
El contexto largo DeepSeek en V4 cambia el tipo de tareas que puedes ejecutar con un solo prompt: ya no hablamos solo de preguntas cortas, sino de repositorios completos, lotes grandes de documentos y sesiones prolongadas con memoria operativa. Con una ventana de contexto de 1M tokens y hasta 384K tokens de salida en V4, la clave no es solo “meter más texto”, sino decidir qué entra, en qué orden y con qué estrategia para que el modelo responda mejor y gaste menos.[1][2]
Resumen rápido
- DeepSeek V4 Flash y DeepSeek V4 Pro admiten 1M tokens de contexto; V4 también permite hasta 384K tokens de salida en la API.[1]
- Una ventana grande no garantiza atención uniforme. El rendimiento depende de cómo segmentas, priorizas y reutilizas el contexto.[1][3]
- El contexto largo DeepSeek encaja muy bien en revisión de bases de código, análisis documental y sesiones de trabajo largas, pero no sustituye una buena recuperación de información.
- V4 Flash es la opción de coste/velocidad para cargas amplias; V4 Pro compensa cuando necesitas más calidad, razonamiento más intenso y modo thinking-max.[1][4]
- El caché de contexto importa mucho con entradas repetidas: reduce el coste de entrada a $0,028 por 1M tokens en V4 Flash y a $0,145 en V4 Pro.[1]
- Los alias
deepseek-chatydeepseek-reasonersiguen activos por compatibilidad, pero se deprecarán el 24 de julio de 2026.[2]
Qué significa de verdad una ventana de 1M tokens
Una ventana de contexto de 1.000.000 tokens define cuánto material puede leer el modelo en una sola solicitud, contando instrucciones, historial, herramientas, documentos adjuntos y fragmentos recuperados. No significa que cada token reciba la misma atención ni que el modelo “recuerde” todo con la misma precisión. Significa que ese material cabe en la conversación activa y puede influir en la respuesta.[1]
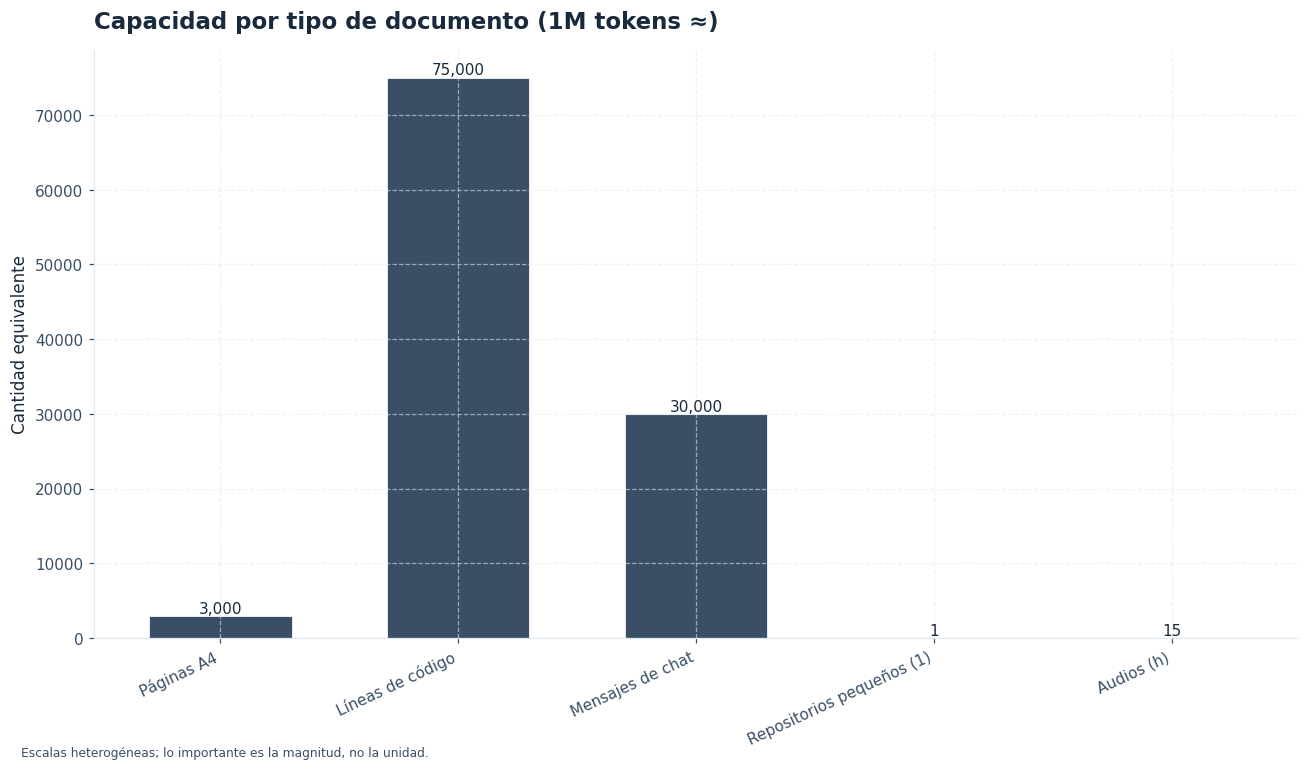
En la práctica, 1M tokens equivale a una cantidad muy grande de texto: varias bases de documentación, contratos extensos, transcripciones largas o una parte sustancial de un repositorio. Aun así, el límite útil no es solo el máximo técnico. También mandan la calidad del orden, la redundancia, el ruido y la distancia entre la información importante y la pregunta final.
Aquí aparece una distinción útil: ventana real frente a atención efectiva. La ventana real es el límite publicado por el proveedor. La atención efectiva es la parte de ese contexto que el modelo utiliza con suficiente fidelidad para resolver tu tarea. Si cargas 700 archivos, duplicas definiciones y mezclas instrucciones con datos irrelevantes, tu ventana sigue siendo de 1M tokens, pero la atención efectiva baja.
Por eso, el contexto largo DeepSeek funciona mejor cuando lo tratas como un espacio de trabajo estructurado. Primero van las reglas estables. Después, el material de referencia. Al final, la tarea concreta y los criterios de salida. Ese orden suele reducir ambigüedad y mejora la recuperación interna del modelo, sobre todo en peticiones largas.

Qué puedes meter en 1M tokens: casos de uso que sí tienen sentido
No todas las tareas mejoran solo por aumentar contexto. Las que más partido sacan a 1M tokens suelen compartir un rasgo: necesitan relacionar piezas dispersas sin perder continuidad. Estos son los escenarios donde más valor aporta.
1) Repositorios grandes y auditoría de código
Puedes cargar arquitectura, módulos clave, pruebas, configuración y documentación interna en una misma petición. Eso permite pedir análisis cruzados: detectar inconsistencias entre interfaces y uso real, localizar deuda técnica repetida o proponer un plan de migración con impacto por carpetas. No conviene incluir binarios, archivos generados, dependencias vendorizadas ni logs masivos. Solo añaden ruido.
Un patrón útil consiste en pasar primero un índice del repositorio, luego los archivos críticos y al final la tarea. Si necesitas refactorizar autenticación, no metas todo el monorepo “por si acaso”. Incluye el árbol, los módulos de identidad, los adaptadores, los tests y la configuración relacionada. El resto puede entrar mediante recuperación selectiva.
2) Lotes de documentos y análisis comparativo
Otra aplicación clara es comparar políticas, propuestas comerciales, informes jurídicos o especificaciones técnicas. En vez de resumir cada documento por separado, puedes pedir una matriz de diferencias, conflictos, vacíos y cláusulas incompatibles. Ese tipo de tarea depende mucho del contexto conjunto, no de una lectura aislada.
3) Sesiones largas con memoria operativa
En flujos de producto, soporte técnico o investigación, una ventana amplia reduce la necesidad de reinyectar contexto en cada turno. Puedes mantener decisiones previas, restricciones, listas de tareas, extractos de reuniones y criterios de validación dentro de la misma conversación durante más tiempo. Eso no elimina la necesidad de resumir de vez en cuando, pero sí retrasa el punto en que la conversación se degrada.
4) Extracción estructurada sobre material extenso
Si combinas una entrada larga con salida en JSON, DeepSeek V4 puede extraer entidades, incidencias, dependencias o decisiones desde un conjunto grande de fuentes. Tiene sentido cuando la estructura final es clara y repetible: tablas de obligaciones, inventarios de APIs, listas de requisitos o catálogos de riesgos.[1]
5) Planificación sobre contexto mixto
También puedes unir documentación, código, conversaciones previas y objetivos de negocio para pedir un plan accionable. Este uso destaca con DeepSeek V4 Pro, que soporta modo de razonamiento y control de esfuerzo, incluido max en las rutas compatibles.[3]
Qué no conviene hacer aunque “quepa” en 1M tokens
El error más común es asumir que más contexto siempre mejora el resultado. No es así. Hay varias situaciones donde una ventana enorme empeora la calidad o encarece el trabajo sin beneficio real.
- Volcar un repositorio entero sin filtrar. Archivos generados, dependencias externas y duplicados diluyen la señal.
- Usar contexto largo como sustituto de RAG. Si solo necesitas 20 fragmentos relevantes, recupera esos 20. No cargues 5.000 páginas.
- Mezclar instrucciones y datos sin jerarquía. Si la tarea queda enterrada al final, el modelo tenderá a priorizar mal.
- Pedir precisión de cita sin anclar fuentes. Si no numeras documentos o secciones, la verificación posterior será más costosa.
- Repetir el mismo prefijo en cada llamada sin caché. Eso multiplica el coste y el tiempo de procesamiento.[5]
- Esperar salida ilimitada. La salida máxima publicada para V4 es 384K tokens; planifica compresión, paginación o respuestas por fases.[1]
Otra trampa frecuente es confundir capacidad de lectura con capacidad de razonamiento exhaustivo sobre todo el conjunto. Si tu tarea exige rastrear 2.000 dependencias con trazabilidad exacta, conviene dividir: primero índice, después recuperación dirigida y, por último, síntesis. Esa estrategia suele ser más fiable que una sola solicitud gigante.
Cómo aprovechar bien el contexto largo DeepSeek
La mejor forma de utilizar una ventana de 1M tokens no es llenar el máximo, sino diseñar la entrada. Este flujo funciona bien en equipos técnicos y reduce errores frecuentes.
- Define el objetivo con una salida cerrada. Antes de adjuntar material, especifica qué esperas: tabla comparativa, plan de migración, lista priorizada, JSON o parche.
- Ordena el contexto por capas. Instrucciones del sistema, reglas de tarea, índice del material, fragmentos principales y consulta final.
- Elimina ruido antes de enviar. Borra duplicados, activos generados, conversaciones irrelevantes y texto repetido.
- Etiqueta las fuentes. Usa prefijos simples como
[DOC-12],[FILE-auth.ts]o[MEETING-03]para facilitar referencias. - Combina contexto largo con recuperación. Reserva el espacio grande para el marco estable. Inyecta dinámicamente solo lo que cambia.
- Reutiliza prefijos con caché. Si el bloque de contexto base se repite, el caché de contexto reduce de forma notable el coste de entrada.[1][5]
- Divide la salida compleja. Si esperas una respuesta muy larga, pide primero esquema y luego desarrolla por secciones.
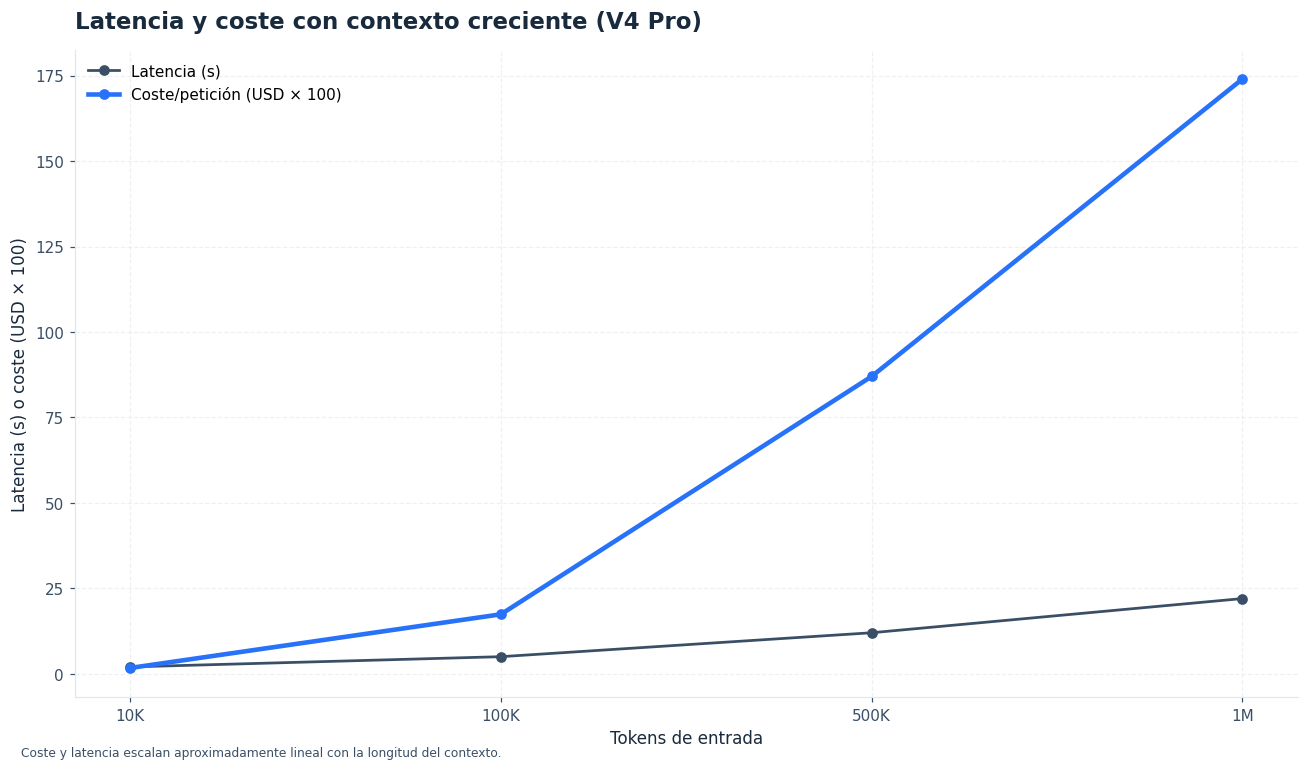
En cuanto al modelo, DeepSeek V4 Flash encaja cuando necesitas volumen, baja latencia y coste ajustado. DeepSeek V4 Pro compensa mejor en tareas de planificación, síntesis compleja o razonamiento con múltiples restricciones. Los precios publicados por DeepSeek son, por 1M tokens, $0,14 de entrada y $0,28 de salida en V4 Flash; $1,74 de entrada y $3,48 de salida en V4 Pro. Con caché, la entrada baja a $0,028 en Flash y $0,145 en Pro.[1]
Las tarifas pueden cambiar; verifica los importes vigentes en la página de planes y precios antes de presupuestar una integración.
| Modelo | Contexto | Salida máx. | Entrada | Entrada con caché | Salida |
|---|---|---|---|---|---|
| DeepSeek V4 Flash | 1M tokens | 384K tokens | $0,14 / 1M | $0,028 / 1M | $0,28 / 1M |
| DeepSeek V4 Pro | 1M tokens | 384K tokens | $1,74 / 1M | $0,145 / 1M | $3,48 / 1M |
| DeepSeek V3.2 (heredado) | 128K tokens | 4K por defecto | $0,28 / 1M | — | $0,42 / 1M |
Si sigues usando los alias heredados, ten en cuenta dos fechas. Primero, deepseek-chat y deepseek-reasoner fueron actualizados a DeepSeek V3.2 en diciembre de 2025. Segundo, DeepSeek indica que ambos alias se discontinuarán el 24 de julio de 2026; durante el periodo de transición apuntan a los modos sin razonamiento y con razonamiento de deepseek-v4-flash, respectivamente.[2][6]
Ejemplo trabajado: analizar una base de código grande sin gastar de más
Supón que quieres revisar una aplicación SaaS con varios servicios, panel web, API y colas asíncronas. El objetivo no es “explica el repositorio”, sino detectar riesgos de autorización y proponer un plan de corrección por prioridad.
- Extrae un índice del repositorio con rutas, tamaño y tipo de archivo.
- Filtra dependencias, carpetas generadas,
dist,node_modules, activos y logs. - Selecciona módulos relevantes: autenticación, autorización, middleware, políticas, tests y documentación de permisos.
- Prepara un prefijo estable con reglas: “cita archivos por nombre”, “marca incertidumbre”, “separa hallazgos confirmados de hipótesis”.
- Envía ese prefijo una vez y reutilízalo con caché para iteraciones posteriores.[5]
- Pide una primera salida corta: mapa de riesgos y archivos sospechosos.
- En una segunda llamada, amplía solo sobre los puntos confirmados.
Ese flujo aprovecha la ventana larga sin convertirla en un vertedero de texto. También permite iterar con coste controlado. Si además integras la API compatible con OpenAI y reutilizas el mismo bloque base, el ahorro por caché empieza a notarse en proyectos reales.[1][5]
curl https://api.deepseek.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-v4-flash",
"messages": [
{
"role": "system",
"content": "Analiza el repositorio. Cita siempre el archivo fuente y separa hallazgos confirmados de sospechas."
},
{
"role": "user",
"content": "Contexto: [INDEX] ... [FILE-auth.ts] ... [FILE-rbac.ts] ... [TEST-auth.spec.ts] ... Tarea: detecta riesgos de autorización y propón correcciones priorizadas."
}
],
"response_format": { "type": "text" }
}'La URL base oficial compatible con formato OpenAI es https://api.deepseek.com, y la ruta /v1 se mantiene por compatibilidad con clientes que esperan esa convención.[1][6]
Si necesitas más profundidad de razonamiento, puedes pasar a deepseek-v4-pro y activar el modo de pensamiento o ajustar el esfuerzo cuando el cliente lo soporte. En la documentación oficial, DeepSeek indica que V4 Pro admite control de esfuerzo con high y max.[3]
Preguntas frecuentes
¿1M tokens significa que el modelo entiende igual de bien todo el contexto?
No. Significa que ese volumen cabe dentro de la solicitud. La utilidad real depende del orden, la relevancia y la limpieza del contenido. Si el material importante queda enterrado entre duplicados y ruido, la calidad baja aunque sigas dentro del límite técnico.
¿Cuándo conviene DeepSeek V4 Flash y cuándo DeepSeek V4 Pro?
Flash suele ser la mejor opción para exploración amplia, lotes grandes, automatizaciones y análisis iterativo con coste bajo. Pro compensa cuando la tarea exige síntesis compleja, planificación o razonamiento más intenso. Ambos comparten 1M tokens de contexto; la diferencia principal está en calidad, modos de razonamiento y precio.[1][3]
¿Puedo sustituir un sistema RAG por una ventana de 1M tokens?
No por completo. Una ventana grande reduce fricción, pero RAG sigue siendo útil para seleccionar solo lo relevante, mantener las fuentes frescas y bajar costes. La combinación más sólida suele ser contexto base estable más recuperación selectiva.
¿Qué pasa con deepseek-chat y deepseek-reasoner?
Siguen disponibles por compatibilidad, pero DeepSeek anunció su discontinuación para el 24 de julio de 2026. Durante la transición apuntan a los modos sin razonamiento y con razonamiento de DeepSeek V4 Flash. Si estás integrando hoy, conviene migrar ya a deepseek-v4-flash o deepseek-v4-pro.[2][6]
¿Los modelos de DeepSeek V4 tienen pesos abiertos?
Sí. En el lanzamiento de V4, DeepSeek indicó que los pesos abiertos se publican bajo licencia MIT.[4]
¿Cómo reduzco coste cuando trabajo con contexto muy largo?
Hay tres medidas que suelen dar el mayor impacto: limpiar contexto antes de enviarlo, reutilizar prefijos con caché y dividir el trabajo en fases. En DeepSeek, el caché de contexto se refleja además en campos de uso específicos para medir cuántos tokens de entrada fueron aciertos de caché.[5]
Recursos relacionados
- DeepSeek en español
- precios de DeepSeek
- documentación de la API
- probar DeepSeek Chat
- guía de DeepSeek V4 Flash
- detalles de DeepSeek V4 Pro
Conclusión
El contexto largo DeepSeek abre casos de uso que antes exigían mucha fragmentación: revisar repositorios grandes, comparar documentos extensos y mantener sesiones largas sin perder continuidad. Aun así, la ventaja real no sale de llenar 1M tokens, sino de estructurarlos bien. Si vas a empezar hoy, lo más sensato es probar con DeepSeek V4 Flash para iterar barato, medir el efecto del caché y subir a DeepSeek V4 Pro cuando la tarea pida más razonamiento. La mejora llega cuando tratas el contexto como diseño, no como almacenamiento.[1][3][5]