
Hacer self host DeepSeek con DeepSeek V4 Flash significa ejecutar el modelo en tu propia infraestructura en lugar de depender solo de la API. Te interesa si buscas más control sobre datos, latencia predecible, integración local con tus flujos o una estructura de costes fija cuando el volumen ya es alto, pero conviene entender antes el hardware real, los runtimes disponibles y cuándo la API sigue siendo la opción más sensata.[1][2]
Resumen rápido
- DeepSeek V4 Flash tiene pesos abiertos con licencia MIT, así que puedes desplegarlo en infraestructura propia sin depender del servicio alojado de DeepSeek para la inferencia.[2]
- La API oficial sigue siendo muy barata para muchos casos: V4 Flash cuesta $0,14 por 1M tokens de entrada, $0,028 en entrada con cache hit, y $0,28 por 1M tokens de salida.[1]
- Si tu objetivo es self host DeepSeek, la limitación principal no es la licencia, sino la memoria de GPU, el ancho de banda entre GPU y el soporte real del runtime para modelos MoE grandes.
- Una sola GPU muy grande puede bastar para cuantizaciones agresivas y cargas experimentales. Para producción seria, lo habitual es usar varias GPU o un clúster pequeño.
- vLLM suele ser la primera opción para servicio API; TGI encaja bien si tu equipo ya trabaja con el ecosistema Hugging Face; llama.cpp tiene sentido en pruebas, cuantización extrema y entornos con recursos muy ajustados.
- Antes de comprar hardware, compara el coste fijo mensual de tus GPU con el coste variable de la API de DeepSeek. Muchas cargas medianas siguen saliendo mejor en API.[1]
Qué significa hacer self-hosting de DeepSeek V4 Flash
En esta guía, self host DeepSeek significa descargar los pesos abiertos de DeepSeek V4 Flash, cargar el modelo en un motor de inferencia y exponerlo como servicio interno o externo. Ese servicio puede vivir en un servidor local, en una máquina dedicada dentro de tu empresa o en una nube con GPU alquilada.[2]
El atractivo es claro. Tú decides dónde residen los datos, cómo se autentican las peticiones, qué políticas de registro aplicas y cómo integras el modelo con tus herramientas. También puedes fijar límites de uso por equipo, almacenar respuestas en caché a tu manera y ajustar el runtime a tu patrón de tráfico.
Ahora bien, “pesos abiertos” no equivale a “barato de operar”. DeepSeek V4 Flash es un modelo grande, con arquitectura orientada a eficiencia, pero sigue exigiendo memoria, planificación de lotes y una ruta de despliegue madura. La diferencia entre una demo que responde y un servicio estable con concurrencia es enorme.
También conviene separar dos cosas. La API compatible con OpenAI de DeepSeek usa la base https://api.deepseek.com/v1/ y permite acceder a V4 Flash y V4 Pro sin gestionar infraestructura propia.[1] El self-hosting, en cambio, te obliga a ocuparte de pesos, cuantización, paralelismo, monitorización y actualizaciones de runtime.
Requisitos reales de hardware: GPU única, varias GPU o clúster
La pregunta práctica no es si DeepSeek V4 Flash “puede” arrancar, sino con qué calidad de servicio. Según la nota oficial de lanzamiento, V4 Flash tiene 284B parámetros totales y 13B parámetros activos.[2] Esa cifra ayuda a entender por qué el modelo puede ser más eficiente que otros modelos densos, pero no elimina las exigencias de memoria para cargar pesos, tablas auxiliares y caché KV.
Como regla operativa, debes pensar en cuatro capas de coste técnico:
- memoria para los pesos del modelo;
- memoria adicional para caché KV en contextos largos;
- ancho de banda entre GPU, si repartes el modelo;
- CPU, RAM y almacenamiento local para cargar pesos y servir peticiones.
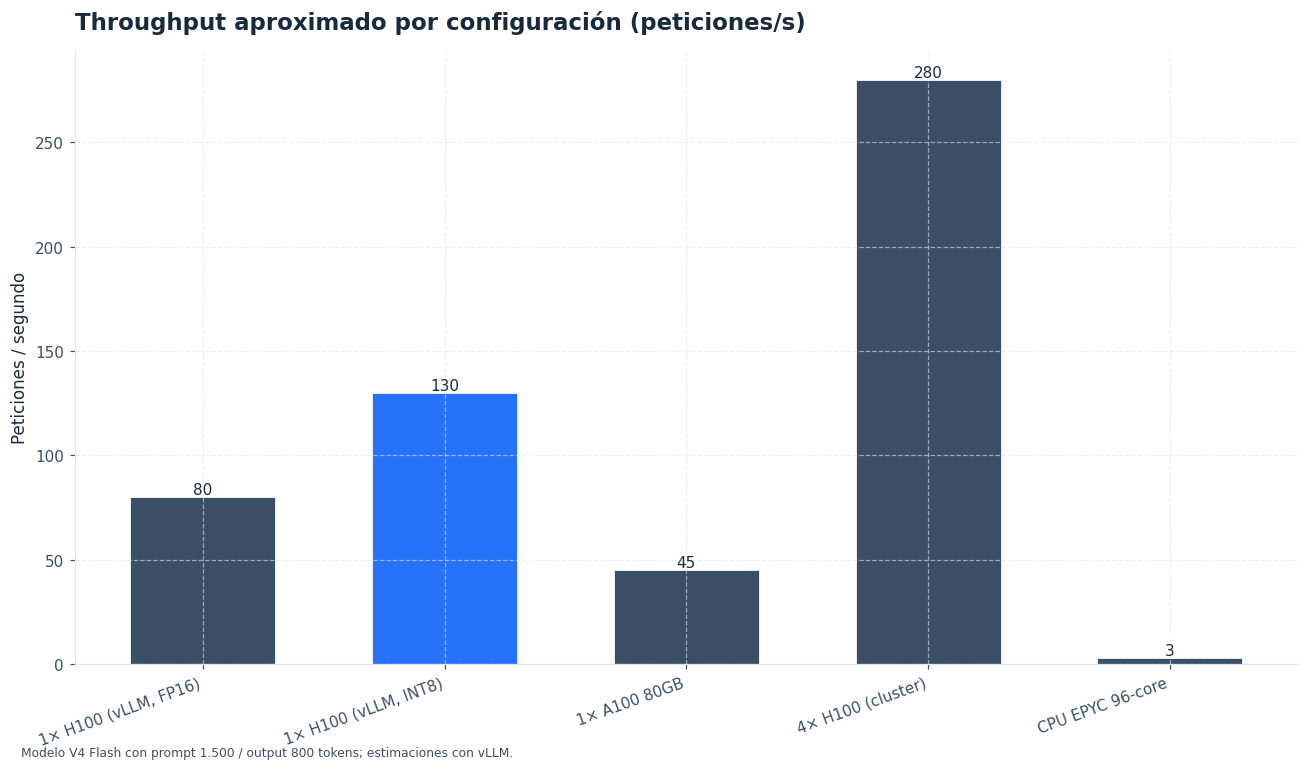
Para laboratorio o validación inicial, una sola GPU de gama alta puede servir si empleas cuantización fuerte y aceptas límites de contexto, baja concurrencia y cierta pérdida de calidad. Esta vía es útil para probar integración, no para sacar conclusiones de rendimiento final.
Si quieres un servicio interno estable, la opción más razonable suele ser una máquina de varias GPU con interconexión rápida. En ese escenario, puedes repartir el modelo, sostener lotes mayores y reducir los cuellos de botella que aparecen cuando la carga sube.
El clúster entra en juego cuando necesitas alguna de estas tres cosas: alta disponibilidad, mucha concurrencia o ventanas de contexto largas con usuarios simultáneos. Ahí ya no basta con “meter el modelo en memoria”. Necesitas equilibrado, réplicas, observabilidad y una política clara de autoescalado.
La guía útil es esta:
- GPU única: pruebas, integración local, prototipos y cuantizaciones agresivas.
- Servidor con varias GPU: la ruta habitual para un despliegue serio de V4 Flash.
- Clúster: producción con SLA, crecimiento horizontal y equipos con tráfico continuo.
Si tu caso de uso requiere 1M tokens de contexto, la presión sobre la caché KV cambia por completo el diseño. La documentación de DeepSeek indica 1M de contexto y un máximo de 384K tokens de salida para V4 Flash y V4 Pro.[1] En la práctica, debes validar con cuidado el contexto efectivo que podrás sostener en tu hardware, porque la teoría del modelo y la capacidad real de tu despliegue no siempre coinciden.
Configuración mínima sensata para empezar
Si estás evaluando self host DeepSeek por primera vez, no arranques por el escenario más ambicioso. Hazlo en tres fases:
- Prueba el modelo cuantizado con contexto corto y una sola sesión.
- Mide tokens por segundo, uso de VRAM y tiempo de carga.
- Solo después sube contexto, concurrencia y número de usuarios.
Este orden evita un error común: comprar GPU para un objetivo de contexto máximo cuando tu aplicación real solo usa entre 8K y 64K tokens por turno.
Runtimes recomendados: vLLM, TGI y llama.cpp
No hay un único motor correcto. La elección depende de si priorizas compatibilidad, rendimiento, facilidad operativa o flexibilidad de cuantización.
vLLM
vLLM suele ser la primera opción cuando quieres exponer un endpoint estilo OpenAI y aprovechar lotes continuos, buena utilización de GPU y una experiencia de servicio bastante madura. Encaja especialmente bien si tu objetivo es sustituir o complementar una API alojada con una API interna similar.
Ventajas principales:
- buen rendimiento en serving;
- ecosistema amplio;
- integración sencilla con clientes existentes;
- mejor punto de partida para cargas multiusuario.
Inconveniente: la compatibilidad exacta con arquitecturas nuevas y cuantizaciones concretas depende de la versión del proyecto y de su soporte efectivo en el momento del despliegue. Antes de cerrar arquitectura, valida el modelo exacto y el formato de pesos que vas a utilizar.
Text Generation Inference (TGI)
TGI tiene sentido si tu equipo ya trabaja con Hugging Face, contenedores listos para producción y flujos más estándar de serving. Es una opción sólida cuando quieres observabilidad razonable, despliegue repetible y alineación con el ecosistema de modelos abiertos.
Encaja bien en organizaciones que ya tienen:
- registro de contenedores;
- Kubernetes o una plataforma equivalente;
- métricas centralizadas;
- procesos formales de despliegue.
llama.cpp
llama.cpp destaca cuando buscas portabilidad, ejecución local y cuantizaciones muy agresivas. Para V4 Flash, su papel natural es exploratorio: verificar que un flujo cabe en cierto hardware, ensayar GGUF o montar una demo local rápida. También puede servir en entornos mixtos CPU+GPU donde otros runtimes resultan demasiado pesados.
Su límite aparece cuando pides concurrencia, contexto grande y estabilidad de producción. Ahí suele quedarse por detrás de vLLM o TGI.
Comparativa rápida
| Runtime | Mejor uso | Punto fuerte | Límite habitual |
|---|---|---|---|
| vLLM | API interna o externa | Serving eficiente y familiar | Depende del soporte del modelo exacto |
| TGI | Equipos con stack Hugging Face | Operación reproducible | Menos flexible en algunos escenarios |
| llama.cpp | Pruebas locales y cuantización extrema | Ligereza y portabilidad | Peor encaje para producción exigente |
Cuantización: cuándo compensa y qué sacrificas
La cuantización reduce el tamaño efectivo del modelo y facilita el despliegue en menos VRAM. Es la palanca principal para hacer viable el self host DeepSeek sin una infraestructura desproporcionada. A cambio, puedes perder precisión, estabilidad en tareas complejas y parte del rendimiento en razonamiento o generación larga.
La decisión no debería ser ideológica. Hazla por caso de uso:
- Chat general y asistencia interna: una cuantización moderada suele ser aceptable.
- Código, herramientas y agentes: conviene ser más conservador.
- Razonamiento largo o salida extensa: cuantizar demasiado puede degradar más de lo esperado.
También influye el modo de razonamiento. La documentación de DeepSeek indica que V4 Flash soporta modo con razonamiento y sin razonamiento, con el modo de razonamiento activado por defecto.[1][3] Si en tu despliegue piensas mantener ese comportamiento, prueba la cuantización bajo esa carga real, no solo en respuestas cortas sin herramientas.
Una estrategia prudente es mantener dos perfiles:
- un perfil cuantizado para desarrollo, pruebas de producto y baja prioridad;
- un perfil menos cuantizado, o incluso de mayor calidad, para producción y evaluación final.
Eso te permite ahorrar durante la fase de iteración sin tomar decisiones permanentes sobre calidad antes de medir.
Despliegue paso a paso: de laboratorio a servicio interno
Si quieres pasar de cero a un despliegue útil, esta secuencia evita la mayoría de problemas iniciales.
- Define el objetivo. No es lo mismo servir 10 usuarios internos que montar una API multiinquilino.
- Elige formato de pesos y runtime. Prioriza compatibilidad real sobre preferencias del equipo.
- Empieza con contexto corto. Valida calidad y estabilidad antes de intentar 1M tokens.
- Activa métricas desde el primer día. Necesitas ver VRAM, tokens por segundo, cola y errores.
- Introduce autenticación y límites. Un servicio interno sin cuotas se satura antes de lo que parece.
- Haz pruebas con carga. Una demo de usuario único no predice producción.
Muchos equipos combinan self-hosting para cargas estables y la API de DeepSeek V4 Flash como respaldo para picos, fallos o experimentos rápidos. Ese enfoque híbrido reduce riesgo y evita sobreaprovisionar hardware.
Si ya trabajas con la API oficial y quieres mantener compatibilidad con clientes existentes, este ejemplo cURL te sirve como referencia de interfaz. DeepSeek documenta una API compatible con OpenAI y base URL https://api.deepseek.com, además de soporte para los modelos deepseek-v4-flash y deepseek-v4-pro.[1][4]
curl https://api.deepseek.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{"role": "system", "content": "Eres un asistente técnico."},
{"role": "user", "content": "Resume las ventajas de desplegar un modelo en infraestructura propia."}
],
"temperature": 0,3,
"max_tokens": 512
}'Si reproduces esta interfaz delante de tu servidor propio, podrás cambiar entre API oficial y despliegue interno con menos fricción en el cliente.
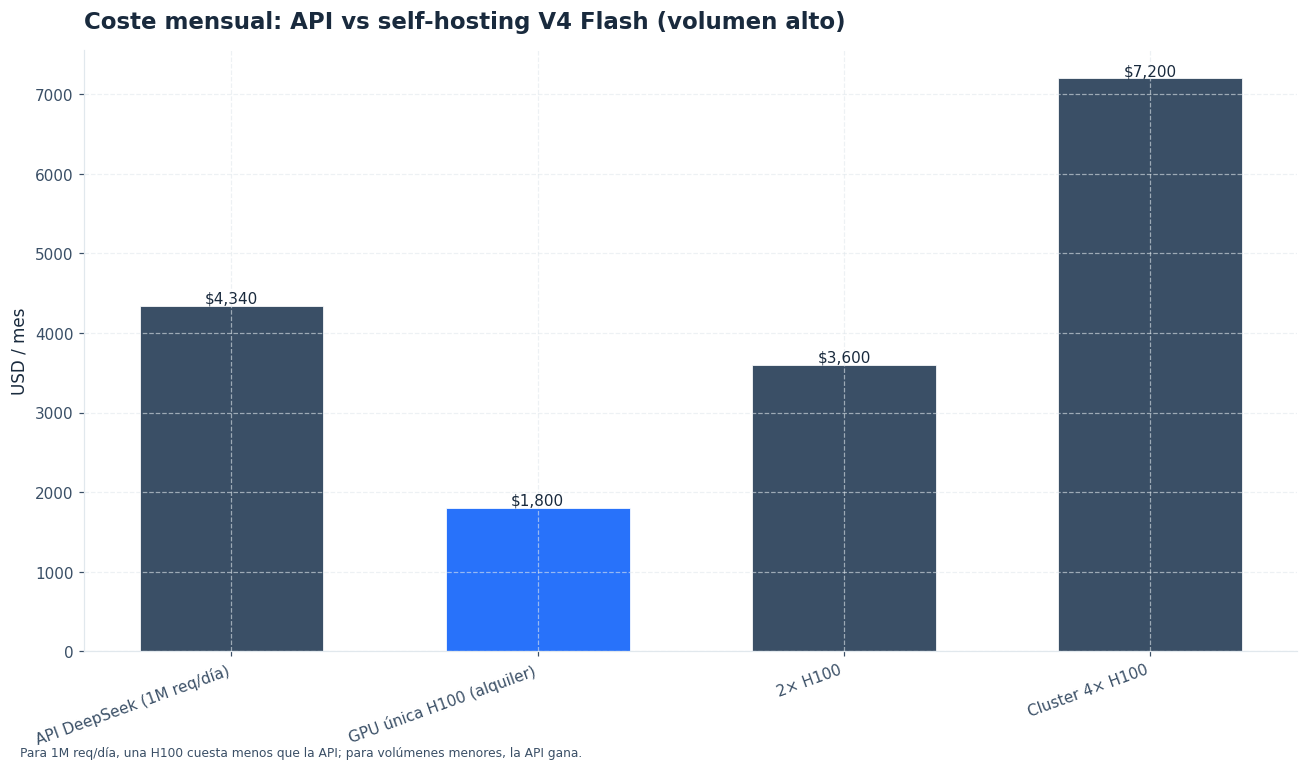
Coste: cuándo sale mejor self-hosting y cuándo gana la API
Aquí se decide casi todo. La API oficial de DeepSeek V4 Flash cuesta $0,14 por 1M tokens de entrada, $0,028 con cache hit en entrada y $0,28 por 1M tokens de salida.[1] V4 Pro cuesta $1,74 por 1M tokens de entrada, $0,145 en entrada con cache hit y $3,48 por 1M tokens de salida.[1] DeepSeek V3.2 figura como modelo legacy con $0,28 de entrada y $0,42 de salida; además, los alias deepseek-chat y deepseek-reasoner se retirarán el 24 de julio de 2026.[1][5]
Las tarifas pueden cambiar; verifica los importes vigentes en la página de planes y precios antes de presupuestar una integración.
Con esos precios, la API es difícil de batir si tu uso todavía es irregular, si no tienes equipo de plataforma o si tu tráfico depende de campañas y picos. Pagas solo por uso, te beneficias de la caché de contexto de DeepSeek y no asumes inmovilizado en hardware.[1][6]
El self-hosting empieza a ganar en tres escenarios:
- consumo alto y estable durante muchas horas al día;
- requisitos estrictos de residencia o aislamiento de datos;
- necesidad de personalizar el plano de serving y la integración interna.
Pero no compares solo “precio por token” frente a “precio por GPU”. Incluye:
- instancias o compra de hardware;
- energía y refrigeración, si aplica;
- tiempo del equipo para operación;
- monitorización, copias, seguridad y red;
- capacidad ociosa en horas valle.
En términos prácticos, la decisión suele quedar así:
- API: mejor para empezar, iterar rápido y absorber variabilidad.
- Self-hosting: mejor cuando ya conoces tu carga y puedes amortizar infraestructura.
- Híbrido: mejor para equipos que quieren control sin renunciar a elasticidad.
Preguntas frecuentes
¿DeepSeek V4 Flash permite uso comercial en self-hosting?
La nota oficial de lanzamiento indica pesos abiertos con licencia MIT para DeepSeek V4.[2] Esa licencia es muy permisiva. Aun así, antes de un despliegue comercial conviene revisar el repositorio y los archivos de licencia del artefacto exacto que vayas a descargar.
¿Puedo usar una sola GPU para DeepSeek V4 Flash?
Sí, para pruebas o con cuantización agresiva puede ser viable. La cuestión no es solo arrancar el modelo, sino sostener contexto, concurrencia y calidad. Para producción, lo habitual es necesitar varias GPU o una arquitectura distribuida.
¿Qué runtime debería elegir primero?
Si quieres una API interna parecida a OpenAI, empieza por vLLM. Si tu equipo ya opera con Hugging Face y contenedores estándar, TGI es una opción natural. Si buscas una prueba local rápida o cuantización muy agresiva, llama.cpp puede servir mejor.
¿Tiene sentido hacer self-hosting si la API es tan barata?
Depende de tu volumen y de tus requisitos de control. Con los precios actuales de V4 Flash, muchos equipos pequeños y medianos seguirán mejor con la API.[1] El self-hosting suele compensar cuando la carga es constante o cuando el cumplimiento interno pesa más que el coste puro.
¿Debo seguir usando deepseek-chat o deepseek-reasoner?
No como apuesta a medio plazo. DeepSeek ha comunicado que ambos alias se retirarán el 24 de julio de 2026 y que, durante la transición, apuntan a DeepSeek V4 Flash en modo sin razonamiento y con razonamiento, respectivamente.[1][5]
Recursos relacionados
- DeepSeek en español
- precios de DeepSeek
- documentación de la API
- probar DeepSeek Chat
- guía de DeepSeek V4 Pro
- ficha de DeepSeek V4 Flash
Conclusión
Hacer self host DeepSeek con DeepSeek V4 Flash es viable y atractivo cuando necesitas control operativo, aislamiento de datos o costes más predecibles a gran escala. La clave no está en la licencia, sino en elegir bien el runtime, la cuantización y el nivel de hardware que tu carga realmente exige. Si aún estás validando producto, la API oficial suele ser el mejor punto de partida. Si ya conoces tu volumen y tus restricciones, empieza con un piloto medido, compara contra la API y decide con números, no por intuición.[1][2]