
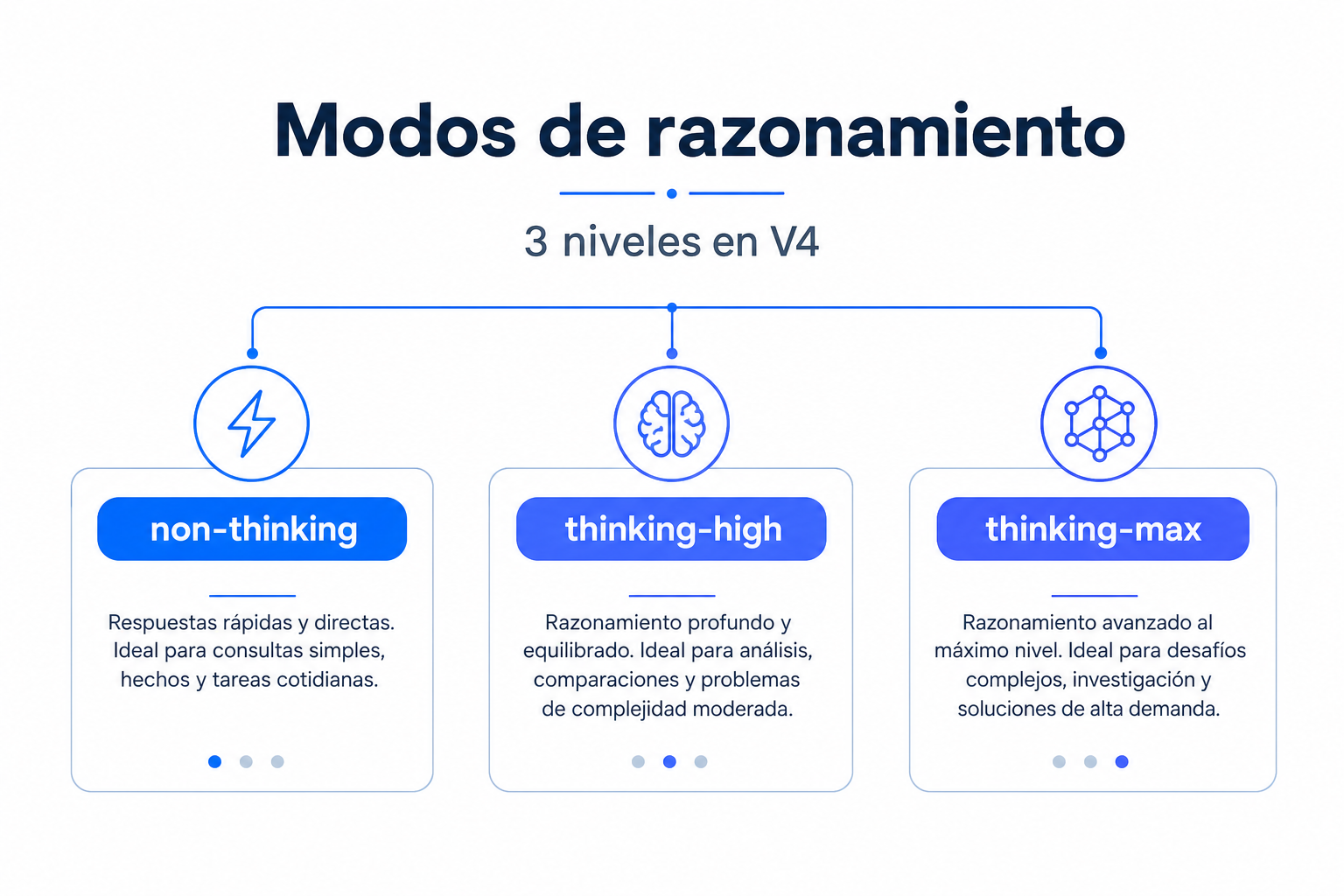
Los deepseek thinking modes son los ajustes que controlan cuánto razona DeepSeek V4 antes de responder. Elegir bien entre non-thinking, thinking-high y thinking-max cambia el coste, la latencia y la calidad final, así que conviene tratarlos como una decisión de arquitectura y no como un detalle menor.[1][2]
Resumen rápido
non-thinkingreduce latencia y uso de tokens. Encaja mejor en chat rápido, clasificación, extracción y flujos donde la respuesta debe llegar en pocos pasos.[2]thinking-highes el modo por defecto cuando el razonamiento está activado. Suele ser la opción equilibrada para análisis, programación y tareas de varios pasos.[2]thinking-maxestá disponible en DeepSeek V4 Pro y aumenta el esfuerzo de razonamiento para problemas complejos, agentes y planificación más larga.[2][3]- DeepSeek V4 Flash cuesta $0,14 por 1M tokens de entrada y $0,28 por 1M tokens de salida; DeepSeek V4 Pro cuesta $1,74 de entrada y $3,48 de salida. El cache hit de entrada baja a $0,028 en Flash y $0,145 en Pro.[1]
- Ambos modelos admiten 1M tokens de contexto y hasta 384K tokens de salida máxima, aunque no siempre conviene acercarse a ese límite por coste y tiempo de respuesta.[1]
- Los alias
deepseek-chatydeepseek-reasonerse retirarán el 24 de julio de 2026. Para proyectos nuevos, conviene usardeepseek-v4-flashodeepseek-v4-prode forma explícita.[4]
Qué son los deepseek thinking modes y qué cambia entre ellos
DeepSeek V4 expone un control directo sobre el modo de razonamiento. En formato compatible con OpenAI, puedes activar o desactivar el pensamiento con {"thinking":{"type":"enabled/disabled"}}. Si el razonamiento está activado, también puedes ajustar la intensidad con reasoning_effort.[2]
La lógica práctica queda así:
- non-thinking: razonamiento desactivado. Prioriza velocidad, menor consumo y respuestas más directas.[2]
- thinking-high: razonamiento activado con esfuerzo alto. Es el valor estándar para la mayoría de peticiones con análisis.[2]
- thinking-max: razonamiento activado con esfuerzo máximo. Se orienta a tareas más difíciles, especialmente en DeepSeek V4 Pro.[2][3]
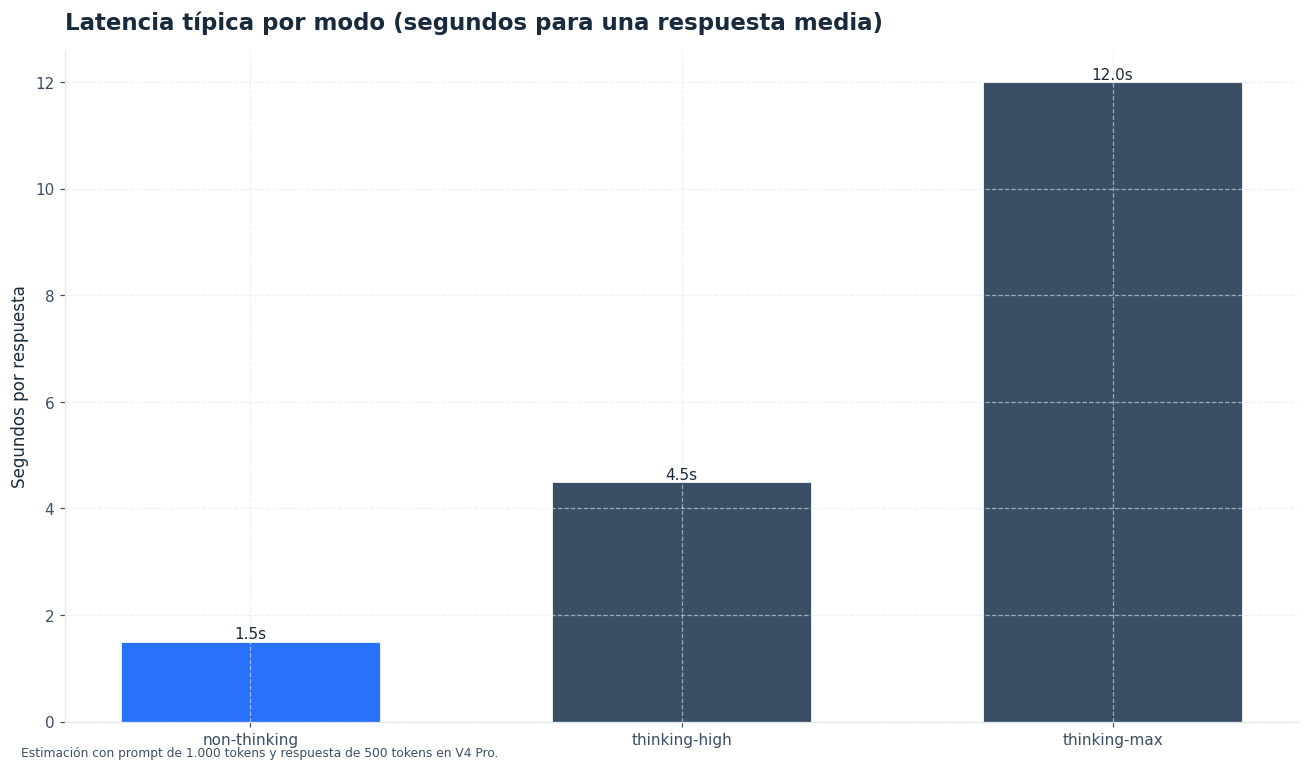
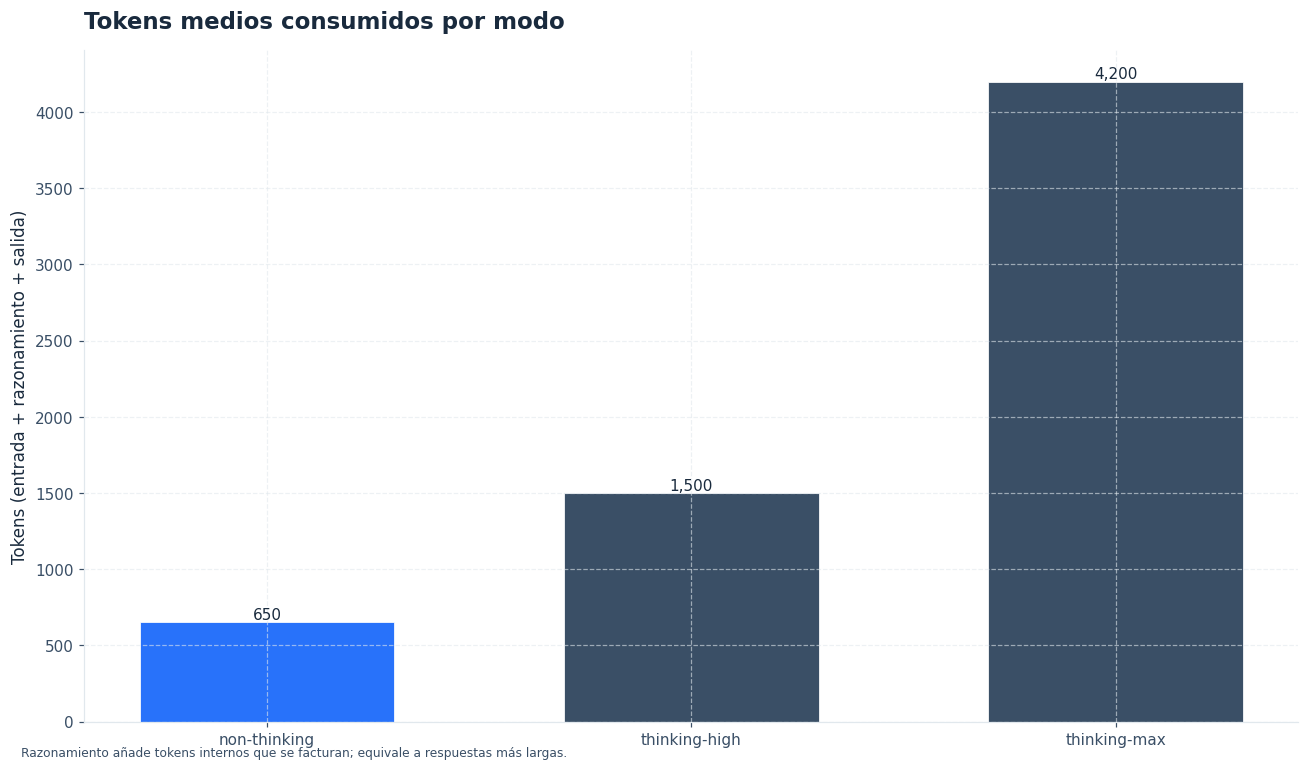
Esto no solo cambia la “profundidad” de la respuesta. También altera tres variables operativas: cuántos tokens se consumen, cuánto tarda la generación y cuánta probabilidad tienes de obtener una salida robusta en tareas con dependencias largas. En otras palabras, los deepseek thinking modes afectan a la calidad percibida y al presupuesto de inferencia al mismo tiempo.[1][2]
Además, DeepSeek V4 está disponible mediante API compatible con OpenAI en https://api.deepseek.com/v1/, mientras que la documentación de precios y modelos usa como base https://api.deepseek.com. En integraciones existentes, esto facilita migrar con pocos cambios desde clientes ya preparados para Chat Completions.[1][5]

Cuándo usar non-thinking, thinking-high y thinking-max
La forma más útil de elegir modo es partir del riesgo de error y del valor de cada respuesta. Si una salida incorrecta apenas tiene coste y necesitas volumen, usa el modo más ligero. Si cada respuesta implica código, decisiones o pasos encadenados, merece la pena subir el esfuerzo.
Usa non-thinking cuando importa más la velocidad
- Chat de soporte de baja complejidad.
- Clasificación de textos, etiquetado y moderación.
- Extracción de campos en formatos conocidos.
- Reescritura, resumen corto y transformación de estilo.
- Autocompletado o experiencias interactivas donde cada 200-500 ms cuenta.
Aquí conviene combinar DeepSeek V4 Flash con razonamiento desactivado. Flash ya parte de un coste muy bajo frente a Pro, y desactivar el pensamiento ayuda a contener aún más el uso total de tokens.[1][2]
Usa thinking-high como ajuste por defecto para trabajo serio
- Programación con instrucciones no triviales.
- Análisis de documentos con varias restricciones.
- Generación de SQL, lógica de negocio y validaciones.
- Asistentes internos con herramientas y contexto largo.
- Explicaciones técnicas que deban mantener consistencia.
Si estás entre dos modos y no tienes datos propios todavía, thinking-high suele ser el punto de partida razonable. La propia documentación indica que, cuando el pensamiento está activado, el esfuerzo por defecto es high en peticiones normales.[2]
Usa thinking-max cuando el error cuesta más que la latencia
- Agentes que planifican varios pasos.
- Resolución de problemas complejos de código.
- Razonamiento matemático o lógico con dependencia larga.
- Análisis profundo sobre grandes ventanas de contexto.
- Tareas con herramientas donde una mala decisión dispara costes posteriores.
En DeepSeek V4 Pro, thinking-max tiene sentido cuando quieres maximizar la calidad antes de pensar en optimización fina. La guía oficial indica que algunos flujos complejos de agentes pueden elevar el esfuerzo automáticamente a max.[2]
Coste, latencia y contexto: la comparación que sí afecta al despliegue
Los precios oficiales de mayo de 2026 sitúan a DeepSeek V4 Flash en $0,14 por 1M tokens de entrada, $0,028 por 1M tokens de entrada en cache hit y $0,28 por 1M tokens de salida. DeepSeek V4 Pro sube a $1,74 de entrada, $0,145 de entrada en cache hit y $3,48 de salida por 1M tokens.[1]
Las tarifas pueden cambiar; verifica los importes vigentes en la página de planes y precios antes de presupuestar una integración.
| Modelo | Modo recomendado | Entrada | Cache hit entrada | Salida | Contexto / salida máx. |
|---|---|---|---|---|---|
| DeepSeek V4 Flash | non-thinking o thinking-high | $0,14 | $0,028 | $0,28 | 1M / 384K |
| DeepSeek V4 Pro | thinking-high o thinking-max | $1,74 | $0,145 | $3,48 | 1M / 384K |
| DeepSeek V3.2 legacy | compatibilidad | $0,28 | — | $0,42 | según versión legacy |
La capa legacy sigue siendo útil para entender migraciones. La tabla oficial de precios recoge DeepSeek V3.2 con $0,28 por 1M tokens de entrada y $0,42 por 1M tokens de salida, pero la ruta recomendada para desarrollos nuevos es V4.[6][4]
La diferencia real no está solo en la tarifa por millón. Cuando pasas de non-thinking a thinking-high o thinking-max, el modelo dedica más tokens al proceso de razonamiento. En la práctica, eso incrementa el coste total por respuesta y suele elevar la latencia. Por tanto, si sirves miles de peticiones por minuto, el modo de razonamiento debe entrar en tu cálculo de unidad económica igual que el modelo elegido.[1][2]
Un criterio simple funciona bien:
- Si tu producto vive de volumen y tiempo de respuesta, empieza con Flash +
non-thinking. - Si tu producto vive de exactitud razonable, prueba Flash o Pro con
thinking-high. - Si tu producto monetiza decisiones complejas, reserva Pro +
thinking-maxpara rutas premium o tareas escaladas.
Cómo activarlos en la API paso a paso
DeepSeek expone estos controles en la API compatible con OpenAI. El cambio se hace en el cuerpo de la petición, así que puedes ajustar el modo por caso de uso, por cliente o por tipo de tarea.
Paso 1: elige modelo
Usa deepseek-v4-flash si priorizas eficiencia o deepseek-v4-pro si necesitas más capacidad en tareas complejas.[1]
Paso 2: desactiva o activa el pensamiento
Para non-thinking, define "thinking":{"type":"disabled"}. Para los modos con razonamiento, establece "thinking":{"type":"enabled"}.[2]
Paso 3: ajusta el esfuerzo
Con el pensamiento activado, emplea reasoning_effort con high o max. Según la documentación, low y medium se reasignan a high, y xhigh se reasigna a max por compatibilidad.[2]
Paso 4: mide antes de fijar el modo por defecto
No conviene decidir por intuición. Lanza un conjunto de pruebas con tus tareas reales y compara cuatro métricas: tasa de acierto, tokens de salida, latencia p95 y coste por tarea completada. Ese experimento suele dar mejores decisiones que cualquier benchmark genérico.
curl https://api.deepseek.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-v4-pro",
"messages": [
{"role": "system", "content": "Eres un asistente técnico preciso."},
{"role": "user", "content": "Analiza este error de SQL y propone una corrección mínima."}
],
"thinking": {"type": "enabled"},
"reasoning_effort": "max"
}'Si quieres el equivalente a non-thinking, cambia el bloque final por "thinking":{"type":"disabled"}. Para una configuración intermedia, mantén el pensamiento activado y usa "reasoning_effort":"high".[2][5]
Ejemplo trabajado: elegir modo en un asistente de desarrollo
Imagina un asistente para equipos de ingeniería con tres rutas: autocompletado, diagnóstico de incidencias y planificación de refactorizaciones. No tiene sentido servirlas todas con el mismo perfil.
- Autocompletado de fragmentos cortos: usa DeepSeek V4 Flash con
non-thinking. El objetivo es latencia baja y coste estable. - Diagnóstico de errores: usa DeepSeek V4 Flash o Pro con
thinking-high. Aquí el modelo debe seguir trazas, hipótesis y restricciones. - Plan de migración entre módulos: usa DeepSeek V4 Pro con
thinking-max. La tarea exige más contexto, más dependencia entre pasos y mejor priorización.
Este patrón permite asignar presupuesto allí donde genera valor. En vez de sobredimensionar todo el producto con Pro + thinking-max, escalas solo las rutas que de verdad se benefician. Para muchas aplicaciones, esa segmentación es la diferencia entre una integración sostenible y una factura difícil de defender.[1][2]
También conviene tener en cuenta la transición de nombres legacy. Si todavía dependes de deepseek-chat o deepseek-reasoner, la fecha de retirada anunciada es el 24 de julio de 2026. Migrar antes evita un cambio apresurado en producción.[4]
Preguntas frecuentes
¿DeepSeek V4 Flash y DeepSeek V4 Pro soportan los mismos modos?
Ambos soportan modo con y sin pensamiento. La documentación de precios indica que DeepSeek V4 Flash admite non-thinking y thinking, y la guía de razonamiento documenta el control de esfuerzo high/max. En la práctica, thinking-max es especialmente relevante en DeepSeek V4 Pro, que es el modelo orientado a tareas más exigentes.[1][2]
¿Cuál debería ser el modo por defecto en una aplicación nueva?
Si no tienes métricas propias, empieza con thinking-high en la ruta principal y prueba non-thinking en tareas sencillas. Cuando la precisión extra compense el coste y la latencia, sube a thinking-max solo en los flujos complejos.
¿El contexto máximo es distinto según el modo?
La tabla oficial publica 1M tokens de contexto y 384K tokens de salida máxima para DeepSeek V4 Flash y DeepSeek V4 Pro.[1] Aun así, usar ventanas enormes con razonamiento intensivo aumenta el coste total y puede penalizar el tiempo de respuesta, así que conviene resumir o recuperar contexto de forma selectiva.
¿Qué pasa con deepseek-chat y deepseek-reasoner?
Siguen existiendo por compatibilidad, pero DeepSeek anunció su retirada para el 24 de julio de 2026. Desde la actualización del 24 de abril de 2026, esos alias apuntan a los modos sin pensamiento y con pensamiento de DeepSeek V4 Flash, respectivamente.[4]
¿DeepSeek V4 mantiene compatibilidad con la API de OpenAI?
Sí. La documentación oficial indica soporte para la interfaz OpenAI Chat Completions y mantiene el acceso mediante la base de API de DeepSeek. Eso simplifica la migración desde clientes y SDK ya preparados para ese formato.[4][5]
¿Los pesos de DeepSeek son abiertos?
Sí. El anuncio de DeepSeek V4 Preview señala que los pesos abiertos se publican bajo licencia MIT, algo útil si tu evaluación incluye uso en local, investigación o comparación con despliegues gestionados.[3]
Recursos relacionados
- Portada de DeepSeek en español
- precios de DeepSeek
- documentación de la API
- guía de DeepSeek V4 Flash
- análisis de DeepSeek V4 Pro
- probar DeepSeek Chat
Conclusión
Elegir bien los deepseek thinking modes no consiste en activar siempre el máximo razonamiento. La decisión correcta depende de cuánto te cuesta fallar, cuánto puedes pagar por respuesta y qué latencia tolera tu producto. Como regla de trabajo, usa non-thinking para volumen, thinking-high para la mayoría de tareas serias y thinking-max para problemas complejos en DeepSeek V4 Pro. Si aún usas alias legacy, planifica la migración antes del 24 de julio de 2026 y valida cada modo con tus propias métricas de producción.[1][2][4]