
Este contador estima cuántos tokens consumirá un texto en español al enviarlo a la API de DeepSeek V4. Obtendrás caracteres, palabras, tokens estimados y coste de entrada aproximado para DeepSeek V4 Flash y DeepSeek V4 Pro.
Contador de tokens (estimación) para texto en español
Cómo usar esta herramienta
La herramienta está pensada para estimar el consumo antes de llamar a la API. Pega tu texto en el campo principal: puede ser una instrucción, un artículo, una transcripción, un bloque JSON o el contenido completo que enviarás como entrada al modelo.
Después revisa los cuatro indicadores. Caracteres cuenta letras, espacios, signos y saltos de línea. Palabras da una medida legible del tamaño del texto. Tokens estimados convierte esos caracteres a una aproximación compatible con español. Coste de entrada aplica las tarifas de DeepSeek V4 Flash y DeepSeek V4 Pro por 1M tokens.
Para obtener una estimación más realista, pega exactamente lo que enviarás a la API. Incluye instrucciones del sistema, mensajes anteriores, datos de contexto y cualquier texto adicional que acompañe a la petición. Si tu aplicación añade plantillas, etiquetas XML o campos JSON, también deben entrar en el cálculo.
Usa DeepSeek V4 Flash cuando quieras validar costes de alto volumen con baja latencia. Usa DeepSeek V4 Pro si necesitas estimar tareas más exigentes, razonamiento largo o contextos extensos. Puedes comparar ambos modelos con más detalle en la guía de DeepSeek V4.
El resultado no sustituye al recuento exacto del tokenizador oficial, pero sirve para presupuestar, limitar formularios y detectar entradas demasiado largas antes de procesarlas.
Qué calcula (la matemática detrás)
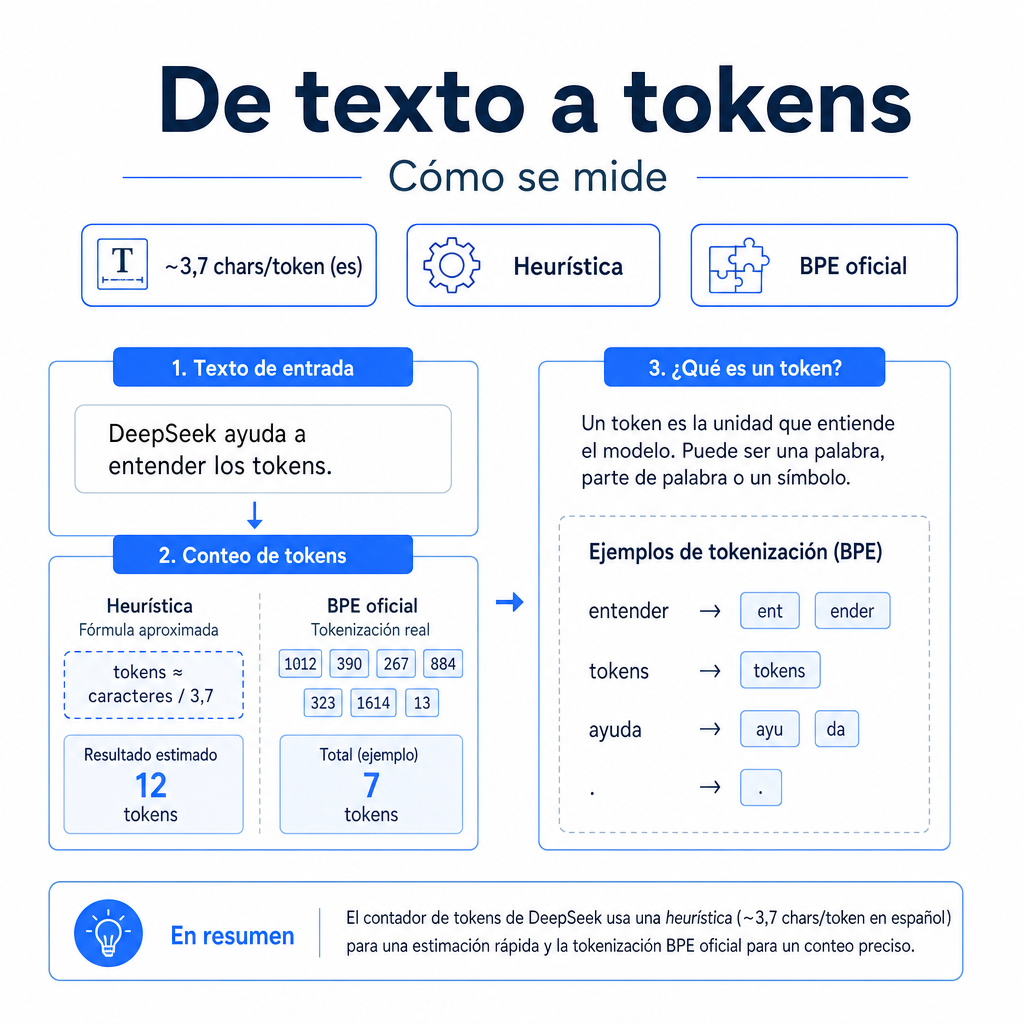
DeepSeek usa tokenización BPE, siglas de Byte Pair Encoding. Este método divide el texto en unidades frecuentes: palabras completas, fragmentos de palabra, signos, espacios y símbolos. Por eso un token no equivale siempre a una palabra ni a un carácter.
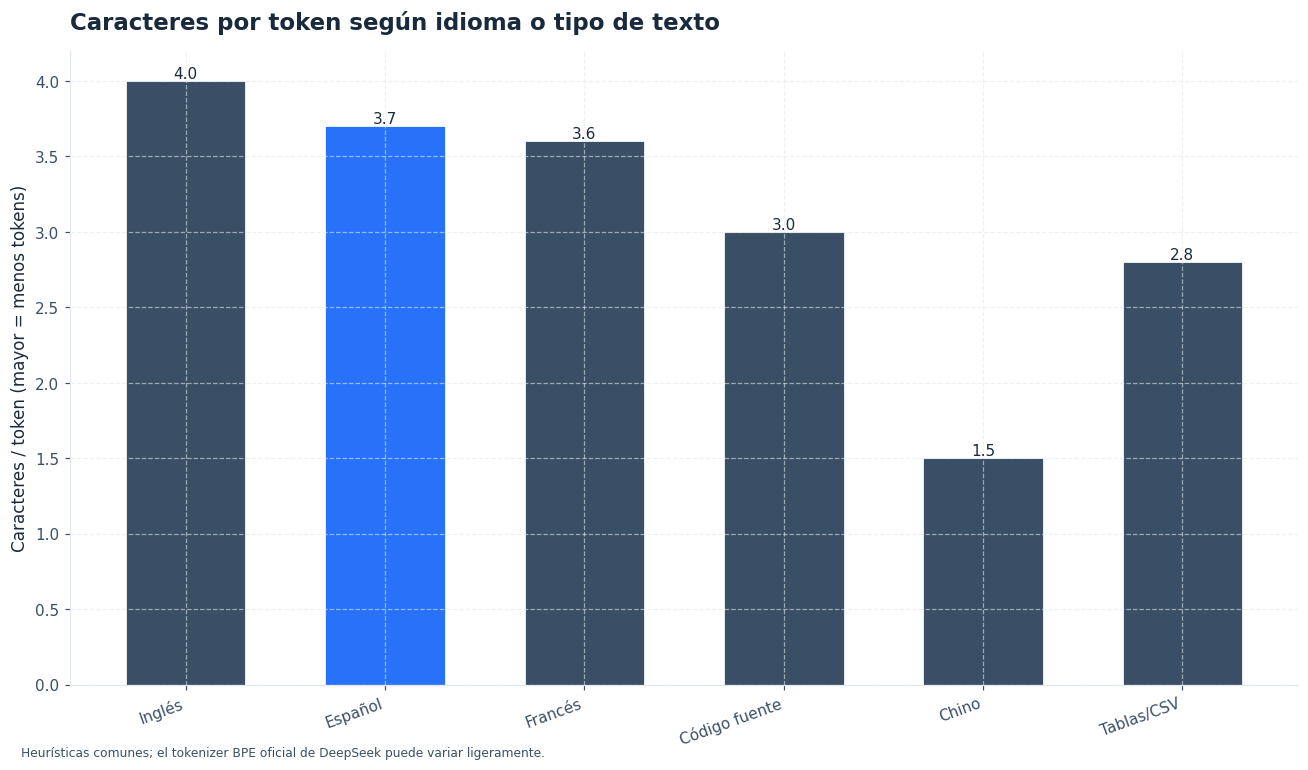
En español, una regla práctica razonable es usar unos 3,7 caracteres por token. El inglés suele acercarse más a 4,0 caracteres por token. La diferencia aparece porque las palabras españolas tienden a ser algo más largas y contienen acentos, formas verbales y terminaciones que pueden segmentarse de forma distinta.
La herramienta aplica una heurística directa: divide el número de caracteres entre 3,7 y redondea el resultado. Después calcula el coste de entrada con las tarifas verificadas de mayo de 2026. DeepSeek V4 Flash cuesta $0,14 por 1M tokens de entrada. DeepSeek V4 Pro cuesta $1,74 por 1M tokens de entrada.
Las tarifas pueden cambiar; verifica los importes vigentes en la página de planes y precios antes de presupuestar una integración.
El cálculo del coste de entrada es lineal. Si un texto consume el doble de tokens, el coste también se duplica. La fórmula base es: tokens estimados ÷ 1.000.000 × precio por 1M tokens. Esta herramienta se centra en entrada, no en salida. Para estimar una respuesta completa, añade aparte los tokens generados por el modelo.
DeepSeek V4 también contempla precios de caché. En entrada con caché reutilizada, DeepSeek V4 Flash baja a $0,028 por 1M tokens y DeepSeek V4 Pro a $0,87 por 1M tokens. Esa situación depende de cómo estructures las peticiones y de si el prefijo se repite.
Ejemplo trabajado
Texto en español: 7.400 caracteres
Heurística: 3,7 caracteres por token
Tokens estimados:
7.400 / 3,7 = 2.000 tokens
Coste de entrada en DeepSeek V4 Flash:
2.000 / 1.000.000 × $0,14 = $0,00028
Coste de entrada en DeepSeek V4 Pro:
2.000 / 1.000.000 × $1,74 = $0,00348
Si además esperas 1.500 tokens de salida:
Flash salida: 1.500 / 1.000.000 × $0,28 = $0,00042
Pro salida: 1.500 / 1.000.000 × $3,48 = $0,00522En contextos grandes, esta diferencia se acumula rápido. Un único texto de 2.000 tokens cuesta fracciones de céntimo. Un flujo con millones de entradas al mes requiere medir y limitar tokens con más cuidado.
Casos de uso típicos
- Presupuestar llamadas a la API. Antes de integrar DeepSeek en producción, pega ejemplos reales de entrada y estima el coste mensual. Multiplica los tokens por el número de peticiones previstas. Para comparar tarifas actualizadas, consulta la página de precios de DeepSeek.
- Diseñar límites de formularios. Si tu producto acepta textos largos, el contador ayuda a fijar límites por caracteres o tokens. Así evitas entradas que disparen el coste o superen el tamaño esperado del contexto.
- Optimizar instrucciones del sistema. Muchas aplicaciones repiten un mismo prompt de sistema en cada petición. Medirlo permite recortar frases redundantes, mover información estable a caché y reducir gasto sin perder precisión.
- Preparar documentos para análisis. Resúmenes, contratos, transcripciones y artículos largos pueden fragmentarse antes de enviarlos. El contador ayuda a decidir si conviene procesar el texto entero o dividirlo en bloques.
- Comparar DeepSeek V4 Flash y DeepSeek V4 Pro. La misma entrada puede ser barata en Flash y notablemente más costosa en Pro. La decisión debe combinar coste, calidad esperada y dificultad de la tarea.
El contador resulta más útil cuando trabajas con muestras reales. Un prompt de prueba de 200 palabras no representa una aplicación que envía historiales, datos de usuario y documentos adjuntos. Mide el caso completo, no solo la instrucción visible.
También conviene separar entrada y salida. Un clasificador puede generar una respuesta de pocos tokens. Un asistente que redacta informes largos puede gastar más en salida que en entrada. DeepSeek V4 Flash cobra $0,28 por 1M tokens de salida y DeepSeek V4 Pro cobra $3,48 por 1M tokens de salida.
Por qué la estimación se desvía a veces
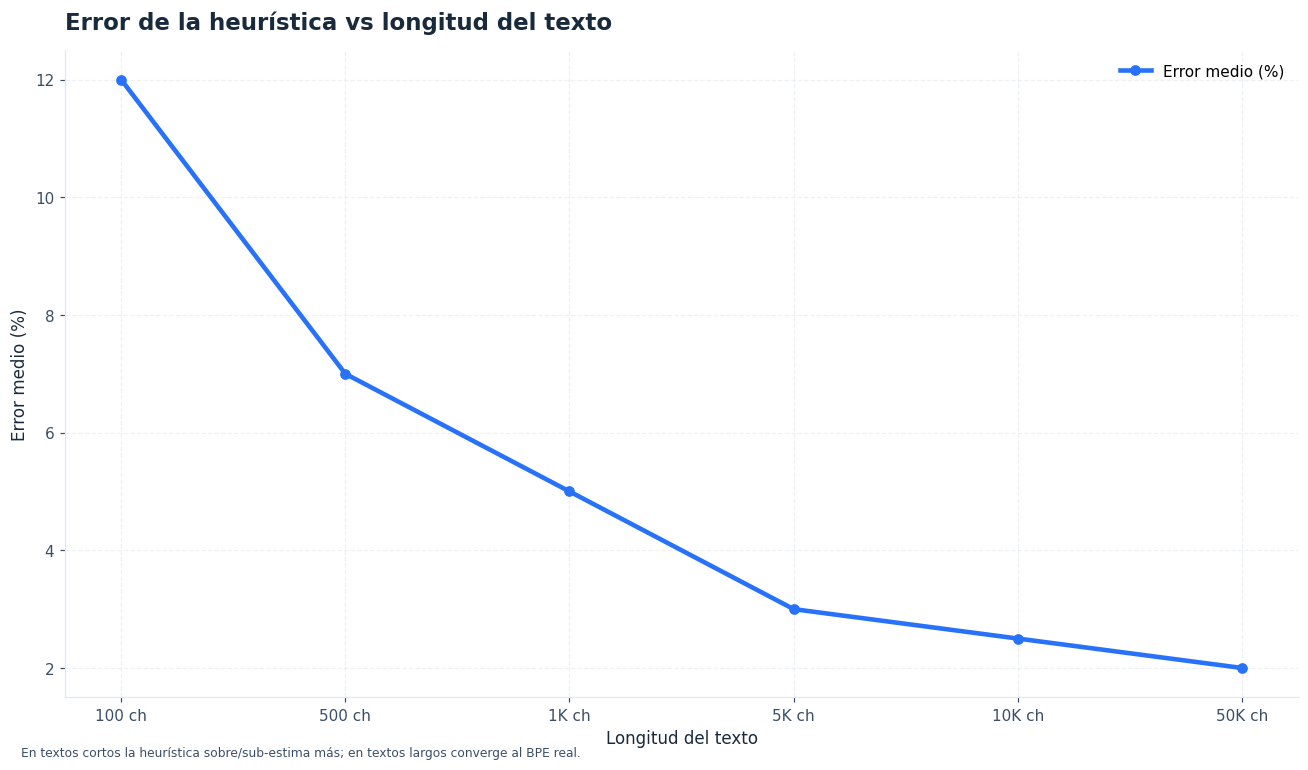
El contador usa una media calibrada para español, pero la tokenización real depende del texto exacto. La desviación suele ser pequeña en textos naturales, aunque puede crecer en contenido técnico, código o datos estructurados.
- Demasiados símbolos o código. JSON, expresiones regulares, HTML y fragmentos de programación suelen tokenizar peor que una frase natural. Si trabajas con API, mide ejemplos reales desde la documentación de la API y tus propios registros.
- Mezcla de idiomas. Un texto con español, inglés y nombres técnicos puede alejarse de la media de 3,7 caracteres por token. Ajusta con margen si la entrada contiene mucho inglés.
- Saltos de línea y formato. Tablas, listas, sangrías y separadores añaden caracteres que también cuentan. No los elimines del cálculo si estarán en la petición final.
- Emojis y caracteres especiales. Algunos símbolos pueden ocupar varios tokens. Si tu aplicación procesa redes sociales o chats, añade un margen de seguridad.
- Mensajes ocultos en la aplicación. El usuario ve una caja de texto, pero la petición puede incluir instrucciones, metadatos y contexto previo. Incluye todo el paquete para estimar bien.
- Caché no garantizada. El precio de caché solo aplica cuando DeepSeek puede reutilizar una parte repetida de la entrada. No presupuestes todo con caché si el contenido cambia en cada petición.
La forma más segura de trabajar es usar este contador como filtro inicial y validar después con métricas de uso reales en producción. Deja un margen cuando el coste de un flujo sea sensible o cuando el texto tenga estructura irregular.
Preguntas frecuentes
¿Un token equivale a una palabra?
No. Un token puede ser una palabra completa, un fragmento de palabra, un signo o una parte de un símbolo. En español, muchas palabras se dividen en más de un token, por eso el contador usa caracteres como base.
¿Por qué se usa 3,7 caracteres por token en español?
Es una heurística práctica para texto español general. Funciona mejor en párrafos naturales que en código, tablas o contenido con muchos símbolos. Para inglés, una referencia habitual es cercana a 4,0 caracteres por token.
¿El coste mostrado incluye la respuesta del modelo?
No. La herramienta calcula el coste de entrada. Si quieres estimar el coste total, añade los tokens de salida esperados y aplica la tarifa de salida: $0,28 por 1M tokens en DeepSeek V4 Flash y $3,48 en DeepSeek V4 Pro.
¿Sirve para DeepSeek V3.2?
Puede orientar el tamaño del texto, pero los precios de esta herramienta están centrados en DeepSeek V4. DeepSeek V3.2 queda como modelo heredado, con $0,28 por 1M tokens de entrada y $0,42 por 1M tokens de salida. Los alias deepseek-chat y deepseek-reasoner quedan obsoletos el 24 de julio de 2026.
¿Qué pasa si mi prompt supera el contexto disponible?
DeepSeek V4 Pro admite hasta 1M tokens de contexto y hasta 384K tokens de salida. Aun así, conviene no llenar el contexto sin criterio. Los textos muy largos aumentan coste, latencia y riesgo de incluir información irrelevante.
¿Puedo usar el contador para prompts con historial de chat?
Sí, siempre que pegues todo el historial que irá en la petición. Incluye mensajes del sistema, conversación anterior, instrucciones de formato y datos recuperados. Si solo pegas el último mensaje, la estimación será demasiado baja.
Recursos adicionales
- Inicio de deepseek-espanol.chat: acceso rápido a guías, modelos y herramientas sobre DeepSeek.
- Precios de DeepSeek: tabla de costes por modelo, entrada, salida y caché.
- Guía de la API de DeepSeek: parámetros, ejemplos de petición y buenas prácticas de integración.
- DeepSeek V4 Pro: contexto de 1M tokens, salida larga y casos de uso avanzados.
- DeepSeek V4 Flash: opción optimizada para volumen, latencia y coste bajo.
- Más herramientas para DeepSeek: utilidades para planificar prompts, costes y flujos con modelos de IA.
Conclusión
Un contador de tokens no necesita ser exacto al último token para ser útil. Su valor está en anticipar costes, detectar entradas demasiado grandes y comparar DeepSeek V4 Flash con DeepSeek V4 Pro antes de integrar la API. Pega muestras reales, incluye todo el contexto que enviarás y deja margen para salida, formato y caché. Si el flujo va a escalar, combina esta estimación con métricas reales de uso desde tus llamadas a producción.