
Analizar un repositorio completo con IA ya no obliga a partir el proyecto en decenas de consultas ni a perder contexto entre archivos. Con DeepSeek V4 Flash y DeepSeek V4 Pro puedes trabajar con hasta 1 M tokens de contexto, usar modos con o sin razonamiento y revisar una codebase grande con una sola estrategia de análisis o con un flujo híbrido más barato y controlable.[1][2]
Resumen rápido
- DeepSeek V4 Flash y DeepSeek V4 Pro admiten 1 M tokens de contexto, con salida máxima de 384 K tokens, lo que permite revisar repositorios mucho más grandes sin perder relaciones entre módulos.[1]
- Para analizar codebase IA no siempre conviene enviar todo el repositorio. En proyectos medianos funciona bien el contexto completo; en proyectos grandes suele rendir mejor un enfoque híbrido con prefiltrado y recuperación selectiva.
- DeepSeek V4 Flash cuesta $0,14 por 1 M tokens de entrada y $0,28 por 1 M tokens de salida; DeepSeek V4 Pro sube a $1,74 y $3,48 respectivamente. En entradas en caché, el precio baja a $0,028 en Flash y $0,145 en Pro.[1]
- Los alias
deepseek-chatydeepseek-reasonerquedan discontinuados el 24 de julio de 2026. Para trabajo nuevo conviene usardeepseek-v4-flashodeepseek-v4-pro.[2] - La API mantiene formato compatible con OpenAI en
https://api.deepseek.com/v1/, así que puedes reutilizar gran parte de tu cliente actual con cambios mínimos.[3] - La mejor combinación coste-tiempo suele ser: inventario del repositorio, compactación inteligente, una pasada amplia con Flash y una segunda pasada focalizada con Pro en las zonas críticas.
Qué cambia al analizar repositorios con 1 M tokens
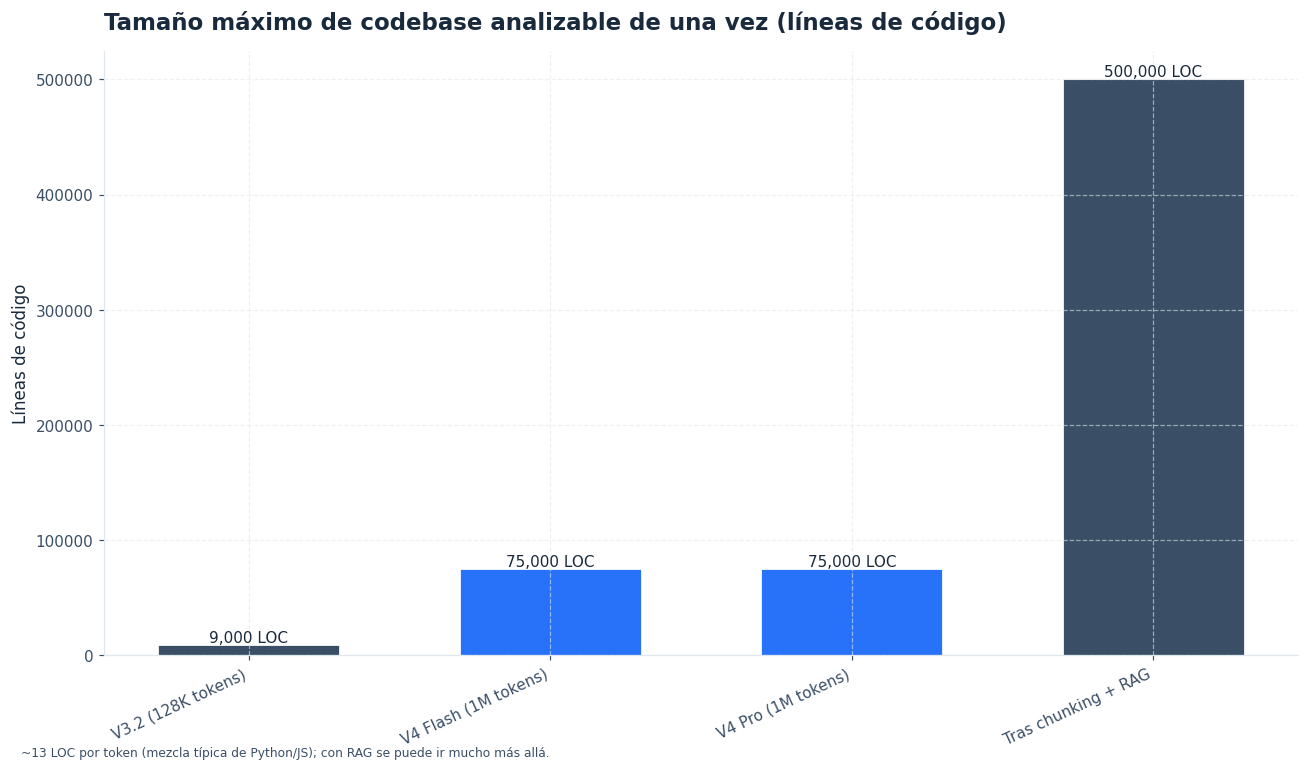
La diferencia práctica no está solo en “meter más texto”. El cambio real aparece cuando el modelo puede ver arquitectura, convenciones, dependencias internas y puntos de acoplamiento en la misma conversación. En una revisión tradicional con ventanas pequeñas, cada prompt fuerza resúmenes intermedios y esos resúmenes degradan precisión. Con 1 M tokens, DeepSeek V4 reduce esa pérdida porque puede mantener a la vista más código, documentación, pruebas, configs y mensajes de error en una única sesión.[1]
Esto resulta útil en varios escenarios: auditorías de deuda técnica, migraciones de framework, revisión previa a una integración, análisis de seguridad orientado a patrones y comprensión de proyectos heredados. También encaja bien cuando el repositorio mezcla varios lenguajes o cuando la lógica crítica no está concentrada en un único servicio.
Ahora bien, contexto amplio no significa enviar el árbol completo sin criterio. Archivos generados, dependencias vendorizadas, binarios, lockfiles enormes y artefactos de compilación consumen presupuesto y distraen al modelo. La calidad del análisis depende más de la selección y de la estructura del contexto que del volumen bruto.
Si quieres revisar modelos y capacidades antes de montar el flujo, conviene consultar la página de DeepSeek V4 Flash, la ficha de DeepSeek V4 Pro y la sección de precios de la API. Para integración directa, la referencia útil está en la documentación de API.
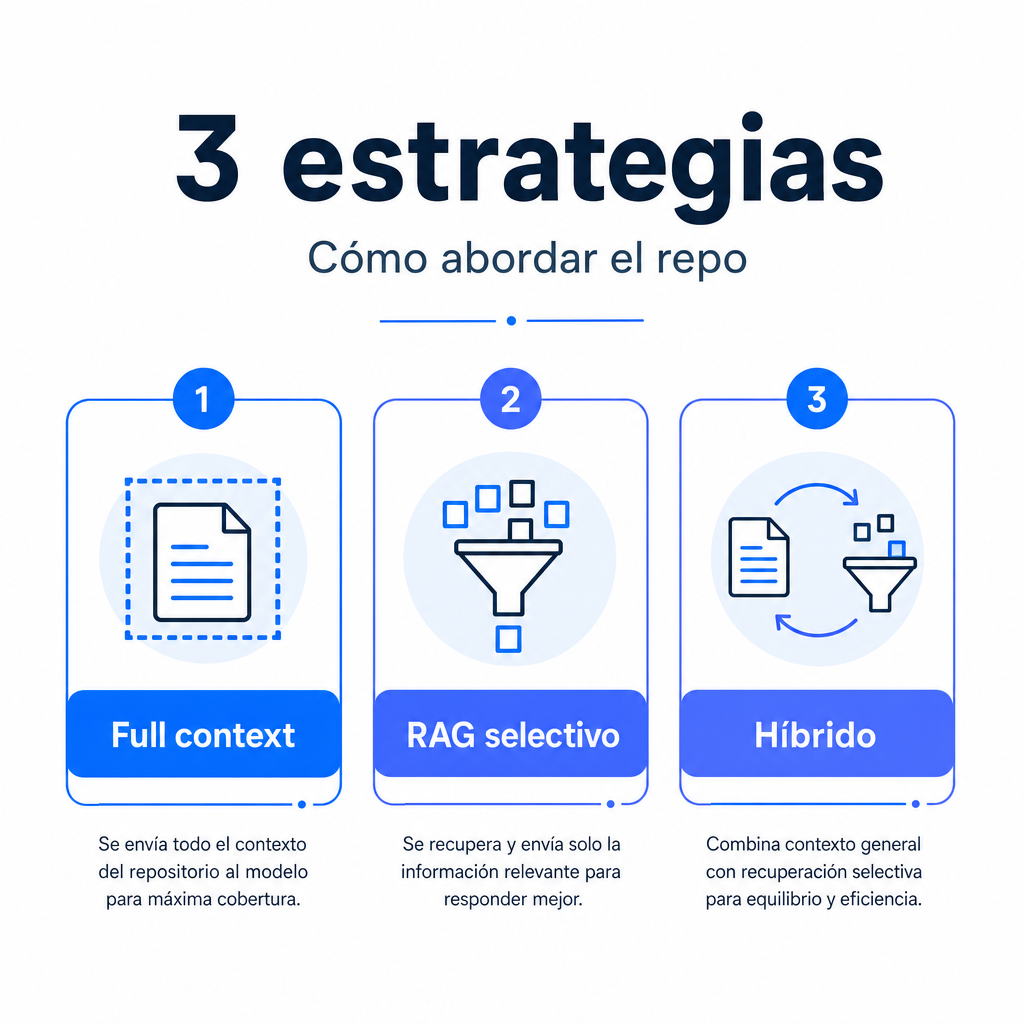
Cuándo usar contexto completo y cuándo usar RAG
La decisión clave al analizar codebase IA es esta: ¿envías el repositorio entero o construyes un sistema de recuperación? No hay una única respuesta correcta. Depende del tamaño del proyecto, del tipo de pregunta y del coste aceptable por iteración.
Opción 1: contexto completo
Funciona mejor cuando el repositorio cabe de forma razonable dentro de la ventana útil, la pregunta exige relaciones amplias y el coste por consulta sigue siendo asumible. Ejemplos: “explica la arquitectura”, “detecta capas mal separadas”, “localiza duplicidad de lógica de autenticación” o “prepara un plan de migración a colas asíncronas”.
- Ventaja: máxima coherencia entre archivos.
- Ventaja: menos complejidad operativa.
- Ventaja: mejor para preguntas abiertas o exploratorias.
- Inconveniente: más coste por llamada.
- Inconveniente: si el contexto entra desordenado, el modelo pierde tiempo en ruido.
Opción 2: RAG o recuperación selectiva
Encaja mejor en repositorios muy grandes, monolitos con años de historia o preguntas muy concretas, como “¿qué rutas llaman a este servicio?” o “¿dónde se valida este permiso antes de persistir?”. En este enfoque, primero indexas archivos o fragmentos y luego recuperas solo lo relevante para cada consulta.
- Ventaja: reduce tokens y coste.
- Ventaja: acelera iteraciones repetidas.
- Ventaja: escala mejor en repositorios gigantes.
- Inconveniente: si la recuperación falla, el análisis sale incompleto.
- Inconveniente: añade una capa extra de ingeniería.
La opción más útil en la práctica: híbrido
En equipos técnicos suele rendir mejor un enfoque híbrido. La primera pasada emplea DeepSeek V4 Flash para construir un mapa del repositorio, resumir carpetas, detectar puntos críticos y priorizar zonas. La segunda pasada usa recuperación selectiva o contexto ampliado sobre los archivos relevantes. Si hay una decisión delicada, una tercera llamada con DeepSeek V4 Pro puede revisar solo los módulos críticos con razonamiento más intenso.[1][4]
Esa secuencia reduce coste sin renunciar a visión global. Además, al repetir análisis sobre la misma base común puedes beneficiarte del precio de entrada en caché, que es mucho menor que el de una entrada sin caché.[1]
Flujo recomendado paso a paso para analizar una codebase
El siguiente proceso sirve tanto para una revisión puntual como para un asistente interno de ingeniería.
- Haz un inventario del repositorio. Extrae árbol de directorios, número de archivos, lenguajes, tamaño por carpeta, dependencias principales y archivos de documentación.
- Excluye ruido. Elimina
node_modules,dist,build, binarios, imágenes pesadas, artefactos generados, vendored code y ficheros que no aporten lógica. - Agrupa por unidades semánticas. No hagas chunking fijo por tokens si puedes evitarlo. Agrupa por módulo, servicio, paquete o dominio funcional.
- Antepón un manifiesto. Antes del código, envía un resumen con estructura del proyecto, objetivos del análisis y reglas para citar archivos concretos en la respuesta.
- Define una tarea cerrada. Pide al modelo un tipo de salida concreto: mapa arquitectónico, riesgos, deuda técnica, plan de refactor, hallazgos de seguridad o lista priorizada de incidencias.
- Haz una segunda pasada focalizada. Toma los puntos dudosos y vuelve a consultar solo con el subconjunto relevante.
- Valida con pruebas y búsqueda local. El modelo puede orientar muy bien, pero no sustituye una comprobación real con tests, grep, análisis estático o ejecución.
En repositorios pequeños o medianos, los pasos 1 a 5 pueden resolverse en una sola llamada. En repositorios grandes, conviene separarlos. La regla práctica es sencilla: si la pregunta depende de relaciones globales, amplía contexto; si depende de un camino de ejecución concreto, estrecha el contexto y sube la precisión del prompt.
Plantilla de prompt útil
Una plantilla eficaz suele incluir estas piezas:
- objetivo del análisis;
- perfil del repositorio;
- criterios de calidad;
- formato de salida;
- obligación de citar archivo y función cuando haga una afirmación;
- lista de dudas abiertas al final.
Ejemplo de instrucción base:
Analiza esta codebase como si fueras un arquitecto de software. Identifica módulos, dependencias, rutas críticas de negocio, duplicidades, riesgos de mantenimiento y posibles errores de diseño. Para cada hallazgo, cita archivo, símbolo y motivo técnico. Si falta contexto, indícalo de forma explícita.
Ejemplo cURL con API compatible con OpenAI
curl https://api.deepseek.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{
"role": "system",
"content": "Eres un analista de arquitectura de software. Responde con hallazgos priorizados y cita archivos."
},
{
"role": "user",
"content": "Voy a pegar un manifiesto del repositorio y varios archivos clave. Quiero un mapa de módulos, riesgos, dependencias cíclicas y sugerencias de refactor."
}
],
"temperature": 0.2,
"max_tokens": 12000,
"extra_body": {
"thinking": { "type": "enabled" }
}
}'Si necesitas más profundidad en una zona concreta, cambia el modelo a deepseek-v4-pro y ajusta el esfuerzo de razonamiento cuando la tarea lo justifique. La guía oficial documenta el modo de razonamiento, con control de thinking y reasoning_effort; en V4 Pro el esfuerzo puede llegar a max.[4]
Chunking inteligente: cómo partir el repositorio sin romper el sentido
El error más común al analizar codebase IA es cortar por longitud fija, como si todo archivo fuese equivalente. Ese método mezcla piezas sin relación y separa funciones que deberían leerse juntas. Un chunking mejor sigue la semántica del proyecto.
- Por dominio: facturación, autenticación, catálogo, notificaciones.
- Por servicio: API pública, workers, tareas programadas, panel interno.
- Por capa: rutas, controladores, servicios, repositorios, modelos, pruebas.
- Por flujo: entrada HTTP, validación, lógica de negocio, persistencia, salida.
- Por artefacto técnico: configuración, migraciones, schemas, contratos, observabilidad.
También conviene preparar un manifiesto por fragmento. Cada bloque debería empezar con una pequeña cabecera: ruta, propósito, dependencias clave, símbolos exportados y relación con otros módulos. Esa cabecera mejora mucho la recuperación posterior y ayuda al modelo a no interpretar un archivo aislado como si fuese autónomo.
Otra práctica útil es conservar siempre tres niveles de contexto: el global del proyecto, el del módulo y el del archivo. Cuando el modelo responde, puedes pedirle que distinga entre hallazgos “sistémicos” y hallazgos “locales”. Eso evita que una mala práctica puntual se convierta en una conclusión exagerada sobre toda la arquitectura.
Ejemplo trabajado: revisión de un monolito SaaS
Imagina un monolito SaaS con backend en Python, panel administrativo en TypeScript, colas para tareas y unas 8.000-10.000 líneas relevantes tras excluir ruido. El objetivo es detectar deuda técnica antes de dividir el sistema en servicios.
- Se genera un árbol del proyecto y un resumen de dependencias.
- Se eliminan migraciones antiguas, binarios, carpetas de compilación y pruebas duplicadas.
- Se preparan bloques por dominio: cuentas, facturación, permisos, correo y auditoría.
- Se lanza una primera llamada con DeepSeek V4 Flash para obtener mapa arquitectónico y lista de riesgos.
- La respuesta señala tres zonas: permisos mezclados con lógica de facturación, validación inconsistente entre API y tareas asíncronas, y acceso directo a base de datos desde código de presentación.
- Se hace una segunda llamada solo con los módulos de permisos y facturación, esta vez con DeepSeek V4 Pro, para pedir propuesta de refactor por fases y riesgo de regresión.
El resultado útil no es solo “qué está mal”, sino una secuencia de trabajo: extraer política de permisos, centralizar validaciones, introducir una capa de servicios para facturación y cubrir rutas críticas con pruebas de integración antes de mover piezas. Ese tipo de salida ahorra varias horas de lectura inicial y da un mapa que luego el equipo puede validar con revisión humana.
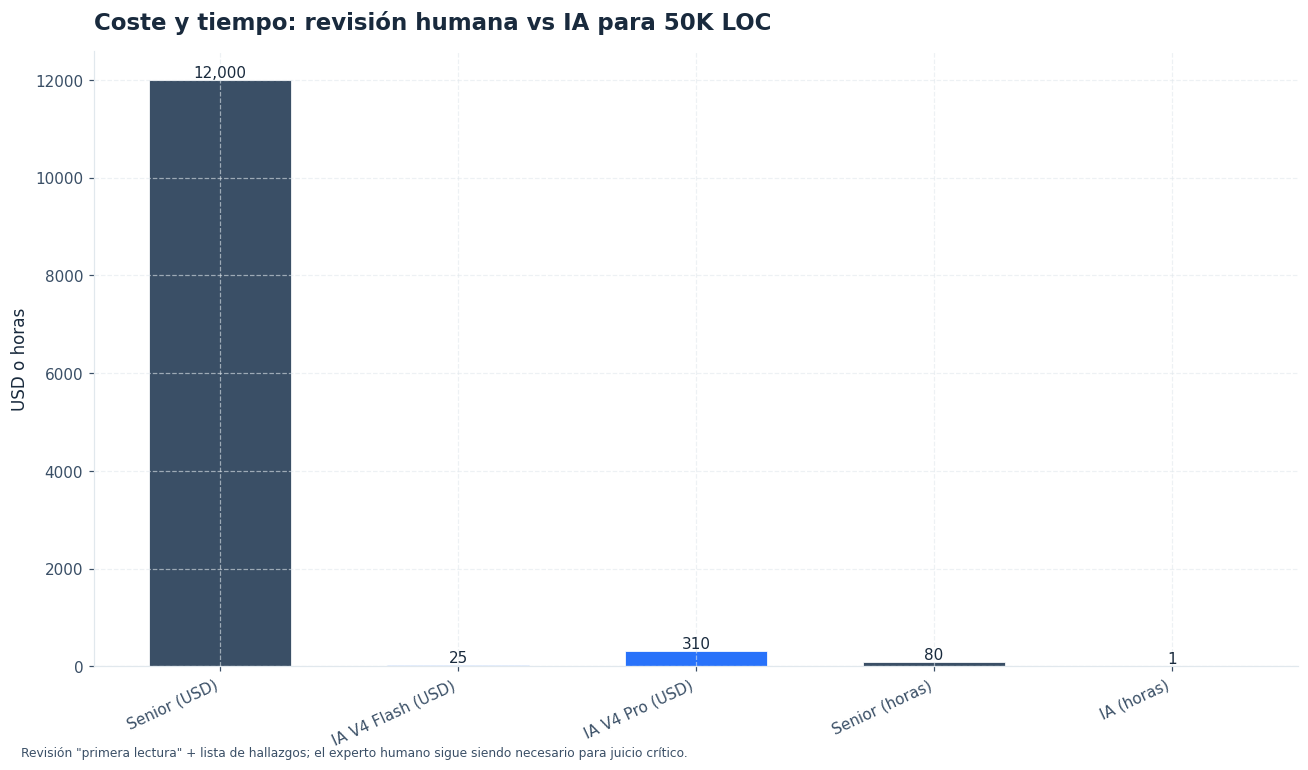
Coste y tiempo frente a revisión manual
La comparación justa no consiste en medir si la IA sustituye una revisión senior. La comparación útil es otra: cuánto reduce el tiempo de arranque, de exploración y de priorización. Un modelo puede recorrer miles de líneas y devolver un mapa inicial en minutos. Una persona sigue siendo necesaria para validar impacto, riesgo real y plan de ejecución.
| Enfoque | Velocidad inicial | Coste directo | Profundidad | Riesgo principal |
|---|---|---|---|---|
| Revisión humana completa | Baja | Alto en horas | Muy alta | Tiempo de arranque |
| DeepSeek V4 Flash | Muy alta | Bajo | Alta para exploración | Conclusiones sin validar |
| DeepSeek V4 Pro | Alta | Medio | Muy alta en zonas críticas | Usarlo donde Flash ya bastaba |
| Flujo híbrido Flash + Pro + validación humana | Alta | Optimizado | Muy alta | Diseño pobre del flujo |
En precios de API, DeepSeek V4 Flash marca $0,14 por 1 M tokens de entrada, $0,28 por 1 M tokens de salida y $0,028 por 1 M tokens de entrada en caché. DeepSeek V4 Pro sube a $1,74, $3,48 y $0,145 respectivamente.[1] Con esos niveles, Flash encaja bien como motor de exploración y Pro como capa de verificación o diseño en módulos de alto impacto.
Las tarifas pueden cambiar; verifica los importes vigentes en la página de planes y precios antes de presupuestar una integración.
Frente a eso, DeepSeek V3.2 mantiene precios de $0,28 por 1 M tokens de entrada, $0,42 de salida y contexto de 128 K, pero los alias heredados deepseek-chat y deepseek-reasoner se discontinuarán el 24 de julio de 2026, así que no tiene sentido construir un flujo nuevo sobre ellos.[1][2]
Una estimación sencilla ayuda a decidir. Si una primera pasada consume 300.000 tokens de entrada y 20.000 de salida, Flash sale muy barato para una auditoría inicial. Si luego haces dos pasadas focalizadas con Pro sobre módulos críticos, el coste total sigue siendo bajo frente a varias horas de lectura manual de una persona senior. No sustituye esa revisión, pero sí reduce el tiempo necesario para empezar bien.
Además, DeepSeek publica pesos abiertos para la familia V4 bajo licencia MIT, lo que refuerza su interés en flujos técnicos donde conviene combinar API, despliegues internos y experimentación propia.[5]
Preguntas frecuentes
¿Qué modelo conviene para empezar a analizar un repositorio?
Para exploración inicial, DeepSeek V4 Flash suele ser la opción más rentable. Da contexto de 1 M tokens y un coste muy bajo por entrada y salida. Si detectas una parte crítica o una decisión arquitectónica delicada, puedes escalar después a DeepSeek V4 Pro.[1]
¿Hace falta enviar toda la codebase en un solo prompt?
No. De hecho, muchas veces no conviene. Si el repositorio es grande, mezcla varios productos o contiene mucho código generado, es mejor enviar un manifiesto global y después módulos priorizados. El contexto amplio ayuda, pero la selección sigue siendo decisiva.
¿DeepSeek V4 Pro siempre analiza mejor que Flash?
No siempre. Pro tiene más sentido cuando la tarea exige razonamiento más profundo, revisión de compromisos técnicos o síntesis compleja entre partes conflictivas. Para inventario, clasificación, mapa de módulos y detección inicial de puntos sospechosos, Flash suele bastar y cuesta mucho menos.[1][4]
¿Puedo reutilizar un cliente pensado para OpenAI?
Sí. DeepSeek documenta una API compatible con formato OpenAI y mantiene el punto de acceso en https://api.deepseek.com/v1/. Eso reduce bastante el trabajo de integración en herramientas internas y asistentes de desarrollo.[3]
¿Qué pasa con deepseek-chat y deepseek-reasoner?
Siguen existiendo por compatibilidad, pero DeepSeek ha indicado que esos nombres heredados se discontinuarán el 24 de julio de 2026. Para un proyecto nuevo conviene migrar desde el principio a deepseek-v4-flash o deepseek-v4-pro.[2]
¿La IA reemplaza la revisión de código humana?
No. La IA acelera la comprensión, prioriza hallazgos y propone hipótesis útiles. La validación final sigue dependiendo de pruebas, observabilidad, revisión por pares y conocimiento del dominio. El valor real está en reducir tiempo de arranque y en aumentar cobertura mental del repositorio.
Recursos relacionados
- Inicio de DeepSeek Español
- precios actualizados de la API
- guía de integración de la API
- probar DeepSeek en el chat
- ficha técnica de DeepSeek V4 Flash
- capacidades de DeepSeek V4 Pro
Conclusión
Si tu objetivo es analizar codebase IA con rapidez y sin perder visión global, DeepSeek V4 abre una opción muy práctica: usar 1 M tokens para entender el repositorio, no solo para resumir archivos sueltos. La estrategia más sólida no consiste en volcar todo el código sin filtro, sino en combinar inventario, chunking semántico, una primera pasada barata con Flash y una revisión focalizada con Pro. Si montas ese flujo desde el principio, obtendrás análisis más coherentes, coste controlado y un punto de partida mucho mejor para la revisión humana.