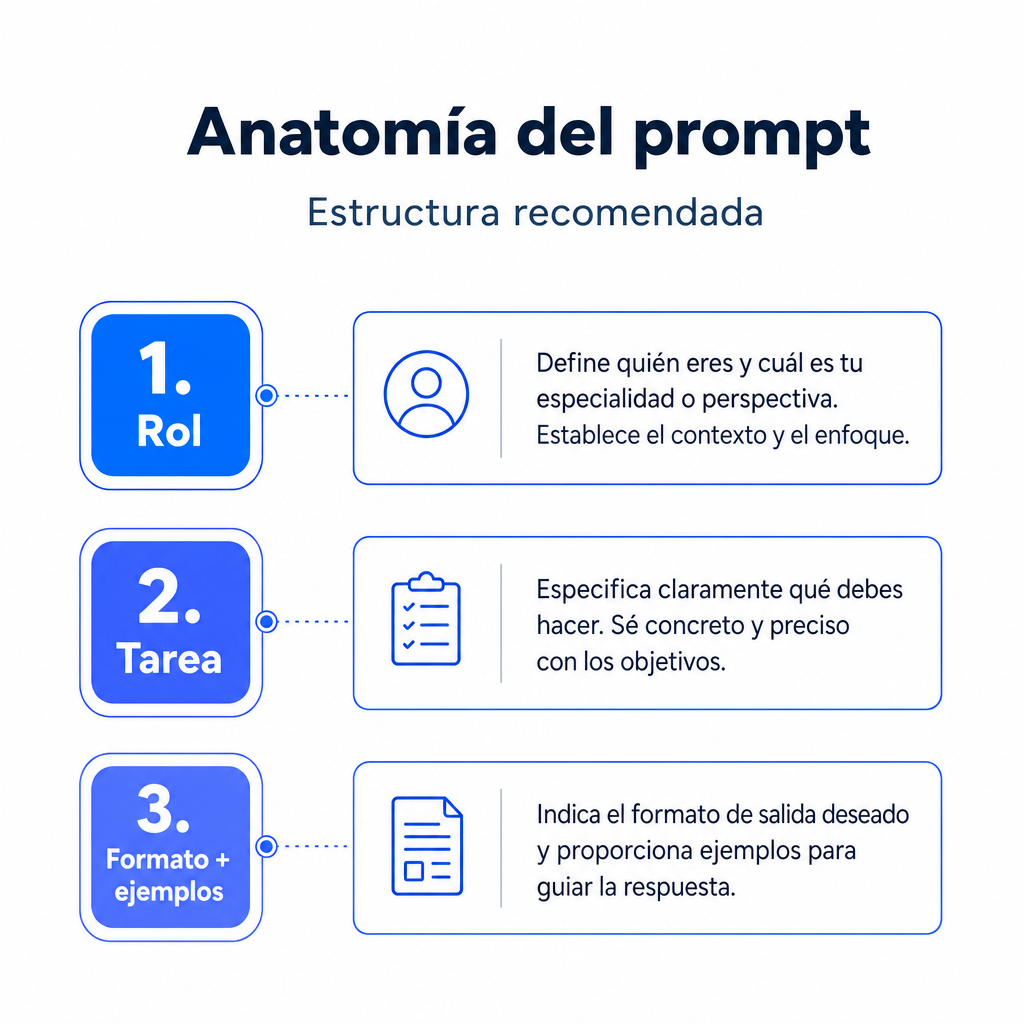
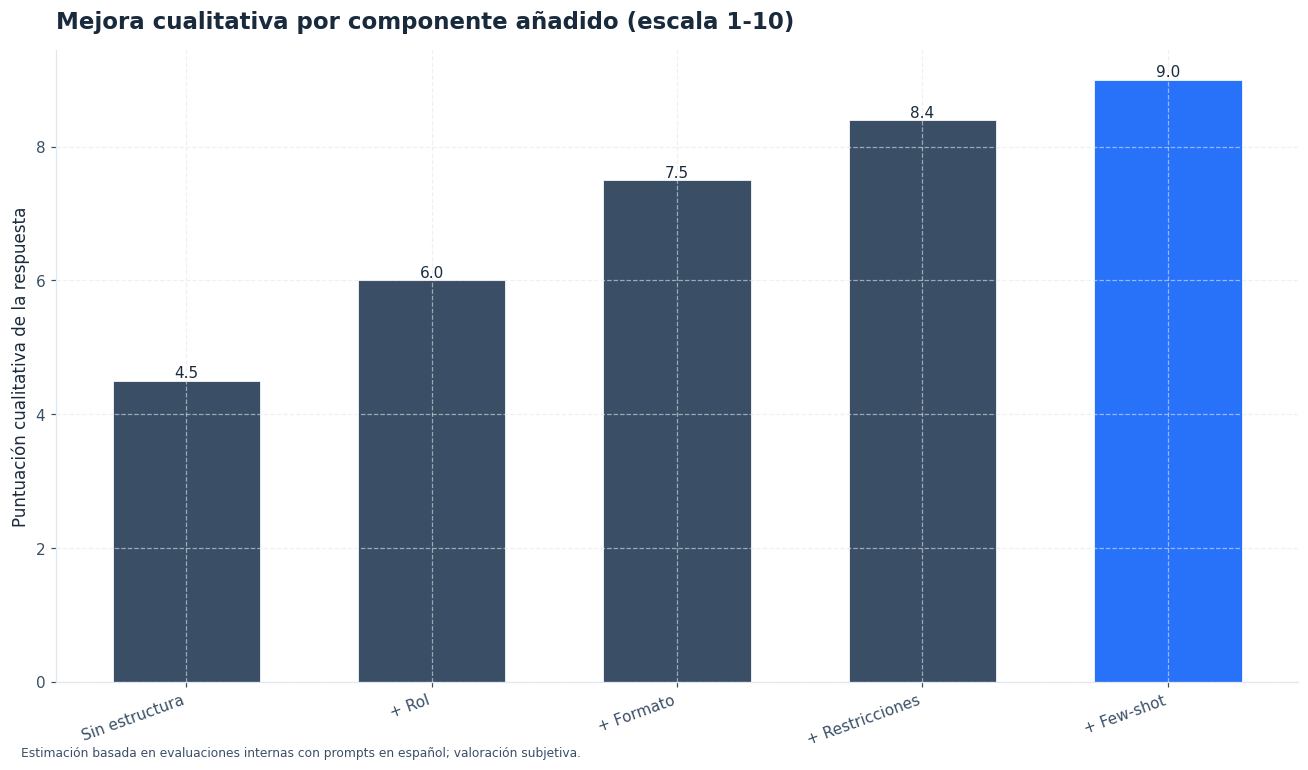
El generador no “adivina” el prompt perfecto. Aplica una lógica de composición. Cada campo añade una pieza a una plantilla estructurada: rol, objetivo, contexto, restricciones, formato, criterios de calidad y ejemplo opcional. El resultado es una instrucción más completa que una petición suelta.
La fórmula conceptual puede expresarse así: Prompt final = R + T + A + To + L + F + C + E. R es el rol, T la tarea, A la audiencia, To el tono, L la longitud, F el formato, C las restricciones y E el ejemplo few-shot. Cuando falta una parte, el prompt sigue funcionando, pero pierde precisión.
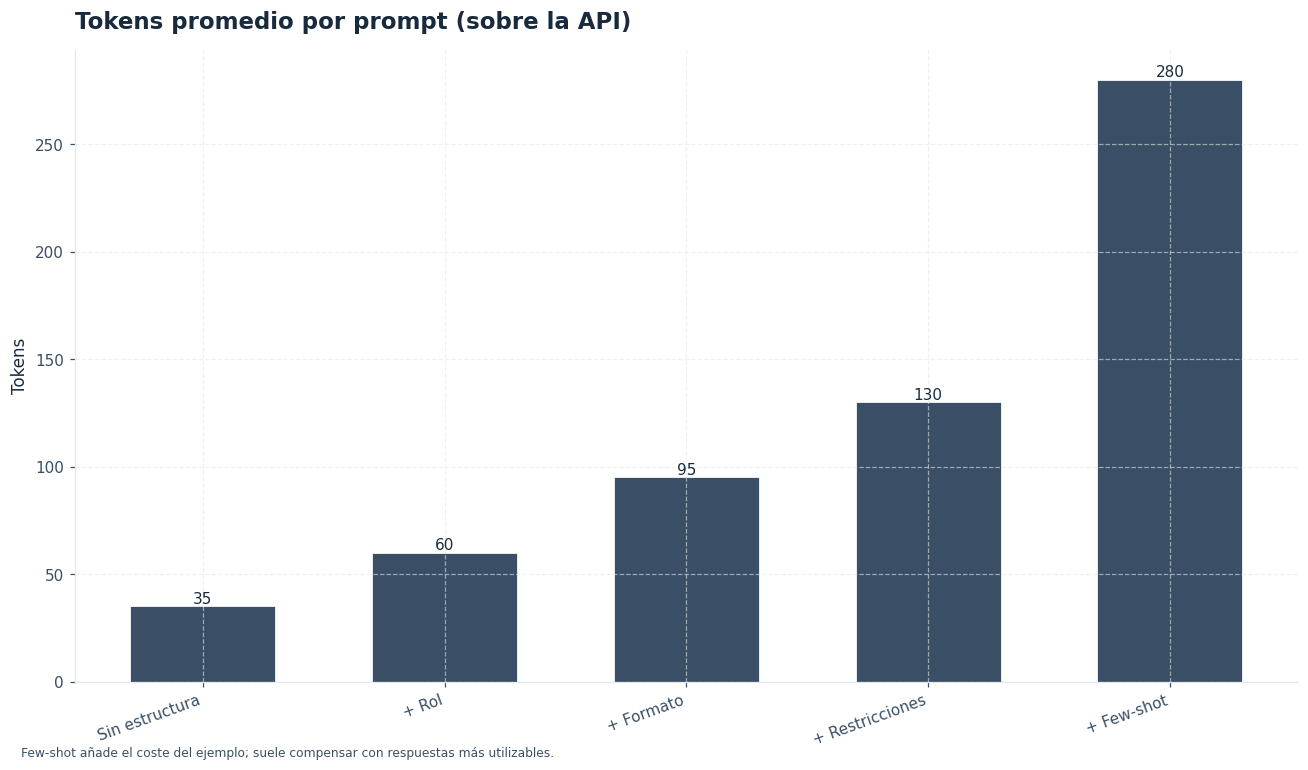
También puede estimarse el tamaño aproximado del prompt. DeepSeek V4 utiliza tokenización BPE, una técnica que divide el texto en unidades frecuentes. Para español, una heurística práctica es usar unos 3,7 caracteres por token. En inglés, la referencia aproximada es 4,0 caracteres por token. No sustituye al tokenizador real, pero ayuda a prever coste y contexto.
Si usas la API, el coste depende de los tokens de entrada y salida. Con datos de mayo de 2026, DeepSeek V4 Flash cuesta $0,14 por 1M tokens de entrada y $0,28 por 1M tokens de salida. DeepSeek V4 Pro cuesta $1,74 por 1M tokens de entrada y $3,48 por 1M tokens de salida. En entradas repetidas, la caché puede reducir el coste de entrada: $0,028 en DeepSeek V4 Flash y $0,87 en DeepSeek V4 Pro por 1M tokens.
Las tarifas pueden cambiar; verifica los importes vigentes en la página de planes y precios antes de presupuestar una integración.
Ejemplo trabajado
Prompt en español:
- Longitud del prompt generado: 2.220 caracteres
- Respuesta esperada: 4.500 caracteres
- Modelo elegido: DeepSeek V4 Flash
- Heurística español: 3,7 caracteres/token
Tokens de entrada ≈ 2.220 / 3,7 = 600 tokens
Tokens de salida ≈ 4.500 / 3,7 = 1.216 tokens
Precio DeepSeek V4 Flash:
- Entrada: $0,14 por 1.000.000 tokens
- Salida: $0,28 por 1.000.000 tokens
Coste entrada ≈ (600 / 1.000.000) × 0,14 = $0,000084
Coste salida ≈ (1.216 / 1.000.000) × 0,28 = $0,000340
Coste total estimado ≈ $0,000424La ventana de contexto también condiciona el diseño del prompt. DeepSeek V4 Pro admite hasta 1M tokens de contexto y hasta 384K tokens de salida. Esa capacidad permite incluir documentos extensos, pero no elimina la necesidad de ordenar la instrucción. Un contexto grande mal estructurado puede producir respuestas largas, caras y menos fáciles de auditar.
Casos de uso típicos
Un buen generador de prompts para DeepSeek V4 es útil cuando necesitas repetir una tarea con calidad estable. Estos escenarios aprovechan especialmente la combinación de rol, formato y restricciones.
- Redacción técnica. Crea instrucciones para explicar una API, documentar una función, convertir notas en una guía o generar ejemplos de uso. El formato puede fijarse como Markdown, tabla o pasos numerados.
- Análisis de documentos largos. Define un rol de analista, una tarea de extracción y un formato de salida con campos concretos. Es útil para contratos, informes, actas, requisitos de producto o transcripciones.
- Atención al cliente. Genera prompts que indiquen tono, límites, estilo de respuesta y criterios de escalado. Así puedes obtener borradores coherentes sin dejar que el modelo invente políticas.
- Programación asistida. Pide a DeepSeek V4 que revise código, escriba pruebas, explique errores o proponga refactorizaciones. Incluye lenguaje, versión, restricciones y formato de entrega para reducir ambigüedad.
- Contenido educativo. Ajusta la audiencia, el nivel de detalle y el tipo de ejercicio. Por ejemplo, puedes pedir una explicación para bachillerato, una rúbrica de evaluación o una actividad con respuestas comentadas.
Para tareas rápidas y coste bajo, DeepSeek V4 Flash suele encajar bien. Para análisis más exigentes, razonamiento largo o salidas muy extensas, DeepSeek V4 Pro ofrece más margen de contexto y salida.
Errores frecuentes al escribir prompts
Los fallos más comunes no vienen del modelo, sino de instrucciones incompletas. Un prompt eficaz reduce decisiones implícitas y deja claro cómo debe evaluarse la respuesta.
- Pedir una tarea demasiado amplia. “Haz un análisis” obliga al modelo a decidir el enfoque. Sustitúyelo por una acción concreta: “compara riesgos, beneficios y requisitos técnicos en una tabla”.
- No indicar la audiencia. Sin público objetivo, DeepSeek V4 puede responder con un nivel inadecuado. Añade si escribes para dirección, equipo técnico, alumnado, clientes o soporte interno.
- Mezclar varias salidas incompatibles. Pedir JSON válido y explicación libre en el mismo bloque suele romper el formato. Separa la salida principal de las notas, o pide solo JSON.
- Omitir restricciones. Si no quieres suposiciones, invenciones o recomendaciones legales, dilo. Una restricción útil es: “si falta información, enumera las preguntas necesarias antes de responder”.
- No aportar ejemplos. Cuando el estilo importa, un ejemplo breve ahorra muchas correcciones. Usa un caso de entrada y una salida ideal, aunque sean sintéticos.
- Confundir longitud con calidad. Una respuesta larga no siempre es mejor. Define extensión, estructura y criterios: “máximo 500 palabras, con tres riesgos y una recomendación final”.
La herramienta evita estos errores al convertir cada decisión en un campo separado. Así puedes revisar el prompt antes de usarlo y detectar si falta contexto, formato o criterio de evaluación.
Preguntas frecuentes
¿Qué es un prompt para DeepSeek V4?
Es la instrucción que entregas al modelo para guiar su respuesta. Puede incluir rol, tarea, contexto, audiencia, tono, formato y límites. Cuanto más clara sea la instrucción, menos tendrá que inferir el modelo.
¿Sirve el mismo prompt para DeepSeek V4 Flash y DeepSeek V4 Pro?
Sí, la estructura general sirve para ambos. La diferencia está en el tipo de tarea. DeepSeek V4 Flash encaja con respuestas rápidas y alto volumen. DeepSeek V4 Pro es más adecuado para contexto grande, análisis largo o salidas extensas.
¿Cuándo conviene usar un ejemplo few-shot?
Úsalo cuando el formato, el tono o el criterio de respuesta sean difíciles de explicar solo con instrucciones. Un ejemplo breve de entrada y salida ayuda a fijar el patrón. No hace falta añadir muchos ejemplos si uno representa bien el caso.
¿Un prompt más largo siempre mejora la respuesta?
No. Un prompt largo puede incluir ruido, duplicar instrucciones o aumentar el coste. Es mejor escribir una instrucción completa, pero compacta. Añade contexto útil y elimina detalles que no cambien la respuesta esperada.
¿Cómo se estima el coste de un prompt?
Primero estima tokens de entrada y salida. En español, puedes dividir caracteres entre 3,7 como aproximación. Luego multiplica esos tokens por la tarifa del modelo elegido. La cifra exacta puede variar según el tokenizador real y la longitud final de la respuesta.
¿Qué pasa con DeepSeek V3.2 y los alias antiguos?
DeepSeek V3.2 queda como modelo heredado, con precios de $0,28 por 1M tokens de entrada y $0,42 por 1M tokens de salida. Los alias deepseek-chat y deepseek-reasoner se deprecan el 24 de julio de 2026, así que conviene migrar a identificadores actuales.
Recursos adicionales
Estos recursos te ayudan a pasar del prompt generado a una integración real con DeepSeek V4:
- Guía principal de DeepSeek en español
- Precios de DeepSeek V4 y modelos disponibles
- Documentación práctica de la API
- Ficha completa de DeepSeek V4
- Cuándo usar DeepSeek V4 Pro
- DeepSeek V4 Flash para tareas rápidas
Conclusión
Un buen prompt convierte una petición ambigua en una instrucción verificable. Usa el generador para fijar rol, tarea, audiencia, tono, longitud y formato antes de enviar nada a DeepSeek V4. Si el resultado no encaja, ajusta un campo cada vez: cambia la audiencia, añade restricciones o incorpora un ejemplo few-shot. Esa iteración controlada mejora la calidad sin aumentar de forma innecesaria el coste ni la complejidad.